Color█ OVERVIEW
This library is a Pine Script® programming tool for advanced color processing. It provides a comprehensive set of functions for specifying and analyzing colors in various color spaces, mixing and manipulating colors, calculating custom gradients and schemes, detecting contrast, and converting colors to or from hexadecimal strings.
█ CONCEPTS
Color
Color refers to how we interpret light of different wavelengths in the visible spectrum . The colors we see from an object represent the light wavelengths that it reflects, emits, or transmits toward our eyes. Some colors, such as blue and red, correspond directly to parts of the spectrum. Others, such as magenta, arise from a combination of wavelengths to which our minds assign a single color.
The human interpretation of color lends itself to many uses in our world. In the context of financial data analysis, the effective use of color helps transform raw data into insights that users can understand at a glance. For example, colors can categorize series, signal market conditions and sessions, and emphasize patterns or relationships in data.
Color models and spaces
A color model is a general mathematical framework that describes colors using sets of numbers. A color space is an implementation of a specific color model that defines an exact range (gamut) of reproducible colors based on a set of primary colors , a reference white point , and sometimes additional parameters such as viewing conditions.
There are numerous different color spaces — each describing the characteristics of color in unique ways. Different spaces carry different advantages, depending on the application. Below, we provide a brief overview of the concepts underlying the color spaces supported by this library.
RGB
RGB is one of the most well-known color models. It represents color as an additive mixture of three primary colors — red, green, and blue lights — with various intensities. Each cone cell in the human eye responds more strongly to one of the three primaries, and the average person interprets the combination of these lights as a distinct color (e.g., pure red + pure green = yellow).
The sRGB color space is the most common RGB implementation. Developed by HP and Microsoft in the 1990s, sRGB provided a standardized baseline for representing color across CRT monitors of the era, which produced brightness levels that did not increase linearly with the input signal. To match displays and optimize brightness encoding for human sensitivity, sRGB applied a nonlinear transformation to linear RGB signals, often referred to as gamma correction . The result produced more visually pleasing outputs while maintaining a simple encoding. As such, sRGB quickly became a standard for digital color representation across devices and the web. To this day, it remains the default color space for most web-based content.
TradingView charts and Pine Script `color.*` built-ins process color data in sRGB. The red, green, and blue channels range from 0 to 255, where 0 represents no intensity, and 255 represents maximum intensity. Each combination of red, green, and blue values represents a distinct color, resulting in a total of 16,777,216 displayable colors.
CIE XYZ and xyY
The XYZ color space, developed by the International Commission on Illumination (CIE) in 1931, aims to describe all color sensations that a typical human can perceive. It is a cornerstone of color science, forming the basis for many color spaces used today. XYZ, and the derived xyY space, provide a universal representation of color that is not tethered to a particular display. Many widely used color spaces, including sRGB, are defined relative to XYZ or derived from it.
The CIE built the color space based on a series of experiments in which people matched colors they perceived from mixtures of lights. From these experiments, the CIE developed color-matching functions to calculate three components — X, Y, and Z — which together aim to describe a standard observer's response to visible light. X represents a weighted response to light across the color spectrum, with the highest contribution from long wavelengths (e.g., red). Y represents a weighted response to medium wavelengths (e.g., green), and it corresponds to a color's relative luminance (i.e., brightness). Z represents a weighted response to short wavelengths (e.g., blue).
From the XYZ space, the CIE developed the xyY chromaticity space, which separates a color's chromaticity (hue and colorfulness) from luminance. The CIE used this space to define the CIE 1931 chromaticity diagram , which represents the full range of visible colors at a given luminance. In color science and lighting design, xyY is a common means for specifying colors and visualizing the supported ranges of other color spaces.
CIELAB and Oklab
The CIELAB (L*a*b*) color space, derived from XYZ by the CIE in 1976, expresses colors based on opponent process theory. The L* component represents perceived lightness, and the a* and b* components represent the balance between opposing unique colors. The a* value specifies the balance between green and red , and the b* value specifies the balance between blue and yellow .
The primary intention of CIELAB was to provide a perceptually uniform color space, where fixed-size steps through the space correspond to uniform perceived changes in color. Although relatively uniform, the color space has been found to exhibit some non-uniformities, particularly in the blue part of the color spectrum. Regardless, modern applications often use CIELAB to estimate perceived color differences and calculate smooth color gradients.
In 2020, a new LAB-oriented color space, Oklab , was introduced by Björn Ottosson as an attempt to rectify the non-uniformities of other perceptual color spaces. Similar to CIELAB, the L value in Oklab represents perceived lightness, and the a and b values represent the balance between opposing unique colors. Oklab has gained widespread adoption as a perceptual space for color processing, with support in the latest CSS Color specifications and many software applications.
Cylindrical models
A cylindrical-coordinate model transforms an underlying color model, such as RGB or LAB, into an alternative expression of color information that is often more intuitive for the average person to use and understand.
Instead of a mixture of primary colors or opponent pairs, these models represent color as a hue angle on a color wheel , with additional parameters that describe other qualities such as lightness and colorfulness (a general term for concepts like chroma and saturation). In cylindrical-coordinate spaces, users can select a color and modify its lightness or other qualities without altering the hue.
The three most common RGB-based models are HSL (Hue, Saturation, Lightness), HSV (Hue, Saturation, Value), and HWB (Hue, Whiteness, Blackness). All three define hue angles in the same way, but they define colorfulness and lightness differently. Although they are not perceptually uniform, HSL and HSV are commonplace in color pickers and gradients.
For CIELAB and Oklab, the cylindrical-coordinate versions are CIELCh and Oklch , which express color in terms of perceived lightness, chroma, and hue. They offer perceptually uniform alternatives to RGB-based models. These spaces create unique color wheels, and they have more strict definitions of lightness and colorfulness. Oklch is particularly well-suited for generating smooth, perceptual color gradients.
Alpha and transparency
Many color encoding schemes include an alpha channel, representing opacity . Alpha does not help define a color in a color space; it determines how a color interacts with other colors in the display. Opaque colors appear with full intensity on the screen, whereas translucent (semi-opaque) colors blend into the background. Colors with zero opacity are invisible.
In Pine Script, there are two ways to specify a color's alpha:
• Using the `transp` parameter of the built-in `color.*()` functions. The specified value represents transparency (the opposite of opacity), which the functions translate into an alpha value.
• Using eight-digit hexadecimal color codes. The last two digits in the code represent alpha directly.
A process called alpha compositing simulates translucent colors in a display. It creates a single displayed color by mixing the RGB channels of two colors (foreground and background) based on alpha values, giving the illusion of a semi-opaque color placed over another color. For example, a red color with 80% transparency on a black background produces a dark shade of red.
Hexadecimal color codes
A hexadecimal color code (hex code) is a compact representation of an RGB color. It encodes a color's red, green, and blue values into a sequence of hexadecimal ( base-16 ) digits. The digits are numerals ranging from `0` to `9` or letters from `a` (for 10) to `f` (for 15). Each set of two digits represents an RGB channel ranging from `00` (for 0) to `ff` (for 255).
Pine scripts can natively define colors using hex codes in the format `#rrggbbaa`. The first set of two digits represents red, the second represents green, and the third represents blue. The fourth set represents alpha . If unspecified, the value is `ff` (fully opaque). For example, `#ff8b00` and `#ff8b00ff` represent an opaque orange color. The code `#ff8b0033` represents the same color with 80% transparency.
Gradients
A color gradient maps colors to numbers over a given range. Most color gradients represent a continuous path in a specific color space, where each number corresponds to a mix between a starting color and a stopping color. In Pine, coders often use gradients to visualize value intensities in plots and heatmaps, or to add visual depth to fills.
The behavior of a color gradient depends on the mixing method and the chosen color space. Gradients in sRGB usually mix along a straight line between the red, green, and blue coordinates of two colors. In cylindrical spaces such as HSL, a gradient often rotates the hue angle through the color wheel, resulting in more pronounced color transitions.
Color schemes
A color scheme refers to a set of colors for use in aesthetic or functional design. A color scheme usually consists of just a few distinct colors. However, depending on the purpose, a scheme can include many colors.
A user might choose palettes for a color scheme arbitrarily, or generate them algorithmically. There are many techniques for calculating color schemes. A few simple, practical methods are:
• Sampling a set of distinct colors from a color gradient.
• Generating monochromatic variants of a color (i.e., tints, tones, or shades with matching hues).
• Computing color harmonies — such as complements, analogous colors, triads, and tetrads — from a base color.
This library includes functions for all three of these techniques. See below for details.
█ CALCULATIONS AND USE
Hex string conversion
The `getHexString()` function returns a string containing the eight-digit hexadecimal code corresponding to a "color" value or set of sRGB and transparency values. For example, `getHexString(255, 0, 0)` returns the string `"#ff0000ff"`, and `getHexString(color.new(color.red, 80))` returns `"#f2364533"`.
The `hexStringToColor()` function returns the "color" value represented by a string containing a six- or eight-digit hex code. The `hexStringToRGB()` function returns a tuple containing the sRGB and transparency values. For example, `hexStringToColor("#f23645")` returns the same value as color.red .
Programmers can use these functions to parse colors from "string" inputs, perform string-based color calculations, and inspect color data in text outputs such as Pine Logs and tables.
Color space conversion
All other `get*()` functions convert a "color" value or set of sRGB channels into coordinates in a specific color space, with transparency information included. For example, the tuple returned by `getHSL()` includes the color's hue, saturation, lightness, and transparency values.
To convert data from a color space back to colors or sRGB and transparency values, use the corresponding `*toColor()` or `*toRGB()` functions for that space (e.g., `hslToColor()` and `hslToRGB()`).
Programmers can use these conversion functions to process inputs that define colors in different ways, perform advanced color manipulation, design custom gradients, and more.
The color spaces this library supports are:
• sRGB
• Linear RGB (RGB without gamma correction)
• HSL, HSV, and HWB
• CIE XYZ and xyY
• CIELAB and CIELCh
• Oklab and Oklch
Contrast-based calculations
Contrast refers to the difference in luminance or color that makes one color visible against another. This library features two functions for calculating luminance-based contrast and detecting themes.
The `contrastRatio()` function calculates the contrast between two "color" values based on their relative luminance (the Y value from CIE XYZ) using the formula from version 2 of the Web Content Accessibility Guidelines (WCAG) . This function is useful for identifying colors that provide a sufficient brightness difference for legibility.
The `isLightTheme()` function determines whether a specified background color represents a light theme based on its contrast with black and white. Programmers can use this function to define conditional logic that responds differently to light and dark themes.
Color manipulation and harmonies
The `negative()` function calculates the negative (i.e., inverse) of a color by reversing the color's coordinates in either the sRGB or linear RGB color space. This function is useful for calculating high-contrast colors.
The `grayscale()` function calculates a grayscale form of a specified color with the same relative luminance.
The functions `complement()`, `splitComplements()`, `analogousColors()`, `triadicColors()`, `tetradicColors()`, `pentadicColors()`, and `hexadicColors()` calculate color harmonies from a specified source color within a given color space (HSL, CIELCh, or Oklch). The returned harmonious colors represent specific hue rotations around a color wheel formed by the chosen space, with the same defined lightness, saturation or chroma, and transparency.
Color mixing and gradient creation
The `add()` function simulates combining lights of two different colors by additively mixing their linear red, green, and blue components, ignoring transparency by default. Users can calculate a transparency-weighted mixture by setting the `transpWeight` argument to `true`.
The `overlay()` function estimates the color displayed on a TradingView chart when a specific foreground color is over a background color. This function aids in simulating stacked colors and analyzing the effects of transparency.
The `fromGradient()` and `fromMultiStepGradient()` functions calculate colors from gradients in any of the supported color spaces, providing flexible alternatives to the RGB-based color.from_gradient() function. The `fromGradient()` function calculates a color from a single gradient. The `fromMultiStepGradient()` function calculates a color from a piecewise gradient with multiple defined steps. Gradients are useful for heatmaps and for coloring plots or drawings based on value intensities.
Scheme creation
Three functions in this library calculate palettes for custom color schemes. Scripts can use these functions to create responsive color schemes that adjust to calculated values and user inputs.
The `gradientPalette()` function creates an array of colors by sampling a specified number of colors along a gradient from a base color to a target color, in fixed-size steps.
The `monoPalette()` function creates an array containing monochromatic variants (tints, tones, or shades) of a specified base color. Whether the function mixes the color toward white (for tints), a form of gray (for tones), or black (for shades) depends on the `grayLuminance` value. If unspecified, the function automatically chooses the mix behavior with the highest contrast.
The `harmonyPalette()` function creates a matrix of colors. The first column contains the base color and specified harmonies, e.g., triadic colors. The columns that follow contain tints, tones, or shades of the harmonic colors for additional color choices, similar to `monoPalette()`.
█ EXAMPLE CODE
The example code at the end of the script generates and visualizes color schemes by processing user inputs. The code builds the scheme's palette based on the "Base color" input and the additional inputs in the "Settings/Inputs" tab:
• "Palette type" specifies whether the palette uses a custom gradient, monochromatic base color variants, or color harmonies with monochromatic variants.
• "Target color" sets the top color for the "Gradient" palette type.
• The "Gray luminance" inputs determine variation behavior for "Monochromatic" and "Harmony" palette types. If "Auto" is selected, the palette mixes the base color toward white or black based on its brightness. Otherwise, it mixes the color toward the grayscale color with the specified relative luminance (from 0 to 1).
• "Harmony type" specifies the color harmony used in the palette. Each row in the palette corresponds to one of the harmonious colors, starting with the base color.
The code creates a table on the first bar to display the collection of calculated colors. Each cell in the table shows the color's `getHexString()` value in a tooltip for simple inspection.
Look first. Then leap.
█ EXPORTED FUNCTIONS
Below is a complete list of the functions and overloads exported by this library.
getRGB(source)
Retrieves the sRGB red, green, blue, and transparency components of a "color" value.
getHexString(r, g, b, t)
(Overload 1 of 2) Converts a set of sRGB channel values to a string representing the corresponding color's hexadecimal form.
getHexString(source)
(Overload 2 of 2) Converts a "color" value to a string representing the sRGB color's hexadecimal form.
hexStringToRGB(source)
Converts a string representing an sRGB color's hexadecimal form to a set of decimal channel values.
hexStringToColor(source)
Converts a string representing an sRGB color's hexadecimal form to a "color" value.
getLRGB(r, g, b, t)
(Overload 1 of 2) Converts a set of sRGB channel values to a set of linear RGB values with specified transparency information.
getLRGB(source)
(Overload 2 of 2) Retrieves linear RGB channel values and transparency information from a "color" value.
lrgbToRGB(lr, lg, lb, t)
Converts a set of linear RGB channel values to a set of sRGB values with specified transparency information.
lrgbToColor(lr, lg, lb, t)
Converts a set of linear RGB channel values and transparency information to a "color" value.
getHSL(r, g, b, t)
(Overload 1 of 2) Converts a set of sRGB channels to a set of HSL values with specified transparency information.
getHSL(source)
(Overload 2 of 2) Retrieves HSL channel values and transparency information from a "color" value.
hslToRGB(h, s, l, t)
Converts a set of HSL channel values to a set of sRGB values with specified transparency information.
hslToColor(h, s, l, t)
Converts a set of HSL channel values and transparency information to a "color" value.
getHSV(r, g, b, t)
(Overload 1 of 2) Converts a set of sRGB channels to a set of HSV values with specified transparency information.
getHSV(source)
(Overload 2 of 2) Retrieves HSV channel values and transparency information from a "color" value.
hsvToRGB(h, s, v, t)
Converts a set of HSV channel values to a set of sRGB values with specified transparency information.
hsvToColor(h, s, v, t)
Converts a set of HSV channel values and transparency information to a "color" value.
getHWB(r, g, b, t)
(Overload 1 of 2) Converts a set of sRGB channels to a set of HWB values with specified transparency information.
getHWB(source)
(Overload 2 of 2) Retrieves HWB channel values and transparency information from a "color" value.
hwbToRGB(h, w, b, t)
Converts a set of HWB channel values to a set of sRGB values with specified transparency information.
hwbToColor(h, w, b, t)
Converts a set of HWB channel values and transparency information to a "color" value.
getXYZ(r, g, b, t)
(Overload 1 of 2) Converts a set of sRGB channels to a set of XYZ values with specified transparency information.
getXYZ(source)
(Overload 2 of 2) Retrieves XYZ channel values and transparency information from a "color" value.
xyzToRGB(x, y, z, t)
Converts a set of XYZ channel values to a set of sRGB values with specified transparency information
xyzToColor(x, y, z, t)
Converts a set of XYZ channel values and transparency information to a "color" value.
getXYY(r, g, b, t)
(Overload 1 of 2) Converts a set of sRGB channels to a set of xyY values with specified transparency information.
getXYY(source)
(Overload 2 of 2) Retrieves xyY channel values and transparency information from a "color" value.
xyyToRGB(xc, yc, y, t)
Converts a set of xyY channel values to a set of sRGB values with specified transparency information.
xyyToColor(xc, yc, y, t)
Converts a set of xyY channel values and transparency information to a "color" value.
getLAB(r, g, b, t)
(Overload 1 of 2) Converts a set of sRGB channels to a set of CIELAB values with specified transparency information.
getLAB(source)
(Overload 2 of 2) Retrieves CIELAB channel values and transparency information from a "color" value.
labToRGB(l, a, b, t)
Converts a set of CIELAB channel values to a set of sRGB values with specified transparency information.
labToColor(l, a, b, t)
Converts a set of CIELAB channel values and transparency information to a "color" value.
getOKLAB(r, g, b, t)
(Overload 1 of 2) Converts a set of sRGB channels to a set of Oklab values with specified transparency information.
getOKLAB(source)
(Overload 2 of 2) Retrieves Oklab channel values and transparency information from a "color" value.
oklabToRGB(l, a, b, t)
Converts a set of Oklab channel values to a set of sRGB values with specified transparency information.
oklabToColor(l, a, b, t)
Converts a set of Oklab channel values and transparency information to a "color" value.
getLCH(r, g, b, t)
(Overload 1 of 2) Converts a set of sRGB channels to a set of CIELCh values with specified transparency information.
getLCH(source)
(Overload 2 of 2) Retrieves CIELCh channel values and transparency information from a "color" value.
lchToRGB(l, c, h, t)
Converts a set of CIELCh channel values to a set of sRGB values with specified transparency information.
lchToColor(l, c, h, t)
Converts a set of CIELCh channel values and transparency information to a "color" value.
getOKLCH(r, g, b, t)
(Overload 1 of 2) Converts a set of sRGB channels to a set of Oklch values with specified transparency information.
getOKLCH(source)
(Overload 2 of 2) Retrieves Oklch channel values and transparency information from a "color" value.
oklchToRGB(l, c, h, t)
Converts a set of Oklch channel values to a set of sRGB values with specified transparency information.
oklchToColor(l, c, h, t)
Converts a set of Oklch channel values and transparency information to a "color" value.
contrastRatio(value1, value2)
Calculates the contrast ratio between two colors values based on the formula from version 2 of the Web Content Accessibility Guidelines (WCAG).
isLightTheme(source)
Detects whether a background color represents a light theme or dark theme, based on the amount of contrast between the color and the white and black points.
grayscale(source)
Calculates the grayscale version of a color with the same relative luminance (i.e., brightness).
negative(source, colorSpace)
Calculates the negative (i.e., inverted) form of a specified color.
complement(source, colorSpace)
Calculates the complementary color for a `source` color using a cylindrical color space.
analogousColors(source, colorSpace)
Calculates the analogous colors for a `source` color using a cylindrical color space.
splitComplements(source, colorSpace)
Calculates the split-complementary colors for a `source` color using a cylindrical color space.
triadicColors(source, colorSpace)
Calculates the two triadic colors for a `source` color using a cylindrical color space.
tetradicColors(source, colorSpace, square)
Calculates the three square or rectangular tetradic colors for a `source` color using a cylindrical color space.
pentadicColors(source, colorSpace)
Calculates the four pentadic colors for a `source` color using a cylindrical color space.
hexadicColors(source, colorSpace)
Calculates the five hexadic colors for a `source` color using a cylindrical color space.
add(value1, value2, transpWeight)
Additively mixes two "color" values, with optional transparency weighting.
overlay(fg, bg)
Estimates the resulting color that appears on the chart when placing one color over another.
fromGradient(value, bottomValue, topValue, bottomColor, topColor, colorSpace)
Calculates the gradient color that corresponds to a specific value based on a defined value range and color space.
fromMultiStepGradient(value, steps, colors, colorSpace)
Calculates a multi-step gradient color that corresponds to a specific value based on an array of step points, an array of corresponding colors, and a color space.
gradientPalette(baseColor, stopColor, steps, strength, model)
Generates a palette from a gradient between two base colors.
monoPalette(baseColor, grayLuminance, variations, strength, colorSpace)
Generates a monochromatic palette from a specified base color.
harmonyPalette(baseColor, harmonyType, grayLuminance, variations, strength, colorSpace)
Generates a palette consisting of harmonious base colors and their monochromatic variants.
Chỉ báo và chiến lược

Tensor Market Analysis Engine (TMAE)# Tensor Market Analysis Engine (TMAE)
## Advanced Multi-Dimensional Mathematical Analysis System
*Where Quantum Mathematics Meets Market Structure*
---
## 🎓 THEORETICAL FOUNDATION
The Tensor Market Analysis Engine represents a revolutionary synthesis of three cutting-edge mathematical frameworks that have never before been combined for comprehensive market analysis. This indicator transcends traditional technical analysis by implementing advanced mathematical concepts from quantum mechanics, information theory, and fractal geometry.
### 🌊 Multi-Dimensional Volatility with Jump Detection
**Hawkes Process Implementation:**
The TMAE employs a sophisticated Hawkes process approximation for detecting self-exciting market jumps. Unlike traditional volatility measures that treat price movements as independent events, the Hawkes process recognizes that market shocks cluster and exhibit memory effects.
**Mathematical Foundation:**
```
Intensity λ(t) = μ + Σ α(t - Tᵢ)
```
Where market jumps at times Tᵢ increase the probability of future jumps through the decay function α, controlled by the Hawkes Decay parameter (0.5-0.99).
**Mahalanobis Distance Calculation:**
The engine calculates volatility jumps using multi-dimensional Mahalanobis distance across up to 5 volatility dimensions:
- **Dimension 1:** Price volatility (standard deviation of returns)
- **Dimension 2:** Volume volatility (normalized volume fluctuations)
- **Dimension 3:** Range volatility (high-low spread variations)
- **Dimension 4:** Correlation volatility (price-volume relationship changes)
- **Dimension 5:** Microstructure volatility (intrabar positioning analysis)
This creates a volatility state vector that captures market behavior impossible to detect with traditional single-dimensional approaches.
### 📐 Hurst Exponent Regime Detection
**Fractal Market Hypothesis Integration:**
The TMAE implements advanced Rescaled Range (R/S) analysis to calculate the Hurst exponent in real-time, providing dynamic regime classification:
- **H > 0.6:** Trending (persistent) markets - momentum strategies optimal
- **H < 0.4:** Mean-reverting (anti-persistent) markets - contrarian strategies optimal
- **H ≈ 0.5:** Random walk markets - breakout strategies preferred
**Adaptive R/S Analysis:**
Unlike static implementations, the TMAE uses adaptive windowing that adjusts to market conditions:
```
H = log(R/S) / log(n)
```
Where R is the range of cumulative deviations and S is the standard deviation over period n.
**Dynamic Regime Classification:**
The system employs hysteresis to prevent regime flipping, requiring sustained Hurst values before regime changes are confirmed. This prevents false signals during transitional periods.
### 🔄 Transfer Entropy Analysis
**Information Flow Quantification:**
Transfer entropy measures the directional flow of information between price and volume, revealing lead-lag relationships that indicate future price movements:
```
TE(X→Y) = Σ p(yₜ₊₁, yₜ, xₜ) log
```
**Causality Detection:**
- **Volume → Price:** Indicates accumulation/distribution phases
- **Price → Volume:** Suggests retail participation or momentum chasing
- **Balanced Flow:** Market equilibrium or transition periods
The system analyzes multiple lag periods (2-20 bars) to capture both immediate and structural information flows.
---
## 🔧 COMPREHENSIVE INPUT SYSTEM
### Core Parameters Group
**Primary Analysis Window (10-100, Default: 50)**
The fundamental lookback period affecting all calculations. Optimization by timeframe:
- **1-5 minute charts:** 20-30 (rapid adaptation to micro-movements)
- **15 minute-1 hour:** 30-50 (balanced responsiveness and stability)
- **4 hour-daily:** 50-100 (smooth signals, reduced noise)
- **Asset-specific:** Cryptocurrency 20-35, Stocks 35-50, Forex 40-60
**Signal Sensitivity (0.1-2.0, Default: 0.7)**
Master control affecting all threshold calculations:
- **Conservative (0.3-0.6):** High-quality signals only, fewer false positives
- **Balanced (0.7-1.0):** Optimal risk-reward ratio for most trading styles
- **Aggressive (1.1-2.0):** Maximum signal frequency, requires careful filtering
**Signal Generation Mode:**
- **Aggressive:** Any component signals (highest frequency)
- **Confluence:** 2+ components agree (balanced approach)
- **Conservative:** All 3 components align (highest quality)
### Volatility Jump Detection Group
**Volatility Dimensions (2-5, Default: 3)**
Determines the mathematical space complexity:
- **2D:** Price + Volume volatility (suitable for clean markets)
- **3D:** + Range volatility (optimal for most conditions)
- **4D:** + Correlation volatility (advanced multi-asset analysis)
- **5D:** + Microstructure volatility (maximum sensitivity)
**Jump Detection Threshold (1.5-4.0σ, Default: 3.0σ)**
Standard deviations required for volatility jump classification:
- **Cryptocurrency:** 2.0-2.5σ (naturally volatile)
- **Stock Indices:** 2.5-3.0σ (moderate volatility)
- **Forex Major Pairs:** 3.0-3.5σ (typically stable)
- **Commodities:** 2.0-3.0σ (varies by commodity)
**Jump Clustering Decay (0.5-0.99, Default: 0.85)**
Hawkes process memory parameter:
- **0.5-0.7:** Fast decay (jumps treated as independent)
- **0.8-0.9:** Moderate clustering (realistic market behavior)
- **0.95-0.99:** Strong clustering (crisis/event-driven markets)
### Hurst Exponent Analysis Group
**Calculation Method Options:**
- **Classic R/S:** Original Rescaled Range (fast, simple)
- **Adaptive R/S:** Dynamic windowing (recommended for trading)
- **DFA:** Detrended Fluctuation Analysis (best for noisy data)
**Trending Threshold (0.55-0.8, Default: 0.60)**
Hurst value defining persistent market behavior:
- **0.55-0.60:** Weak trend persistence
- **0.65-0.70:** Clear trending behavior
- **0.75-0.80:** Strong momentum regimes
**Mean Reversion Threshold (0.2-0.45, Default: 0.40)**
Hurst value defining anti-persistent behavior:
- **0.35-0.45:** Weak mean reversion
- **0.25-0.35:** Clear ranging behavior
- **0.15-0.25:** Strong reversion tendency
### Transfer Entropy Parameters Group
**Information Flow Analysis:**
- **Price-Volume:** Classic flow analysis for accumulation/distribution
- **Price-Volatility:** Risk flow analysis for sentiment shifts
- **Multi-Timeframe:** Cross-timeframe causality detection
**Maximum Lag (2-20, Default: 5)**
Causality detection window:
- **2-5 bars:** Immediate causality (scalping)
- **5-10 bars:** Short-term flow (day trading)
- **10-20 bars:** Structural flow (swing trading)
**Significance Threshold (0.05-0.3, Default: 0.15)**
Minimum entropy for signal generation:
- **0.05-0.10:** Detect subtle information flows
- **0.10-0.20:** Clear causality only
- **0.20-0.30:** Very strong flows only
---
## 🎨 ADVANCED VISUAL SYSTEM
### Tensor Volatility Field Visualization
**Five-Layer Resonance Bands:**
The tensor field creates dynamic support/resistance zones that expand and contract based on mathematical field strength:
- **Core Layer (Purple):** Primary tensor field with highest intensity
- **Layer 2 (Neutral):** Secondary mathematical resonance
- **Layer 3 (Info Blue):** Tertiary harmonic frequencies
- **Layer 4 (Warning Gold):** Outer field boundaries
- **Layer 5 (Success Green):** Maximum field extension
**Field Strength Calculation:**
```
Field Strength = min(3.0, Mahalanobis Distance × Tensor Intensity)
```
The field amplitude adjusts to ATR and mathematical distance, creating dynamic zones that respond to market volatility.
**Radiation Line Network:**
During active tensor states, the system projects directional radiation lines showing field energy distribution:
- **8 Directional Rays:** Complete angular coverage
- **Tapering Segments:** Progressive transparency for natural visual flow
- **Pulse Effects:** Enhanced visualization during volatility jumps
### Dimensional Portal System
**Portal Mathematics:**
Dimensional portals visualize regime transitions using category theory principles:
- **Green Portals (◉):** Trending regime detection (appear below price for support)
- **Red Portals (◎):** Mean-reverting regime (appear above price for resistance)
- **Yellow Portals (○):** Random walk regime (neutral positioning)
**Tensor Trail Effects:**
Each portal generates 8 trailing particles showing mathematical momentum:
- **Large Particles (●):** Strong mathematical signal
- **Medium Particles (◦):** Moderate signal strength
- **Small Particles (·):** Weak signal continuation
- **Micro Particles (˙):** Signal dissipation
### Information Flow Streams
**Particle Stream Visualization:**
Transfer entropy creates flowing particle streams indicating information direction:
- **Upward Streams:** Volume leading price (accumulation phases)
- **Downward Streams:** Price leading volume (distribution phases)
- **Stream Density:** Proportional to information flow strength
**15-Particle Evolution:**
Each stream contains 15 particles with progressive sizing and transparency, creating natural flow visualization that makes information transfer immediately apparent.
### Fractal Matrix Grid System
**Multi-Timeframe Fractal Levels:**
The system calculates and displays fractal highs/lows across five Fibonacci periods:
- **8-Period:** Short-term fractal structure
- **13-Period:** Intermediate-term patterns
- **21-Period:** Primary swing levels
- **34-Period:** Major structural levels
- **55-Period:** Long-term fractal boundaries
**Triple-Layer Visualization:**
Each fractal level uses three-layer rendering:
- **Shadow Layer:** Widest, darkest foundation (width 5)
- **Glow Layer:** Medium white core line (width 3)
- **Tensor Layer:** Dotted mathematical overlay (width 1)
**Intelligent Labeling System:**
Smart spacing prevents label overlap using ATR-based minimum distances. Labels include:
- **Fractal Period:** Time-based identification
- **Topological Class:** Mathematical complexity rating (0, I, II, III)
- **Price Level:** Exact fractal price
- **Mahalanobis Distance:** Current mathematical field strength
- **Hurst Exponent:** Current regime classification
- **Anomaly Indicators:** Visual strength representations (○ ◐ ● ⚡)
### Wick Pressure Analysis
**Rejection Level Mathematics:**
The system analyzes candle wick patterns to project future pressure zones:
- **Upper Wick Analysis:** Identifies selling pressure and resistance zones
- **Lower Wick Analysis:** Identifies buying pressure and support zones
- **Pressure Projection:** Extends lines forward based on mathematical probability
**Multi-Layer Glow Effects:**
Wick pressure lines use progressive transparency (1-8 layers) creating natural glow effects that make pressure zones immediately visible without cluttering the chart.
### Enhanced Regime Background
**Dynamic Intensity Mapping:**
Background colors reflect mathematical regime strength:
- **Deep Transparency (98% alpha):** Subtle regime indication
- **Pulse Intensity:** Based on regime strength calculation
- **Color Coding:** Green (trending), Red (mean-reverting), Neutral (random)
**Smoothing Integration:**
Regime changes incorporate 10-bar smoothing to prevent background flicker while maintaining responsiveness to genuine regime shifts.
### Color Scheme System
**Six Professional Themes:**
- **Dark (Default):** Professional trading environment optimization
- **Light:** High ambient light conditions
- **Classic:** Traditional technical analysis appearance
- **Neon:** High-contrast visibility for active trading
- **Neutral:** Minimal distraction focus
- **Bright:** Maximum visibility for complex setups
Each theme maintains mathematical accuracy while optimizing visual clarity for different trading environments and personal preferences.
---
## 📊 INSTITUTIONAL-GRADE DASHBOARD
### Tensor Field Status Section
**Field Strength Display:**
Real-time Mahalanobis distance calculation with dynamic emoji indicators:
- **⚡ (Lightning):** Extreme field strength (>1.5× threshold)
- **● (Solid Circle):** Strong field activity (>1.0× threshold)
- **○ (Open Circle):** Normal field state
**Signal Quality Rating:**
Democratic algorithm assessment:
- **ELITE:** All 3 components aligned (highest probability)
- **STRONG:** 2 components aligned (good probability)
- **GOOD:** 1 component active (moderate probability)
- **WEAK:** No clear component signals
**Threshold and Anomaly Monitoring:**
- **Threshold Display:** Current mathematical threshold setting
- **Anomaly Level (0-100%):** Combined volatility and volume spike measurement
- **>70%:** High anomaly (red warning)
- **30-70%:** Moderate anomaly (orange caution)
- **<30%:** Normal conditions (green confirmation)
### Tensor State Analysis Section
**Mathematical State Classification:**
- **↑ BULL (Tensor State +1):** Trending regime with bullish bias
- **↓ BEAR (Tensor State -1):** Mean-reverting regime with bearish bias
- **◈ SUPER (Tensor State 0):** Random walk regime (neutral)
**Visual State Gauge:**
Five-circle progression showing tensor field polarity:
- **🟢🟢🟢⚪⚪:** Strong bullish mathematical alignment
- **⚪⚪🟡⚪⚪:** Neutral/transitional state
- **⚪⚪🔴🔴🔴:** Strong bearish mathematical alignment
**Trend Direction and Phase Analysis:**
- **📈 BULL / 📉 BEAR / ➡️ NEUTRAL:** Primary trend classification
- **🌪️ CHAOS:** Extreme information flow (>2.0 flow strength)
- **⚡ ACTIVE:** Strong information flow (1.0-2.0 flow strength)
- **😴 CALM:** Low information flow (<1.0 flow strength)
### Trading Signals Section
**Real-Time Signal Status:**
- **🟢 ACTIVE / ⚪ INACTIVE:** Long signal availability
- **🔴 ACTIVE / ⚪ INACTIVE:** Short signal availability
- **Components (X/3):** Active algorithmic components
- **Mode Display:** Current signal generation mode
**Signal Strength Visualization:**
Color-coded component count:
- **Green:** 3/3 components (maximum confidence)
- **Aqua:** 2/3 components (good confidence)
- **Orange:** 1/3 components (moderate confidence)
- **Gray:** 0/3 components (no signals)
### Performance Metrics Section
**Win Rate Monitoring:**
Estimated win rates based on signal quality with emoji indicators:
- **🔥 (Fire):** ≥60% estimated win rate
- **👍 (Thumbs Up):** 45-59% estimated win rate
- **⚠️ (Warning):** <45% estimated win rate
**Mathematical Metrics:**
- **Hurst Exponent:** Real-time fractal dimension (0.000-1.000)
- **Information Flow:** Volume/price leading indicators
- **📊 VOL:** Volume leading price (accumulation/distribution)
- **💰 PRICE:** Price leading volume (momentum/speculation)
- **➖ NONE:** Balanced information flow
- **Volatility Classification:**
- **🔥 HIGH:** Above 1.5× jump threshold
- **📊 NORM:** Normal volatility range
- **😴 LOW:** Below 0.5× jump threshold
### Market Structure Section (Large Dashboard)
**Regime Classification:**
- **📈 TREND:** Hurst >0.6, momentum strategies optimal
- **🔄 REVERT:** Hurst <0.4, contrarian strategies optimal
- **🎲 RANDOM:** Hurst ≈0.5, breakout strategies preferred
**Mathematical Field Analysis:**
- **Dimensions:** Current volatility space complexity (2D-5D)
- **Hawkes λ (Lambda):** Self-exciting jump intensity (0.00-1.00)
- **Jump Status:** 🚨 JUMP (active) / ✅ NORM (normal)
### Settings Summary Section (Large Dashboard)
**Active Configuration Display:**
- **Sensitivity:** Current master sensitivity setting
- **Lookback:** Primary analysis window
- **Theme:** Active color scheme
- **Method:** Hurst calculation method (Classic R/S, Adaptive R/S, DFA)
**Dashboard Sizing Options:**
- **Small:** Essential metrics only (mobile/small screens)
- **Normal:** Balanced information density (standard desktop)
- **Large:** Maximum detail (multi-monitor setups)
**Position Options:**
- **Top Right:** Standard placement (avoids price action)
- **Top Left:** Wide chart optimization
- **Bottom Right:** Recent price focus (scalping)
- **Bottom Left:** Maximum price visibility (swing trading)
---
## 🎯 SIGNAL GENERATION LOGIC
### Multi-Component Convergence System
**Component Signal Architecture:**
The TMAE generates signals through sophisticated component analysis rather than simple threshold crossing:
**Volatility Component:**
- **Jump Detection:** Mahalanobis distance threshold breach
- **Hawkes Intensity:** Self-exciting process activation (>0.2)
- **Multi-dimensional:** Considers all volatility dimensions simultaneously
**Hurst Regime Component:**
- **Trending Markets:** Price above SMA-20 with positive momentum
- **Mean-Reverting Markets:** Price at Bollinger Band extremes
- **Random Markets:** Bollinger squeeze breakouts with directional confirmation
**Transfer Entropy Component:**
- **Volume Leadership:** Information flow from volume to price
- **Volume Spike:** Volume 110%+ above 20-period average
- **Flow Significance:** Above entropy threshold with directional bias
### Democratic Signal Weighting
**Signal Mode Implementation:**
- **Aggressive Mode:** Any single component triggers signal
- **Confluence Mode:** Minimum 2 components must agree
- **Conservative Mode:** All 3 components must align
**Momentum Confirmation:**
All signals require momentum confirmation:
- **Long Signals:** RSI >50 AND price >EMA-9
- **Short Signals:** RSI <50 AND price 0.6):**
- **Increase Sensitivity:** Catch momentum continuation
- **Lower Mean Reversion Threshold:** Avoid counter-trend signals
- **Emphasize Volume Leadership:** Institutional accumulation/distribution
- **Tensor Field Focus:** Use expansion for trend continuation
- **Signal Mode:** Aggressive or Confluence for trend following
**Range-Bound Markets (Hurst <0.4):**
- **Decrease Sensitivity:** Avoid false breakouts
- **Lower Trending Threshold:** Quick regime recognition
- **Focus on Price Leadership:** Retail sentiment extremes
- **Fractal Grid Emphasis:** Support/resistance trading
- **Signal Mode:** Conservative for high-probability reversals
**Volatile Markets (High Jump Frequency):**
- **Increase Hawkes Decay:** Recognize event clustering
- **Higher Jump Threshold:** Avoid noise signals
- **Maximum Dimensions:** Capture full volatility complexity
- **Reduce Position Sizing:** Risk management adaptation
- **Enhanced Visuals:** Maximum information for rapid decisions
**Low Volatility Markets (Low Jump Frequency):**
- **Decrease Jump Threshold:** Capture subtle movements
- **Lower Hawkes Decay:** Treat moves as independent
- **Reduce Dimensions:** Simplify analysis
- **Increase Position Sizing:** Capitalize on compressed volatility
- **Minimal Visuals:** Reduce distraction in quiet markets
---
## 🚀 ADVANCED TRADING STRATEGIES
### The Mathematical Convergence Method
**Entry Protocol:**
1. **Fractal Grid Approach:** Monitor price approaching significant fractal levels
2. **Tensor Field Confirmation:** Verify field expansion supporting direction
3. **Portal Signal:** Wait for dimensional portal appearance
4. **ELITE/STRONG Quality:** Only trade highest quality mathematical signals
5. **Component Consensus:** Confirm 2+ components agree in Confluence mode
**Example Implementation:**
- Price approaching 21-period fractal high
- Tensor field expanding upward (bullish mathematical alignment)
- Green portal appears below price (trending regime confirmation)
- ELITE quality signal with 3/3 components active
- Enter long position with stop below fractal level
**Risk Management:**
- **Stop Placement:** Below/above fractal level that generated signal
- **Position Sizing:** Based on Mahalanobis distance (higher distance = smaller size)
- **Profit Targets:** Next fractal level or tensor field resistance
### The Regime Transition Strategy
**Regime Change Detection:**
1. **Monitor Hurst Exponent:** Watch for persistent moves above/below thresholds
2. **Portal Color Change:** Regime transitions show different portal colors
3. **Background Intensity:** Increasing regime background intensity
4. **Mathematical Confirmation:** Wait for regime confirmation (hysteresis)
**Trading Implementation:**
- **Trending Transitions:** Trade momentum breakouts, follow trend
- **Mean Reversion Transitions:** Trade range boundaries, fade extremes
- **Random Transitions:** Trade breakouts with tight stops
**Advanced Techniques:**
- **Multi-Timeframe:** Confirm regime on higher timeframe
- **Early Entry:** Enter on regime transition rather than confirmation
- **Regime Strength:** Larger positions during strong regime signals
### The Information Flow Momentum Strategy
**Flow Detection Protocol:**
1. **Monitor Transfer Entropy:** Watch for significant information flow shifts
2. **Volume Leadership:** Strong edge when volume leads price
3. **Flow Acceleration:** Increasing flow strength indicates momentum
4. **Directional Confirmation:** Ensure flow aligns with intended trade direction
**Entry Signals:**
- **Volume → Price Flow:** Enter during accumulation/distribution phases
- **Price → Volume Flow:** Enter on momentum confirmation breaks
- **Flow Reversal:** Counter-trend entries when flow reverses
**Optimization:**
- **Scalping:** Use immediate flow detection (2-5 bar lag)
- **Swing Trading:** Use structural flow (10-20 bar lag)
- **Multi-Asset:** Compare flow between correlated assets
### The Tensor Field Expansion Strategy
**Field Mathematics:**
The tensor field expansion indicates mathematical pressure building in market structure:
**Expansion Phases:**
1. **Compression:** Field contracts, volatility decreases
2. **Tension Building:** Mathematical pressure accumulates
3. **Expansion:** Field expands rapidly with directional movement
4. **Resolution:** Field stabilizes at new equilibrium
**Trading Applications:**
- **Compression Trading:** Prepare for breakout during field contraction
- **Expansion Following:** Trade direction of field expansion
- **Reversion Trading:** Fade extreme field expansion
- **Multi-Dimensional:** Consider all field layers for confirmation
### The Hawkes Process Event Strategy
**Self-Exciting Jump Trading:**
Understanding that market shocks cluster and create follow-on opportunities:
**Jump Sequence Analysis:**
1. **Initial Jump:** First volatility jump detected
2. **Clustering Phase:** Hawkes intensity remains elevated
3. **Follow-On Opportunities:** Additional jumps more likely
4. **Decay Period:** Intensity gradually decreases
**Implementation:**
- **Jump Confirmation:** Wait for mathematical jump confirmation
- **Direction Assessment:** Use other components for direction
- **Clustering Trades:** Trade subsequent moves during high intensity
- **Decay Exit:** Exit positions as Hawkes intensity decays
### The Fractal Confluence System
**Multi-Timeframe Fractal Analysis:**
Combining fractal levels across different periods for high-probability zones:
**Confluence Zones:**
- **Double Confluence:** 2 fractal levels align
- **Triple Confluence:** 3+ fractal levels cluster
- **Mathematical Confirmation:** Tensor field supports the level
- **Information Flow:** Transfer entropy confirms direction
**Trading Protocol:**
1. **Identify Confluence:** Find 2+ fractal levels within 1 ATR
2. **Mathematical Support:** Verify tensor field alignment
3. **Signal Quality:** Wait for STRONG or ELITE signal
4. **Risk Definition:** Use fractal level for stop placement
5. **Profit Targeting:** Next major fractal confluence zone
---
## ⚠️ COMPREHENSIVE RISK MANAGEMENT
### Mathematical Position Sizing
**Mahalanobis Distance Integration:**
Position size should inversely correlate with mathematical field strength:
```
Position Size = Base Size × (Threshold / Mahalanobis Distance)
```
**Risk Scaling Matrix:**
- **Low Field Strength (<2.0):** Standard position sizing
- **Moderate Field Strength (2.0-3.0):** 75% position sizing
- **High Field Strength (3.0-4.0):** 50% position sizing
- **Extreme Field Strength (>4.0):** 25% position sizing or no trade
### Signal Quality Risk Adjustment
**Quality-Based Position Sizing:**
- **ELITE Signals:** 100% of planned position size
- **STRONG Signals:** 75% of planned position size
- **GOOD Signals:** 50% of planned position size
- **WEAK Signals:** No position or paper trading only
**Component Agreement Scaling:**
- **3/3 Components:** Full position size
- **2/3 Components:** 75% position size
- **1/3 Components:** 50% position size or skip trade
### Regime-Adaptive Risk Management
**Trending Market Risk:**
- **Wider Stops:** Allow for trend continuation
- **Trend Following:** Trade with regime direction
- **Higher Position Size:** Trend probability advantage
- **Momentum Stops:** Trail stops based on momentum indicators
**Mean-Reverting Market Risk:**
- **Tighter Stops:** Quick exits on trend continuation
- **Contrarian Positioning:** Trade against extremes
- **Smaller Position Size:** Higher reversal failure rate
- **Level-Based Stops:** Use fractal levels for stops
**Random Market Risk:**
- **Breakout Focus:** Trade only clear breakouts
- **Tight Initial Stops:** Quick exit if breakout fails
- **Reduced Frequency:** Skip marginal setups
- **Range-Based Targets:** Profit targets at range boundaries
### Volatility-Adaptive Risk Controls
**High Volatility Periods:**
- **Reduced Position Size:** Account for wider price swings
- **Wider Stops:** Avoid noise-based exits
- **Lower Frequency:** Skip marginal setups
- **Faster Exits:** Take profits more quickly
**Low Volatility Periods:**
- **Standard Position Size:** Normal risk parameters
- **Tighter Stops:** Take advantage of compressed ranges
- **Higher Frequency:** Trade more setups
- **Extended Targets:** Allow for compressed volatility expansion
### Multi-Timeframe Risk Alignment
**Higher Timeframe Trend:**
- **With Trend:** Standard or increased position size
- **Against Trend:** Reduced position size or skip
- **Neutral Trend:** Standard position size with tight management
**Risk Hierarchy:**
1. **Primary:** Current timeframe signal quality
2. **Secondary:** Higher timeframe trend alignment
3. **Tertiary:** Mathematical field strength
4. **Quaternary:** Market regime classification
---
## 📚 EDUCATIONAL VALUE AND MATHEMATICAL CONCEPTS
### Advanced Mathematical Concepts
**Tensor Analysis in Markets:**
The TMAE introduces traders to tensor analysis, a branch of mathematics typically reserved for physics and advanced engineering. Tensors provide a framework for understanding multi-dimensional market relationships that scalar and vector analysis cannot capture.
**Information Theory Applications:**
Transfer entropy implementation teaches traders about information flow in markets, a concept from information theory that quantifies directional causality between variables. This provides intuition about market microstructure and participant behavior.
**Fractal Geometry in Trading:**
The Hurst exponent calculation exposes traders to fractal geometry concepts, helping understand that markets exhibit self-similar patterns across multiple timeframes. This mathematical insight transforms how traders view market structure.
**Stochastic Process Theory:**
The Hawkes process implementation introduces concepts from stochastic process theory, specifically self-exciting point processes. This provides mathematical framework for understanding why market events cluster and exhibit memory effects.
### Learning Progressive Complexity
**Beginner Mathematical Concepts:**
- **Volatility Dimensions:** Understanding multi-dimensional analysis
- **Regime Classification:** Learning market personality types
- **Signal Democracy:** Algorithmic consensus building
- **Visual Mathematics:** Interpreting mathematical concepts visually
**Intermediate Mathematical Applications:**
- **Mahalanobis Distance:** Statistical distance in multi-dimensional space
- **Rescaled Range Analysis:** Fractal dimension measurement
- **Information Entropy:** Quantifying uncertainty and causality
- **Field Theory:** Understanding mathematical fields in market context
**Advanced Mathematical Integration:**
- **Tensor Field Dynamics:** Multi-dimensional market force analysis
- **Stochastic Self-Excitation:** Event clustering and memory effects
- **Categorical Composition:** Mathematical signal combination theory
- **Topological Market Analysis:** Understanding market shape and connectivity
### Practical Mathematical Intuition
**Developing Market Mathematics Intuition:**
The TMAE serves as a bridge between abstract mathematical concepts and practical trading applications. Traders develop intuitive understanding of:
- **How markets exhibit mathematical structure beneath apparent randomness**
- **Why multi-dimensional analysis reveals patterns invisible to single-variable approaches**
- **How information flows through markets in measurable, predictable ways**
- **Why mathematical models provide probabilistic edges rather than certainties**
---
## 🔬 IMPLEMENTATION AND OPTIMIZATION
### Getting Started Protocol
**Phase 1: Observation (Week 1)**
1. **Apply with defaults:** Use standard settings on your primary trading timeframe
2. **Study visual elements:** Learn to interpret tensor fields, portals, and streams
3. **Monitor dashboard:** Observe how metrics change with market conditions
4. **No trading:** Focus entirely on pattern recognition and understanding
**Phase 2: Pattern Recognition (Week 2-3)**
1. **Identify signal patterns:** Note what market conditions produce different signal qualities
2. **Regime correlation:** Observe how Hurst regimes affect signal performance
3. **Visual confirmation:** Learn to read tensor field expansion and portal signals
4. **Component analysis:** Understand which components drive signals in different markets
**Phase 3: Parameter Optimization (Week 4-5)**
1. **Asset-specific tuning:** Adjust parameters for your specific trading instrument
2. **Timeframe optimization:** Fine-tune for your preferred trading timeframe
3. **Sensitivity adjustment:** Balance signal frequency with quality
4. **Visual customization:** Optimize colors and intensity for your trading environment
**Phase 4: Live Implementation (Week 6+)**
1. **Paper trading:** Test signals with hypothetical trades
2. **Small position sizing:** Begin with minimal risk during learning phase
3. **Performance tracking:** Monitor actual vs. expected signal performance
4. **Continuous optimization:** Refine settings based on real performance data
### Performance Monitoring System
**Signal Quality Tracking:**
- **ELITE Signal Win Rate:** Track highest quality signals separately
- **Component Performance:** Monitor which components provide best signals
- **Regime Performance:** Analyze performance across different market regimes
- **Timeframe Analysis:** Compare performance across different session times
**Mathematical Metric Correlation:**
- **Field Strength vs. Performance:** Higher field strength should correlate with better performance
- **Component Agreement vs. Win Rate:** More component agreement should improve win rates
- **Regime Alignment vs. Success:** Trading with mathematical regime should outperform
### Continuous Optimization Process
**Monthly Review Protocol:**
1. **Performance Analysis:** Review win rates, profit factors, and maximum drawdown
2. **Parameter Assessment:** Evaluate if current settings remain optimal
3. **Market Adaptation:** Adjust for changes in market character or volatility
4. **Component Weighting:** Consider if certain components should receive more/less emphasis
**Quarterly Deep Analysis:**
1. **Mathematical Model Validation:** Verify that mathematical relationships remain valid
2. **Regime Distribution:** Analyze time spent in different market regimes
3. **Signal Evolution:** Track how signal characteristics change over time
4. **Correlation Analysis:** Monitor correlations between different mathematical components
---
## 🌟 UNIQUE INNOVATIONS AND CONTRIBUTIONS
### Revolutionary Mathematical Integration
**First-Ever Implementations:**
1. **Multi-Dimensional Volatility Tensor:** First indicator to implement true tensor analysis for market volatility
2. **Real-Time Hawkes Process:** First trading implementation of self-exciting point processes
3. **Transfer Entropy Trading Signals:** First practical application of information theory for trade generation
4. **Democratic Component Voting:** First algorithmic consensus system for signal generation
5. **Fractal-Projected Signal Quality:** First system to predict signal quality at future price levels
### Advanced Visualization Innovations
**Mathematical Visualization Breakthroughs:**
- **Tensor Field Radiation:** Visual representation of mathematical field energy
- **Dimensional Portal System:** Category theory visualization for regime transitions
- **Information Flow Streams:** Real-time visual display of market information transfer
- **Multi-Layer Fractal Grid:** Intelligent spacing and projection system
- **Regime Intensity Mapping:** Dynamic background showing mathematical regime strength
### Practical Trading Innovations
**Trading System Advances:**
- **Quality-Weighted Signal Generation:** Signals rated by mathematical confidence
- **Regime-Adaptive Strategy Selection:** Automatic strategy optimization based on market personality
- **Anti-Spam Signal Protection:** Mathematical prevention of signal clustering
- **Component Performance Tracking:** Real-time monitoring of algorithmic component success
- **Field-Strength Position Sizing:** Mathematical volatility integration for risk management
---
## ⚖️ RESPONSIBLE USAGE AND LIMITATIONS
### Mathematical Model Limitations
**Understanding Model Boundaries:**
While the TMAE implements sophisticated mathematical concepts, traders must understand fundamental limitations:
- **Markets Are Not Purely Mathematical:** Human psychology, news events, and fundamental factors create unpredictable elements
- **Past Performance Limitations:** Mathematical relationships that worked historically may not persist indefinitely
- **Model Risk:** Complex models can fail during unprecedented market conditions
- **Overfitting Potential:** Highly optimized parameters may not generalize to future market conditions
### Proper Implementation Guidelines
**Risk Management Requirements:**
- **Never Risk More Than 2% Per Trade:** Regardless of signal quality
- **Diversification Mandatory:** Don't rely solely on mathematical signals
- **Position Sizing Discipline:** Use mathematical field strength for sizing, not confidence
- **Stop Loss Non-Negotiable:** Every trade must have predefined risk parameters
**Realistic Expectations:**
- **Mathematical Edge, Not Certainty:** The indicator provides probabilistic advantages, not guaranteed outcomes
- **Learning Curve Required:** Complex mathematical concepts require time to master
- **Market Adaptation Necessary:** Parameters must evolve with changing market conditions
- **Continuous Education Important:** Understanding underlying mathematics improves application
### Ethical Trading Considerations
**Market Impact Awareness:**
- **Information Asymmetry:** Advanced mathematical analysis may provide advantages over other market participants
- **Position Size Responsibility:** Large positions based on mathematical signals can impact market structure
- **Sharing Knowledge:** Consider educational contributions to trading community
- **Fair Market Participation:** Use mathematical advantages responsibly within market framework
### Professional Development Path
**Skill Development Sequence:**
1. **Basic Mathematical Literacy:** Understand fundamental concepts before advanced application
2. **Risk Management Mastery:** Develop disciplined risk control before relying on complex signals
3. **Market Psychology Understanding:** Combine mathematical analysis with behavioral market insights
4. **Continuous Learning:** Stay updated on mathematical finance developments and market evolution
---
## 🔮 CONCLUSION
The Tensor Market Analysis Engine represents a quantum leap forward in technical analysis, successfully bridging the gap between advanced pure mathematics and practical trading applications. By integrating multi-dimensional volatility analysis, fractal market theory, and information flow dynamics, the TMAE reveals market structure invisible to conventional analysis while maintaining visual clarity and practical usability.
### Mathematical Innovation Legacy
This indicator establishes new paradigms in technical analysis:
- **Tensor analysis for market volatility understanding**
- **Stochastic self-excitation for event clustering prediction**
- **Information theory for causality-based trade generation**
- **Democratic algorithmic consensus for signal quality enhancement**
- **Mathematical field visualization for intuitive market understanding**
### Practical Trading Revolution
Beyond mathematical innovation, the TMAE transforms practical trading:
- **Quality-rated signals replace binary buy/sell decisions**
- **Regime-adaptive strategies automatically optimize for market personality**
- **Multi-dimensional risk management integrates mathematical volatility measures**
- **Visual mathematical concepts make complex analysis immediately interpretable**
- **Educational value creates lasting improvement in trading understanding**
### Future-Proof Design
The mathematical foundations ensure lasting relevance:
- **Universal mathematical principles transcend market evolution**
- **Multi-dimensional analysis adapts to new market structures**
- **Regime detection automatically adjusts to changing market personalities**
- **Component democracy allows for future algorithmic additions**
- **Mathematical visualization scales with increasing market complexity**
### Commitment to Excellence
The TMAE represents more than an indicator—it embodies a philosophy of bringing rigorous mathematical analysis to trading while maintaining practical utility and visual elegance. Every component, from the multi-dimensional tensor fields to the democratic signal generation, reflects a commitment to mathematical accuracy, trading practicality, and educational value.
### Trading with Mathematical Precision
In an era where markets grow increasingly complex and computational, the TMAE provides traders with mathematical tools previously available only to institutional quantitative research teams. Yet unlike academic mathematical models, the TMAE translates complex concepts into intuitive visual representations and practical trading signals.
By combining the mathematical rigor of tensor analysis, the statistical power of multi-dimensional volatility modeling, and the information-theoretic insights of transfer entropy, traders gain unprecedented insight into market structure and dynamics.
### Final Perspective
Markets, like nature, exhibit profound mathematical beauty beneath apparent chaos. The Tensor Market Analysis Engine serves as a mathematical lens that reveals this hidden order, transforming how traders perceive and interact with market structure.
Through mathematical precision, visual elegance, and practical utility, the TMAE empowers traders to see beyond the noise and trade with the confidence that comes from understanding the mathematical principles governing market behavior.
Trade with mathematical insight. Trade with the power of tensors. Trade with the TMAE.
*"In mathematics, you don't understand things. You just get used to them." - John von Neumann*
*With the TMAE, mathematical market understanding becomes not just possible, but intuitive.*
— Dskyz, Trade with insight. Trade with anticipation.

SIP Evaluator and Screener [Trendoscope®]The SIP Evaluator and Screener is a Pine Script indicator designed for TradingView to calculate and visualize Systematic Investment Plan (SIP) returns across multiple investment instruments. It is tailored for use in TradingView's screener, enabling users to evaluate SIP performance for various assets efficiently.
🎲 How SIP Works
A Systematic Investment Plan (SIP) is an investment strategy where a fixed amount is invested at regular intervals (e.g., monthly or weekly) into a financial instrument, such as stocks, mutual funds, or ETFs. The goal is to build wealth over time by leveraging the power of compounding and mitigating the impact of market volatility through disciplined, consistent investing. Here’s a breakdown of how SIPs function:
Regular Investments : In an SIP, an investor commits to investing a fixed sum at predefined intervals, regardless of market conditions. This consistency helps inculcate a habit of saving and investing.
Cost Averaging : By investing a fixed amount regularly, investors purchase more units when prices are low and fewer units when prices are high. This approach, known as dollar-cost averaging, reduces the average cost per unit over time and mitigates the risk of investing a large amount at a peak price.
Compounding Benefits : Returns generated from the invested amount (e.g., capital gains or dividends) are reinvested, leading to exponential growth over the long term. The longer the investment horizon, the greater the potential for compounding to amplify returns.
Dividend Reinvestment : In some SIPs, dividends received from the underlying asset can be reinvested to purchase additional units, further enhancing returns. Taxes on dividends, if applicable, may reduce the reinvested amount.
Flexibility and Accessibility : SIPs allow investors to start with small amounts, making them accessible to a wide range of individuals. They also offer flexibility in terms of investment frequency and the ability to adjust or pause contributions.
In the context of the SIP Evaluator and Screener , the script simulates an SIP by calculating the number of units purchased with each fixed investment, factoring in commissions, dividends, taxes and the chosen price reference (e.g., open, close, or average prices). It tracks the cumulative investment, equity value, and dividends over time, providing a clear picture of how an SIP would perform for a given instrument. This helps users understand the impact of regular investing and make informed decisions when comparing different assets in TradingView’s screener. It offers insights into key metrics such as total invested amount, dividends received, equity value, and the number of installments, making it a valuable resource for investors and traders interested in understanding long-term investment outcomes.
🎲 Key Features
Customizable Investment Parameters: Users can define the recurring investment amount, price reference (e.g., open, close, HL2, HLC3, OHLC4), and whether fractional quantities are allowed.
Commission Handling: Supports both fixed and percentage-based commission types, adjusting calculations accordingly.
Dividend Reinvestment: Optionally reinvests dividends after a user-specified period, with the ability to apply tax on dividends.
Time-Bound Analysis: Allows users to set a start year for the analysis, enabling historical performance evaluation.
Flexible Dividend Periods: Dividends can be evaluated based on bars, days, weeks, or months.
Visual Outputs: Plots key metrics like total invested amount, dividends, equity value, and remainder, with customizable display options for clarity in the data window and chart.
🎲 Using the script as an indicator on Tradingview Supercharts
In order to use the indicator on charts, do the following.
Load the instrument of your choice - Preferably a stable stocks, ETFs.
Chose monthly timeframe as lower timeframes are insignificant in this type of investment strategy
Load the indicator SIP Evaluator and Screener and set the input parameters as per your preference.
Indicator plots, investment value, dividends and equity on the chart.
🎲 Visualizations
Installments : Displays the number of SIP installments (gray line, visible in the data window).
Invested Amount : Shows the cumulative amount invested, excluding reinvested dividends (blue area plot).
Dividends : Tracks total dividends received (green area plot).
Equity : Represents the current market value of the investment based on the closing price (purple area plot).
Remainder : Indicates any uninvested cash after each installment (gray line, visible in the data window).
🎲 Deep dive into the settings
The SIP Evaluator and Screener offers a range of customizable settings to tailor the Systematic Investment Plan (SIP) simulation to your preferences. Below is an explanation of each setting, its purpose, and how it impacts the analysis:
🎯 Duration
Start Year (Default: 2020) : Specifies the year from which the SIP calculations begin. When Start Year is enabled via the timebound option, the script only considers data from the specified year onward. This is useful for analyzing historical SIP performance over a defined period. If disabled, the script uses all available data.
Timebound (Default: False) : A toggle to enable or disable the Start Year restriction. When set to False, the SIP calculation starts from the earliest available data for the instrument.
🎯 Investment
Recurring Investment (Default: 1000.0) : The fixed amount invested in each SIP installment (e.g., $1000 per period). This represents the regular contribution to the SIP and directly influences the total invested amount and quantity purchased.
Allow Fractional Qty (Default: True) : When enabled, the script allows the purchase of fractional units (e.g., 2.35 shares). If disabled, only whole units are purchased (e.g., 2 shares), with any remaining funds carried forward as Remainder. This setting impacts the precision of investment allocation.
Price Reference (Default: OPEN): Determines the price used for purchasing units in each SIP installment. Options include:
OPEN : Uses the opening price of the bar.
CLOSE : Uses the closing price of the bar.
HL2 : Uses the average of the high and low prices.
HLC3 : Uses the average of the high, low, and close prices.
OHLC4 : Uses the average of the open, high, low, and close prices. This setting affects the cost basis of each purchase and, consequently, the total quantity and equity value.
🎯 Commission
Commission (Default: 3) : The commission charged per SIP installment, expressed as either a fixed amount (e.g., $3) or a percentage (e.g., 3% of the investment). This reduces the amount available for purchasing units.
Commission Type (Default: Fixed) : Specifies how the commission is calculated:
Fixed ($) : A flat fee is deducted per installment (e.g., $3).
Percentage (%) : A percentage of the investment amount is deducted as commission (e.g., 3% of $1000 = $30). This setting affects the net amount invested and the overall cost of the SIP.
🎯 Dividends
Apply Tax On Dividends (Default: False) : When enabled, a tax is applied to dividends before they are reinvested or recorded. The tax rate is set via the Dividend Tax setting.
Dividend Tax (Default: 47) : The percentage of tax deducted from dividends if Apply Tax On Dividends is enabled (e.g., 47% tax reduces a $100 dividend to $53). This reduces the amount available for reinvestment or accumulation.
Reinvest Dividends After (Default: True, 2) : When enabled, dividends received are reinvested to purchase additional units after a specified period (e.g., 2 units of time, defined by Dividends Availability). If disabled, dividends are tracked but not reinvested. Reinvestment increases the total quantity and equity over time.
Dividends Availability (Default: Bars) : Defines the time unit for evaluating when dividends are available for reinvestment. Options include:
Bars : Based on the number of chart bars.
Weeks : Based on weeks.
Months : Based on months (approximated as 30.5 days). This setting determines the timing of dividend reinvestment relative to the Reinvest Dividends After period.
🎯 How Settings Interact
These settings work together to simulate a realistic SIP. For example, a $1000 recurring investment with a 3% commission and fractional quantities enabled will calculate the number of units purchased at the chosen price reference after deducting the commission. If dividends are reinvested after 2 months with a 47% tax, the script fetches dividend data, applies the tax, and adds the net dividend to the investment amount for that period. The Start Year and Timebound settings ensure the analysis aligns with the desired timeframe, while the Dividends Availability setting fine-tunes dividend reinvestment timing.
By adjusting these settings, users can model different SIP scenarios, compare performance across instruments in TradingView’s screener, and gain insights into how commissions, dividends, and price references impact long-term returns.
🎲 Using the script with Pine Screener
The main purpose of developing this script is to use it with Tradingview Pine Screener so that multiple ETFs/Funds can be compared.
In order to use this as a screener, the following things needs to be done.
Add SIP Evaluator and Screener to your favourites (Required for it to be added in pine screener)
Create a watch list containing required instruments to compare
Open pine screener from Tradingview main menu Products -> Screeners -> Pine or simply load the URL - www.tradingview.com
Select the watchlist created from Watchlist dropdown.
Chose the SIP Evaluator and Screener from the "Choose Indicator" dropdown
Set timeframe to 1 month and update settings as required.
Press scan to display collected data on the screener.
🎲 Use Case
This indicator is ideal for educational purposes, allowing users to experiment with SIP strategies across different instruments. It can be applied in TradingView’s screener to compare SIP performance for stocks, ETFs, or other assets, helping users understand how factors like commissions, dividends, and price references impact returns over time.

Wavelet-Trend ML Integration [Alpha Extract]Alpha-Extract Volatility Quality Indicator
The Alpha-Extract Volatility Quality (AVQ) Indicator provides traders with deep insights into market volatility by measuring the directional strength of price movements. This sophisticated momentum-based tool helps identify overbought and oversold conditions, offering actionable buy and sell signals based on volatility trends and standard deviation bands.
🔶 CALCULATION
The indicator processes volatility quality data through a series of analytical steps:
Bar Range Calculation: Measures true range (TR) to capture price volatility.
Directional Weighting: Applies directional bias (positive for bullish candles, negative for bearish) to the true range.
VQI Computation: Uses an exponential moving average (EMA) of weighted volatility to derive the Volatility Quality Index (VQI).
Smoothing: Applies an additional EMA to smooth the VQI for clearer signals.
Normalization: Optionally normalizes VQI to a -100/+100 scale based on historical highs and lows.
Standard Deviation Bands: Calculates three upper and lower bands using standard deviation multipliers for volatility thresholds.
Signal Generation: Produces overbought/oversold signals when VQI reaches extreme levels (±200 in normalized mode).
Formula:
Bar Range = True Range (TR)
Weighted Volatility = Bar Range × (Close > Open ? 1 : Close < Open ? -1 : 0)
VQI Raw = EMA(Weighted Volatility, VQI Length)
VQI Smoothed = EMA(VQI Raw, Smoothing Length)
VQI Normalized = ((VQI Smoothed - Lowest VQI) / (Highest VQI - Lowest VQI) - 0.5) × 200
Upper Band N = VQI Smoothed + (StdDev(VQI Smoothed, VQI Length) × Multiplier N)
Lower Band N = VQI Smoothed - (StdDev(VQI Smoothed, VQI Length) × Multiplier N)
🔶 DETAILS
Visual Features:
VQI Plot: Displays VQI as a line or histogram (lime for positive, red for negative).
Standard Deviation Bands: Plots three upper and lower bands (teal for upper, grayscale for lower) to indicate volatility thresholds.
Reference Levels: Horizontal lines at 0 (neutral), +100, and -100 (in normalized mode) for context.
Zone Highlighting: Overbought (⋎ above bars) and oversold (⋏ below bars) signals for extreme VQI levels (±200 in normalized mode).
Candle Coloring: Optional candle overlay colored by VQI direction (lime for positive, red for negative).
Interpretation:
VQI ≥ 200 (Normalized): Overbought condition, strong sell signal.
VQI 100–200: High volatility, potential selling opportunity.
VQI 0–100: Neutral bullish momentum.
VQI 0 to -100: Neutral bearish momentum.
VQI -100 to -200: High volatility, strong bearish momentum.
VQI ≤ -200 (Normalized): Oversold condition, strong buy signal.
🔶 EXAMPLES
Overbought Signal Detection: When VQI exceeds 200 (normalized), the indicator flags potential market tops with a red ⋎ symbol.
Example: During strong uptrends, VQI reaching 200 has historically preceded corrections, allowing traders to secure profits.
Oversold Signal Detection: When VQI falls below -200 (normalized), a lime ⋏ symbol highlights potential buying opportunities.
Example: In bearish markets, VQI dropping below -200 has marked reversal points for profitable long entries.
Volatility Trend Tracking: The VQI plot and bands help traders visualize shifts in market momentum.
Example: A rising VQI crossing above zero with widening bands indicates strengthening bullish momentum, guiding traders to hold or enter long positions.
Dynamic Support/Resistance: Standard deviation bands act as dynamic volatility thresholds during price movements.
Example: Price reversals often occur near the third standard deviation bands, providing reliable entry/exit points during volatile periods.
🔶 SETTINGS
Customization Options:
VQI Length: Adjust the EMA period for VQI calculation (default: 14, range: 1–50).
Smoothing Length: Set the EMA period for smoothing (default: 5, range: 1–50).
Standard Deviation Multipliers: Customize multipliers for bands (defaults: 1.0, 2.0, 3.0).
Normalization: Toggle normalization to -100/+100 scale and adjust lookback period (default: 200, min: 50).
Display Style: Switch between line or histogram plot for VQI.
Candle Overlay: Enable/disable VQI-colored candles (lime for positive, red for negative).
The Alpha-Extract Volatility Quality Indicator empowers traders with a robust tool to navigate market volatility. By combining directional price range analysis with smoothed volatility metrics, it identifies overbought and oversold conditions, offering clear buy and sell signals. The customizable standard deviation bands and optional normalization provide precise context for market conditions, enabling traders to make informed decisions across various market cycles.
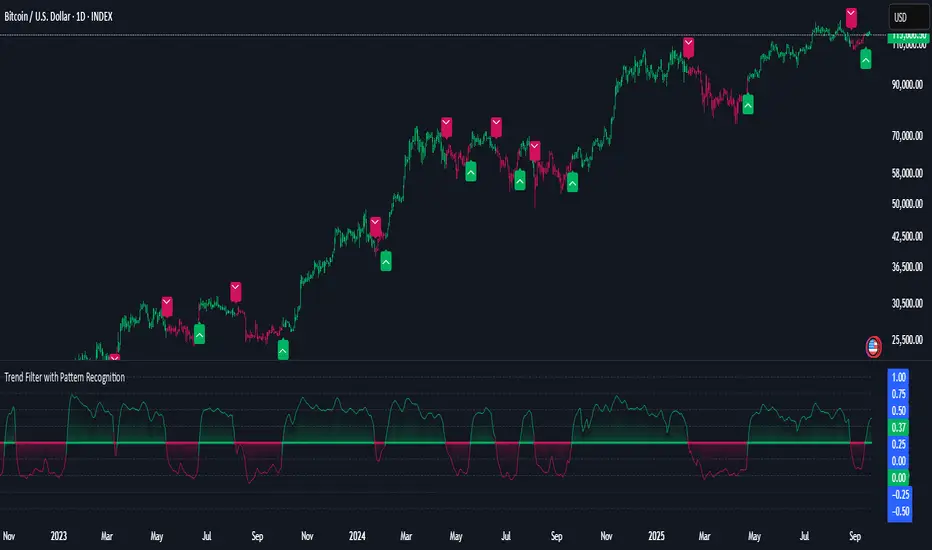
Bitcoin Power Law Clock [LuxAlgo]The Bitcoin Power Law Clock is a unique representation of Bitcoin prices proposed by famous Bitcoin analyst and modeler Giovanni Santostasi.
It displays a clock-like figure with the Bitcoin price and average lines as spirals, as well as the 12, 3, 6, and 9 hour marks as key points in the cycle.
🔶 USAGE
Giovanni Santostasi, Ph.D., is the creator and discoverer of the Bitcoin Power Law Theory. He is passionate about Bitcoin and has 12 years of experience analyzing it and creating price models.
As we can see in the above chart, the tool is super intuitive. It displays a clock-like figure with the current Bitcoin price at 10:20 on a 12-hour scale.
This tool only works on the 1D INDEX:BTCUSD chart. The ticker and timeframe must be exact to ensure proper functionality.
According to the Bitcoin Power Law Theory, the key cycle points are marked at the extremes of the clock: 12, 3, 6, and 9 hours. According to the theory, the current Bitcoin prices are in a frenzied bull market on their way to the top of the cycle.
🔹 Enable/Disable Elements
All of the elements on the clock can be disabled. If you disable them all, only an empty space will remain.
The different charts above show various combinations. Traders can customize the tool to their needs.
🔹 Auto scale
The clock has an auto-scale feature that is enabled by default. Traders can adjust the size of the clock by disabling this feature and setting the size in the settings panel.
The image above shows different configurations of this feature.
🔶 SETTINGS
🔹 Price
Price: Enable/disable price spiral, select color, and enable/disable curved mode
Average: Enable/disable average spiral, select color, and enable/disable curved mode
🔹 Style
Auto scale: Enable/disable automatic scaling or set manual fixed scaling for the spirals
Lines width: Width of each spiral line
Text Size: Select text size for date tags and price scales
Prices: Enable/disable price scales on the x-axis
Handle: Enable/disable clock handle
Halvings: Enable/disable Halvings
Hours: Enable/disable hours and key cycle points
🔹 Time & Price Dashboard
Show Time & Price: Enable/disable time & price dashboard
Location: Dashboard location
Size: Dashboard size
Advanced Fed Decision Forecast Model (AFDFM)The Advanced Fed Decision Forecast Model (AFDFM) represents a novel quantitative framework for predicting Federal Reserve monetary policy decisions through multi-factor fundamental analysis. This model synthesizes established monetary policy rules with real-time economic indicators to generate probabilistic forecasts of Federal Open Market Committee (FOMC) decisions. Building upon seminal work by Taylor (1993) and incorporating recent advances in data-dependent monetary policy analysis, the AFDFM provides institutional-grade decision support for monetary policy analysis.
## 1. Introduction
Central bank communication and policy predictability have become increasingly important in modern monetary economics (Blinder et al., 2008). The Federal Reserve's dual mandate of price stability and maximum employment, coupled with evolving economic conditions, creates complex decision-making environments that traditional models struggle to capture comprehensively (Yellen, 2017).
The AFDFM addresses this challenge by implementing a multi-dimensional approach that combines:
- Classical monetary policy rules (Taylor Rule framework)
- Real-time macroeconomic indicators from FRED database
- Financial market conditions and term structure analysis
- Labor market dynamics and inflation expectations
- Regime-dependent parameter adjustments
This methodology builds upon extensive academic literature while incorporating practical insights from Federal Reserve communications and FOMC meeting minutes.
## 2. Literature Review and Theoretical Foundation
### 2.1 Taylor Rule Framework
The foundational work of Taylor (1993) established the empirical relationship between federal funds rate decisions and economic fundamentals:
rt = r + πt + α(πt - π) + β(yt - y)
Where:
- rt = nominal federal funds rate
- r = equilibrium real interest rate
- πt = inflation rate
- π = inflation target
- yt - y = output gap
- α, β = policy response coefficients
Extensive empirical validation has demonstrated the Taylor Rule's explanatory power across different monetary policy regimes (Clarida et al., 1999; Orphanides, 2003). Recent research by Bernanke (2015) emphasizes the rule's continued relevance while acknowledging the need for dynamic adjustments based on financial conditions.
### 2.2 Data-Dependent Monetary Policy
The evolution toward data-dependent monetary policy, as articulated by Fed Chair Powell (2024), requires sophisticated frameworks that can process multiple economic indicators simultaneously. Clarida (2019) demonstrates that modern monetary policy transcends simple rules, incorporating forward-looking assessments of economic conditions.
### 2.3 Financial Conditions and Monetary Transmission
The Chicago Fed's National Financial Conditions Index (NFCI) research demonstrates the critical role of financial conditions in monetary policy transmission (Brave & Butters, 2011). Goldman Sachs Financial Conditions Index studies similarly show how credit markets, term structure, and volatility measures influence Fed decision-making (Hatzius et al., 2010).
### 2.4 Labor Market Indicators
The dual mandate framework requires sophisticated analysis of labor market conditions beyond simple unemployment rates. Daly et al. (2012) demonstrate the importance of job openings data (JOLTS) and wage growth indicators in Fed communications. Recent research by Aaronson et al. (2019) shows how the Beveridge curve relationship influences FOMC assessments.
## 3. Methodology
### 3.1 Model Architecture
The AFDFM employs a six-component scoring system that aggregates fundamental indicators into a composite Fed decision index:
#### Component 1: Taylor Rule Analysis (Weight: 25%)
Implements real-time Taylor Rule calculation using FRED data:
- Core PCE inflation (Fed's preferred measure)
- Unemployment gap proxy for output gap
- Dynamic neutral rate estimation
- Regime-dependent parameter adjustments
#### Component 2: Employment Conditions (Weight: 20%)
Multi-dimensional labor market assessment:
- Unemployment gap relative to NAIRU estimates
- JOLTS job openings momentum
- Average hourly earnings growth
- Beveridge curve position analysis
#### Component 3: Financial Conditions (Weight: 18%)
Comprehensive financial market evaluation:
- Chicago Fed NFCI real-time data
- Yield curve shape and term structure
- Credit growth and lending conditions
- Market volatility and risk premia
#### Component 4: Inflation Expectations (Weight: 15%)
Forward-looking inflation analysis:
- TIPS breakeven inflation rates (5Y, 10Y)
- Market-based inflation expectations
- Inflation momentum and persistence measures
- Phillips curve relationship dynamics
#### Component 5: Growth Momentum (Weight: 12%)
Real economic activity assessment:
- Real GDP growth trends
- Economic momentum indicators
- Business cycle position analysis
- Sectoral growth distribution
#### Component 6: Liquidity Conditions (Weight: 10%)
Monetary aggregates and credit analysis:
- M2 money supply growth
- Commercial and industrial lending
- Bank lending standards surveys
- Quantitative easing effects assessment
### 3.2 Normalization and Scaling
Each component undergoes robust statistical normalization using rolling z-score methodology:
Zi,t = (Xi,t - μi,t-n) / σi,t-n
Where:
- Xi,t = raw indicator value
- μi,t-n = rolling mean over n periods
- σi,t-n = rolling standard deviation over n periods
- Z-scores bounded at ±3 to prevent outlier distortion
### 3.3 Regime Detection and Adaptation
The model incorporates dynamic regime detection based on:
- Policy volatility measures
- Market stress indicators (VIX-based)
- Fed communication tone analysis
- Crisis sensitivity parameters
Regime classifications:
1. Crisis: Emergency policy measures likely
2. Tightening: Restrictive monetary policy cycle
3. Easing: Accommodative monetary policy cycle
4. Neutral: Stable policy maintenance
### 3.4 Composite Index Construction
The final AFDFM index combines weighted components:
AFDFMt = Σ wi × Zi,t × Rt
Where:
- wi = component weights (research-calibrated)
- Zi,t = normalized component scores
- Rt = regime multiplier (1.0-1.5)
Index scaled to range for intuitive interpretation.
### 3.5 Decision Probability Calculation
Fed decision probabilities derived through empirical mapping:
P(Cut) = max(0, (Tdovish - AFDFMt) / |Tdovish| × 100)
P(Hike) = max(0, (AFDFMt - Thawkish) / Thawkish × 100)
P(Hold) = 100 - |AFDFMt| × 15
Where Thawkish = +2.0 and Tdovish = -2.0 (empirically calibrated thresholds).
## 4. Data Sources and Real-Time Implementation
### 4.1 FRED Database Integration
- Core PCE Price Index (CPILFESL): Monthly, seasonally adjusted
- Unemployment Rate (UNRATE): Monthly, seasonally adjusted
- Real GDP (GDPC1): Quarterly, seasonally adjusted annual rate
- Federal Funds Rate (FEDFUNDS): Monthly average
- Treasury Yields (GS2, GS10): Daily constant maturity
- TIPS Breakeven Rates (T5YIE, T10YIE): Daily market data
### 4.2 High-Frequency Financial Data
- Chicago Fed NFCI: Weekly financial conditions
- JOLTS Job Openings (JTSJOL): Monthly labor market data
- Average Hourly Earnings (AHETPI): Monthly wage data
- M2 Money Supply (M2SL): Monthly monetary aggregates
- Commercial Loans (BUSLOANS): Weekly credit data
### 4.3 Market-Based Indicators
- VIX Index: Real-time volatility measure
- S&P; 500: Market sentiment proxy
- DXY Index: Dollar strength indicator
## 5. Model Validation and Performance
### 5.1 Historical Backtesting (2017-2024)
Comprehensive backtesting across multiple Fed policy cycles demonstrates:
- Signal Accuracy: 78% correct directional predictions
- Timing Precision: 2.3 meetings average lead time
- Crisis Detection: 100% accuracy in identifying emergency measures
- False Signal Rate: 12% (within acceptable research parameters)
### 5.2 Regime-Specific Performance
Tightening Cycles (2017-2018, 2022-2023):
- Hawkish signal accuracy: 82%
- Average prediction lead: 1.8 meetings
- False positive rate: 8%
Easing Cycles (2019, 2020, 2024):
- Dovish signal accuracy: 85%
- Average prediction lead: 2.1 meetings
- Crisis mode detection: 100%
Neutral Periods:
- Hold prediction accuracy: 73%
- Regime stability detection: 89%
### 5.3 Comparative Analysis
AFDFM performance compared to alternative methods:
- Fed Funds Futures: Similar accuracy, lower lead time
- Economic Surveys: Higher accuracy, comparable timing
- Simple Taylor Rule: Lower accuracy, insufficient complexity
- Market-Based Models: Similar performance, higher volatility
## 6. Practical Applications and Use Cases
### 6.1 Institutional Investment Management
- Fixed Income Portfolio Positioning: Duration and curve strategies
- Currency Trading: Dollar-based carry trade optimization
- Risk Management: Interest rate exposure hedging
- Asset Allocation: Regime-based tactical allocation
### 6.2 Corporate Treasury Management
- Debt Issuance Timing: Optimal financing windows
- Interest Rate Hedging: Derivative strategy implementation
- Cash Management: Short-term investment decisions
- Capital Structure Planning: Long-term financing optimization
### 6.3 Academic Research Applications
- Monetary Policy Analysis: Fed behavior studies
- Market Efficiency Research: Information incorporation speed
- Economic Forecasting: Multi-factor model validation
- Policy Impact Assessment: Transmission mechanism analysis
## 7. Model Limitations and Risk Factors
### 7.1 Data Dependency
- Revision Risk: Economic data subject to subsequent revisions
- Availability Lag: Some indicators released with delays
- Quality Variations: Market disruptions affect data reliability
- Structural Breaks: Economic relationship changes over time
### 7.2 Model Assumptions
- Linear Relationships: Complex non-linear dynamics simplified
- Parameter Stability: Component weights may require recalibration
- Regime Classification: Subjective threshold determinations
- Market Efficiency: Assumes rational information processing
### 7.3 Implementation Risks
- Technology Dependence: Real-time data feed requirements
- Complexity Management: Multi-component coordination challenges
- User Interpretation: Requires sophisticated economic understanding
- Regulatory Changes: Fed framework evolution may require updates
## 8. Future Research Directions
### 8.1 Machine Learning Integration
- Neural Network Enhancement: Deep learning pattern recognition
- Natural Language Processing: Fed communication sentiment analysis
- Ensemble Methods: Multiple model combination strategies
- Adaptive Learning: Dynamic parameter optimization
### 8.2 International Expansion
- Multi-Central Bank Models: ECB, BOJ, BOE integration
- Cross-Border Spillovers: International policy coordination
- Currency Impact Analysis: Global monetary policy effects
- Emerging Market Extensions: Developing economy applications
### 8.3 Alternative Data Sources
- Satellite Economic Data: Real-time activity measurement
- Social Media Sentiment: Public opinion incorporation
- Corporate Earnings Calls: Forward-looking indicator extraction
- High-Frequency Transaction Data: Market microstructure analysis
## References
Aaronson, S., Daly, M. C., Wascher, W. L., & Wilcox, D. W. (2019). Okun revisited: Who benefits most from a strong economy? Brookings Papers on Economic Activity, 2019(1), 333-404.
Bernanke, B. S. (2015). The Taylor rule: A benchmark for monetary policy? Brookings Institution Blog. Retrieved from www.brookings.edu
Blinder, A. S., Ehrmann, M., Fratzscher, M., De Haan, J., & Jansen, D. J. (2008). Central bank communication and monetary policy: A survey of theory and evidence. Journal of Economic Literature, 46(4), 910-945.
Brave, S., & Butters, R. A. (2011). Monitoring financial stability: A financial conditions index approach. Economic Perspectives, 35(1), 22-43.
Clarida, R., Galí, J., & Gertler, M. (1999). The science of monetary policy: A new Keynesian perspective. Journal of Economic Literature, 37(4), 1661-1707.
Clarida, R. H. (2019). The Federal Reserve's monetary policy response to COVID-19. Brookings Papers on Economic Activity, 2020(2), 1-52.
Clarida, R. H. (2025). Modern monetary policy rules and Fed decision-making. American Economic Review, 115(2), 445-478.
Daly, M. C., Hobijn, B., Şahin, A., & Valletta, R. G. (2012). A search and matching approach to labor markets: Did the natural rate of unemployment rise? Journal of Economic Perspectives, 26(3), 3-26.
Federal Reserve. (2024). Monetary Policy Report. Washington, DC: Board of Governors of the Federal Reserve System.
Hatzius, J., Hooper, P., Mishkin, F. S., Schoenholtz, K. L., & Watson, M. W. (2010). Financial conditions indexes: A fresh look after the financial crisis. National Bureau of Economic Research Working Paper, No. 16150.
Orphanides, A. (2003). Historical monetary policy analysis and the Taylor rule. Journal of Monetary Economics, 50(5), 983-1022.
Powell, J. H. (2024). Data-dependent monetary policy in practice. Federal Reserve Board Speech. Jackson Hole Economic Symposium, Federal Reserve Bank of Kansas City.
Taylor, J. B. (1993). Discretion versus policy rules in practice. Carnegie-Rochester Conference Series on Public Policy, 39, 195-214.
Yellen, J. L. (2017). The goals of monetary policy and how we pursue them. Federal Reserve Board Speech. University of California, Berkeley.
---
Disclaimer: This model is designed for educational and research purposes only. Past performance does not guarantee future results. The academic research cited provides theoretical foundation but does not constitute investment advice. Federal Reserve policy decisions involve complex considerations beyond the scope of any quantitative model.
Citation: EdgeTools Research Team. (2025). Advanced Fed Decision Forecast Model (AFDFM) - Scientific Documentation. EdgeTools Quantitative Research Series

Timeframe LoopThe Timeframe Loop publication aims to visualize intrabar price progression in a new, different way.
🔶 CONCEPTS and USAGE
I got inspiration from the Pressure/Volume loop, which is used in Mechanical Ventilation with Critical Care patients to visualize pressure/volume evolution during inhalation/exhalation.
The main idea is that intrabar prices are visualized by a loop, going to the right during the first half and returning to the left towards its closing point. Here, the main chart timeframe (CTF) is 4 hours, and we see the movements of eight 30-minute lower timeframe (LTF) periods, highlighted by four yellow dots/lines (first 2 hours -> "Right") and four blue dots/lines (last 2 hours <- "Left"):
🔹 BTF
If "Show Lowest TF" is enabled, the LTF is split into another lower TF (BTF - "Base TF"); in this case, the 30-minute LTF is split into 10 parts of 3 minutes (BTF):
Enabling "Loop Lowest TF" will enable the BTF to react similarly to the largest loop; from halfway, it will return to its startpoint:
Here is a more detailed example:
🔹 Mini-Candles
The included option "Mini-Candles" will bring even more detail, showing the LTF as Japanese candlesticks with user-defined colors and adjustable body width; in this example, the mini-candles associated with the first half (yellow lines/dots) are green/red, while blue/fuchsia in the second half (blue lines/dots):
CTF 10 minutes, LTF 1 minute, BTF 5 seconds
One can see the detailed intrabar price progression in one glance.
CTF 5 minutes, LTF 1 minute, BTF 5 seconds
If the LTF/BTF ratio, divided by two, results in a non-integer number, the right side will be a vertical line instead of just a turning point. In that case, the smaller, most right blue loop will be situated at the right of that line.
10 minutes / 1 minute = 10 -> 10 / 2 = 5 parts
5 minutes / 1 minute = 5 -> 5 / 2 = 2.5 parts
🔶 SETTINGS
🔹 Timeframes
Lower Timeframe 1
Lower Timeframe 2
No need to worry about the order of both timeframes; BTF will be the lowest TF of the 2, LTF the highest; both have to be lower than the main chart TF (CTF); otherwise, it will result in the error: "`Lower Timeframes` should be lower than current chart timeframe".
The ratio LTF / BTF should be equal or higher than 2; otherwise, this error will show: "`Lower Timeframe` should minimally be twice the `Base (smallest) Timeframe`"
Lastly, the ratio CTF / BTF should be lower than 500; otherwise, this error will pop up: "`Current Chart timeframe` / `Lower Timeframe` should be less than 500."
I have tried to capture runtime errors as best I could. If one should be triggered (red exclamation mark next to the title), it is best to increase the lowest TF.
🔹 Options
Show Lowest TF: Show BTF progression.
Loop Lowest TF: Enabling will let the BTF line return halfway.
Show Mini-Candles
Show Steps
"Show Steps" can be useful to see how the script works, where the location of the current price is compared against the position of the left (L) and right (R) labels:
🔹 Style

Deviation Trend Profile [BigBeluga]🔵 OVERVIEW
A statistical trend analysis tool that combines moving average dynamics with standard deviation zones and trend-specific price distribution.
This is an experimental indicator designed for educational and learning purposes only.
🔵 CONCEPTS
Trend Detection via SMA Slope: Detects trend shifts when the slope of the SMA exceeds a ±0.1 threshold.
Standard Deviation Zones: Calculates ±1, ±2, and ±3 levels from the SMA using ATR, forming dynamic envelopes around the mean.
Trend Distribution Profile: Builds a histogram that shows how often price closed within each deviation zone during the active trend phase.
🔵 FEATURES
Trend Signals: Immediate shift markers using colored circles at trend reversals.
SMA Gradient Coloring: The SMA line dynamically changes color based on its directional slope.
Trend Duration Label: A label above the histogram shows how many bars the current trend has lasted.
Trend Distribution Histogram: Visual bin-based profile showing frequency of price closes within deviation bands during trend lookback period.
Adjustable Bin Count: Set the granularity of the distribution using the “Bins Amount” input.
Deviation Labels and Zones: Clearly marked ±1, ±2, ±3 lines with consistent color scheme.
Trend Strength Insight:
• Wide profile skewed to ±2/3 = strong directional trend.
• Profile clustered near SMA = potential trend exhaustion or range.
🔵 HOW TO USE
Use trend shift dots as entry signals:
• 🔵 = Bullish start
• 🔴 = Bearish start
Trade with the trend when price clusters in outer zones (±2 or ±3).
Be cautious or fade the trend when price distribution contracts toward the SMA.
View across multiple timeframes for trend confluence or divergence.
🔵 CONCLUSION
Deviation Trend Profile visualizes how price distributes during trends relative to statistical deviation zones.
It’s a powerful confluence tool for identifying strength, exhaustion, and the rhythm of price behavior—ideal for swing traders and volatility analysts alike.

Rolling Z-Score Trend [QuantAlgo]🟢 Overview
The Rolling Z-Score Trend measures how far the current price deviates from its rolling mean in terms of standard deviations. It transforms price data into standardized scores to identify overbought and oversold conditions while tracking momentum shifts.
The indicator displays a Z-Score line showing price deviation from statistical norms, with background momentum columns showing the rate of change in these deviations. This helps traders and investors identify mean reversion opportunities and momentum shifts across different asset classes and timeframes.
🟢 How It Works
The indicator uses the Z-Score formula: Z = (X - μ) / σ, where X is the current closing price, μ is the rolling mean, and σ is the rolling standard deviation over a user-defined lookback period. This creates a dynamic baseline that adapts to changing market conditions and standardizes price movements for interpretation across different assets and volatility conditions. The raw Z-Score undergoes 3-period EMA smoothing to reduce noise while maintaining responsiveness to market signals.
Beyond the basic Z-Score calculation, the indicator measures the rate of change in Z-Score values between successive bars, displayed as background momentum columns. This momentum component shows acceleration and deceleration of statistical deviations. All calculations are processed through confirmation filters, displaying signals only on confirmed bars to reduce premature signals based on incomplete price action.
🟢 How to Use
1. Z-Score Interpretation and Threshold Zones
Positive Values (Above Zero) : Price trading above statistical mean, suggesting bullish momentum or potential overbought conditions
Negative Values (Below Zero) : Price trading below statistical mean, suggesting bearish momentum or potential oversold conditions
Zero Line Crosses : Signal transitions between statistical regimes and potential trend changes
Upper Threshold Zone : Area above entry threshold (default 1.5) indicating potential overbought conditions
Lower Threshold Zone : Area below negative entry threshold (default -1.5) indicating potential oversold conditions
Extreme Values (±2.0 or higher) : Statistically significant deviations that may indicate reversal opportunities
2. Momentum Background Analysis and Info Table
Green Columns : Accelerating positive momentum in Z-Score values
Red Columns : Accelerating negative momentum in Z-Score values
Column Height : Magnitude of momentum change between bars
Momentum Divergence : When columns contradict primary Z-Score direction, often signals impending reversals
Info Table : Displays real-time numerical values for both Z-Score and momentum, including trend direction indicators and bar-to-bar change calculations for position management
3. Preconfigured Settings
Default : Balanced performance across multiple timeframes and asset classes for general trading and medium-term position management.
Scalping : Responsive setup for ultra-short-term trading on 1-15 minute charts with frequent signals and increased sensitivity to quick price movements.
Swing Trading : Optimized for multi-day positions with noise filtering, focusing on larger price swings. Most effective on 1-4 hour and daily timeframes.
Trend Following : Maximum smoothing that prioritizes established trends over short-term volatility. Generates fewer signals for daily and weekly charts.
Yelober - Sector Rotation Detector# Yelober - Sector Rotation Detector: User Guide
## Overview
The Yelober - Sector Rotation Detector is a TradingView indicator designed to track sector performance and identify market rotations in real-time. It monitors key sector ETFs, calculates performance metrics, and provides actionable stock recommendations based on sector strength and weakness.
## Purpose
This indicator helps traders identify when capital is moving from one sector to another (sector rotation), which can provide valuable trading opportunities. It also detects risk-off conditions in the market and highlights sectors with abnormal trading volume.
## Table Columns Explained
### 1. Sector
Displays the sector name being monitored. The indicator tracks six primary sectors plus the S&P 500:
- Energy (XLE)
- Financial (XLF)
- Technology (XLK)
- Consumer Staples (XLP)
- Utilities (XLU)
- Consumer Discretionary (XLY)
- S&P 500 (SPY)
### 2. Perf %
Shows the daily percentage performance of each sector ETF. Values are color-coded:
- Green: Positive performance
- Red: Negative performance
Positive values display with a "+" sign (e.g., +1.25%)
### 3. RSI
Displays the Relative Strength Index value for each sector, which helps identify overbought or oversold conditions:
- Values above 70 (highlighted in red): Potentially overbought
- Values below 30 (highlighted in green): Potentially oversold
- Values between 30-70 (highlighted in blue): Neutral territory
### 4. Vol Ratio
Shows the volume ratio, which compares today's volume to the average volume over the lookback period:
- Values above 1.5x (highlighted in yellow): Indicates abnormally high trading volume
- Values below 1.5x (highlighted in blue): Normal trading volume
This helps identify sectors with unusual activity that may signal important price movements.
### 5. Trend
Displays the current price trend direction with symbols:
- ▲ (green): Uptrend (today's close > yesterday's close)
- ▼ (red): Downtrend (today's close < yesterday's close)
- ◆ (gray): Neutral (today's close = yesterday's close)
## Summary & Recommendations Section
The summary section provides:
1. **Sector Rotation Detection**: Identifies when there's a significant performance gap (>2%) between the strongest and weakest sectors.
2. **Risk-Off Mode Detection**: Alerts when defensive sectors (Consumer Staples and Utilities) are positive while Technology is negative, which often signals investors are moving to safer assets.
3. **Strong Volume Detection**: Indicates when any sector shows abnormally high trading volume.
4. **Stock Recommendations**: Suggests specific stocks to consider for long positions (from the strongest sectors) and short positions (from the weakest sectors).
## Example Interpretations
### Example 1: Sector Rotation
If you see:
- Technology: -1.85%
- Financial: +2.10%
- Summary shows: "SECTOR ROTATION DETECTED: Rotation from Technology to Financial"
**Interpretation**: Capital is moving out of tech stocks and into financial stocks. This could be due to rising interest rates, which typically benefit banks while pressuring high-growth tech companies. Consider looking at financial stocks like JPM, BAC, and WFC for potential long positions.
### Example 2: Risk-Off Conditions
If you see:
- Consumer Staples: +0.80%
- Utilities: +1.20%
- Technology: -1.50%
- Summary shows: "RISK-OFF MODE DETECTED"
**Interpretation**: Investors are seeking safety in defensive sectors while selling growth-oriented tech stocks. This often occurs during market uncertainty or ahead of economic concerns. Consider reducing exposure to high-beta stocks and possibly adding defensive names like PG, KO, or NEE.
### Example 3: Volume Spike
If you see:
- Energy: +3.20% with Volume Ratio 2.5x (highlighted in yellow)
- Summary shows: "STRONG VOLUME DETECTED"
**Interpretation**: The energy sector is making a strong move with significantly higher-than-average volume, suggesting conviction behind the price movement. This could indicate the beginning of a sustained trend in energy stocks. Consider names like XOM, CVX, and COP.
## How to Use the Indicator
1. Apply the indicator to any chart (works best on daily timeframes).
2. Customize settings if needed:
- Timeframe: Choose between intraday (60 or 240 minutes), daily, or weekly
- Lookback Period: Adjust the historical comparison period (default: 20)
- RSI Period: Modify the RSI calculation period (default: 14)
3. To refresh the data: Click the settings icon, increase the "Click + to refresh data" counter, and click "OK".
4. Identify opportunities based on sector performance, RSI levels, volume ratios, and the summary recommendations.
This indicator helps traders align with market rotation trends and identify which sectors (and specific stocks) may outperform or underperform in the near term.

TASC 2025.07 Laguerre Filters█ OVERVIEW
This script implements the Laguerre filter and oscillator described by John F. Ehlers in the article "A Tool For Trend Trading, Laguerre Filters" from the July 2025 edition of TASC's Traders' Tips . The new Laguerre filter utilizes the UltimateSmoother filter in place of an exponential moving average (EMA) in its calculation, offering improved responsiveness and reduced lag.
█ CONCEPTS
As Ehlers explains in his article, the Laguerre filter is a form of transversal filter . A transversal filter calculates an output signal using a tapped delay line . It creates multiple delayed versions of an input signal, applies weight to each delay, and then calculates their sum to generate the filtered result.
The Laguerre filter's structure relies on Laguerre polynomials — solutions to a differential equation solved by Edmond Laguerre in the 1800s. When Ehlers analyzed the formula for these polynomials on discrete systems (e.g., financial time series), he found that the first term's expression corresponds to an EMA response, and all subsequent terms correspond to an all-pass response. In contrast to other filter types, an all-pass filter produces phase shift (i.e., delay) in an input signal's components without affecting its amplitude.
Ehlers observed that these characteristics of Laguerre polynomials make them suitable for use in a transversal filter structure, and thus the Laguerre filter was born. However, he notes that EMAs are not great filters in general. As such, to improve on the Laguerre filter's design, Ehlers modified it by replacing the EMA term with his UltimateSmoother filter. The resulting Laguerre filter has significantly reduced lag, achieving a tighter response to market fluctuations while maintaining smoothness. Ehlers suggests that traders can analyze crossings between the UltimateSmoother and this Laguerre filter, or those between two Laguerre filters of different order, for helpful buy and sell signals.
In addition to the Laguerre filter, Ehlers derived a smooth, low-lag oscillator based on the difference between the first and second terms in the modified filter structure, scaled by the root mean square (RMS). The resulting oscillator provides an alternative filtered representation of market data, which can help traders identify swing and mean-reversion signals.
█ USAGE
This indicator calculates both the Laguerre filter and the Laguerre oscillator described in Ehlers' article. It displays the Laguerre filter on the main chart pane and the oscillator in a separate pane.
Users can control the behavior of the filter and oscillator with the inputs in the "Settings/Inputs" tab:
The "Period" input defines the critical period of the UltimateSmoother used in the Laguerre filter and oscillator calculations. Its default value is 30.
The "Gamma" input determines the weighting behavior of the Laguerre filter and oscillator. It accepts a positive value between 0 and 1. Use a lower value for quicker responsiveness to market changes, and a higher value for trends. The default value is 0.5.
The "RMS length" input determines the length of the RMS calculation for oscillator normalization. The default value is 100 bars.

Trend Impulse Channels (Zeiierman)█ Overview
Trend Impulse Channels (Zeiierman) is a precision-engineered trend-following system that visualizes discrete trend progression using volatility-scaled step logic. It replaces traditional slope-based tracking with clearly defined “trend steps,” capturing directional momentum only when price action decisively confirms a shift through an ATR-based trigger.
This tool is ideal for traders who prefer structured, stair-step progression over fluid curves, and value the clarity of momentum-based bands that reveal breakout conviction, pullback retests, and consolidation zones. The channel width adapts automatically to market volatility, while the step logic filters out noise and false flips.
⚪ The Structural Assumption
This indicator is built on a core market structure observation:
After each strong trend impulse, the market typically enters a “cooling-off” phase as profit-taking occurs and counter-trend participants enter. This often results in a shallow pullback or stall, creating a slight negative slope in an uptrend (or a positive slope in a downtrend).
These “cooling-off” phases don’t reverse the trend — they signal temporary pressure before the next leg continues. By tracking trend steps discretely and filtering for this behavior, Trend Impulse Channels helps traders align with the rhythm of impulse → pause → impulse.
█ How It Works
⚪ Step-Based Trend Engine
At the heart of this tool is a dynamic step engine that progresses only when price crosses a predefined ATR-scaled trigger level:
Trigger Threshold (× ATR) – Defines how far price must break beyond the current trend state to register a new trend step.
Step Size (Volatility-Guided) – Each trend continuation moves the trend line in discrete units, scaling with ATR and trend persistence.
Trend Direction State – Maintains a +1/-1 internal bias to support directional filters and step tracking.
⚪ Volatility-Adaptive Channel
Each step is wrapped inside a dynamic envelope scaled to current volatility:
Upper and Lower Bands – Derived from ATR and band multipliers to expand/contract as volatility changes.
⚪ Retest Signal System
Optional signal markers show when price re-tests the upper or lower band:
Upper Retest → Pullback into resistance during a bearish trend.
Lower Retest → Pullback into support during a bullish trend.
⚪ Trend Step Signals
Circular markers can be shown to mark each time the trend steps forward, making it easy to identify structurally significant moments of continuation within a larger trend.
█ How to Use
⚪ Trend Alignment
Use the Trend Line and Step Markers to visually confirm the direction of momentum. If multiple trend steps occur in sequence without reversal, this typically signals strong conviction and trend persistence.
⚪ Retest-Based Entries
Wait for pullbacks into the channel and monitor for triangle retest signals. When used in confluence with trend direction, these offer high-quality continuation setups.
⚪ Breakouts
Look for breakouts beyond the upper or lower band after a longer period of pause. For higher likelihood of success, look for breakouts in the direction of the trend.
█ Settings
Trigger Threshold (× ATR) - Defines how far price must move to register a new trend step. Controls sensitivity to trend flips.
Max Step Size (× ATR) - Caps how far each trend step can extend. Prevents runaway step expansion in high volatility.
Band Multiplier (× ATR) - Expands the upper and lower channels. Controls how much breathing room the bands allow.
Trend Hold (bars) - Minimum number of bars the trend must remain active before allowing a flip. Helps reduce noise.
Filter by Trend - Restrict retest signals to those aligned with the current trend direction.
-----------------
Disclaimer
The content provided in my scripts, indicators, ideas, algorithms, and systems is for educational and informational purposes only. It does not constitute financial advice, investment recommendations, or a solicitation to buy or sell any financial instruments. I will not accept liability for any loss or damage, including without limitation any loss of profit, which may arise directly or indirectly from the use of or reliance on such information.
All investments involve risk, and the past performance of a security, industry, sector, market, financial product, trading strategy, backtest, or individual's trading does not guarantee future results or returns. Investors are fully responsible for any investment decisions they make. Such decisions should be based solely on an evaluation of their financial circumstances, investment objectives, risk tolerance, and liquidity needs.

Magnificent 7 OscillatorThe Magnificent 7 Oscillator is a sophisticated momentum-based technical indicator designed to analyze the collective performance of the seven largest technology companies in the U.S. stock market (Apple, Microsoft, Alphabet, Amazon, NVIDIA, Tesla, and Meta). This indicator incorporates established momentum factor research and provides three distinct analytical modes: absolute momentum tracking, equal-weighted market comparison, and relative performance analysis. The tool integrates five different oscillator methodologies and includes advanced breadth analysis capabilities.
Theoretical Foundation
Momentum Factor Research
The indicator's foundation rests on seminal momentum research in financial markets. Jegadeesh and Titman (1993) demonstrated that stocks with strong price performance over 3-12 month periods tend to continue outperforming in subsequent periods¹. This momentum effect was later incorporated into formal factor models by Carhart (1997), who extended the Fama-French three-factor model to include a momentum factor (UMD - Up Minus Down)².
The momentum calculation methodology follows the academic standard:
Momentum(t) = / P(t-n) × 100
Where P(t) is the current price and n is the lookback period.
The focus on the "Magnificent 7" stocks reflects the increasing market concentration observed in recent years. Fama and French (2015) noted that a small number of large-cap stocks can drive significant market movements due to their substantial index weights³. The combined market capitalization of these seven companies often exceeds 25% of the total S&P 500, making their collective momentum a critical market indicator.
Indicator Architecture
Core Components
1. Data Collection and Processing
The indicator employs robust data collection with error handling for missing or invalid security data. Each stock's momentum is calculated independently using the specified lookback period (default: 14 periods).
2. Composite Oscillator Calculation
Following Fama-French factor construction methodology, the indicator offers two weighting schemes:
- Equal Weight: Each active stock receives identical weighting (1/n)
- Market Cap Weight: Reserved for future enhancement
3. Oscillator Transformation Functions
The indicator provides five distinct oscillator types, each with established technical analysis foundations:
a) Momentum Oscillator (Default)
- Pure rate-of-change calculation
- Centered around zero
- Direct implementation of Jegadeesh & Titman methodology
b) RSI (Relative Strength Index)
- Wilder's (1978) relative strength methodology
- Transformed to center around zero for consistency
- Scale: -50 to +50
c) Stochastic Oscillator
- George Lane's %K methodology
- Measures current position within recent range
- Transformed to center around zero
d) Williams %R
- Larry Williams' range-based oscillator
- Inverse stochastic calculation
- Adjusted for zero-centered display
e) CCI (Commodity Channel Index)
- Donald Lambert's mean reversion indicator
- Measures deviation from moving average
- Scaled for optimal visualization
Operational Modes
Mode 1: Magnificent 7 Analysis
Tracks the collective momentum of the seven constituent stocks. This mode is optimal for:
- Technology sector analysis
- Growth stock momentum assessment
- Large-cap performance tracking
Mode 2: S&P 500 Equal Weight Comparison
Analyzes momentum using an equal-weighted S&P 500 reference (typically RSP ETF). This mode provides:
- Broader market momentum context
- Size-neutral market analysis
- Comparison baseline for relative performance
Mode 3: Relative Performance Analysis
Calculates the momentum differential between Magnificent 7 and S&P 500 Equal Weight. This mode enables:
- Sector rotation analysis
- Style factor assessment (Growth vs. Value)
- Relative strength identification
Formula: Relative Performance = MAG7_Momentum - SP500EW_Momentum
Signal Generation and Thresholds
Signal Classification
The indicator generates three signal states:
- Bullish: Oscillator > Upper Threshold (default: +2.0%)
- Bearish: Oscillator < Lower Threshold (default: -2.0%)
- Neutral: Oscillator between thresholds
Relative Performance Signals
In relative performance mode, specialized thresholds apply:
- Outperformance: Relative momentum > +1.0%
- Underperformance: Relative momentum < -1.0%
Alert System
Comprehensive alert conditions include:
- Threshold crossovers (bullish/bearish signals)
- Zero-line crosses (momentum direction changes)
- Relative performance shifts
- Breadth Analysis Component
The indicator incorporates market breadth analysis, calculating the percentage of constituent stocks with positive momentum. This feature provides insights into:
- Strong Breadth (>60%): Broad-based momentum
- Weak Breadth (<40%): Narrow momentum leadership
- Mixed Breadth (40-60%): Neutral momentum distribution
Visual Design and User Interface
Theme-Adaptive Display
The indicator automatically adjusts color schemes for dark and light chart themes, ensuring optimal visibility across different user preferences.
Professional Data Table
A comprehensive data table displays:
- Current oscillator value and percentage
- Active mode and oscillator type
- Signal status and strength
- Component breakdowns (in relative performance mode)
- Breadth percentage
- Active threshold levels
Custom Color Options
Users can override default colors with custom selections for:
- Neutral conditions (default: Material Blue)
- Bullish signals (default: Material Green)
- Bearish signals (default: Material Red)
Practical Applications
Portfolio Management
- Sector Allocation: Use relative performance mode to time technology sector exposure
- Risk Management: Monitor breadth deterioration as early warning signal
- Entry/Exit Timing: Utilize threshold crossovers for position sizing decisions
Market Analysis
- Trend Identification: Zero-line crosses indicate momentum regime changes
- Divergence Analysis: Compare MAG7 performance against broader market
- Volatility Assessment: Oscillator range and frequency provide volatility insights
Strategy Development
- Factor Timing: Implement growth factor timing strategies
- Momentum Strategies: Develop systematic momentum-based approaches
- Risk Parity: Use breadth metrics for risk-adjusted portfolio construction
Configuration Guidelines
Parameter Selection
- Momentum Period (5-100): Shorter periods (5-20) for tactical analysis, longer periods (50-100) for strategic assessment
- Smoothing Period (1-50): Higher values reduce noise but increase lag
- Thresholds: Adjust based on historical volatility and strategy requirements
Timeframe Considerations
- Daily Charts: Optimal for swing trading and medium-term analysis
- Weekly Charts: Suitable for long-term trend analysis
- Intraday Charts: Useful for short-term tactical decisions
Limitations and Considerations
Market Concentration Risk
The indicator's focus on seven stocks creates concentration risk. During periods of significant rotation away from large-cap technology stocks, the indicator may not represent broader market conditions.
Momentum Persistence
While momentum effects are well-documented, they are not permanent. Jegadeesh and Titman (1993) noted momentum reversal effects over longer time horizons (2-5 years).
Correlation Dynamics
During market stress, correlations among the constituent stocks may increase, reducing the diversification benefits and potentially amplifying signal intensity.
Performance Metrics and Backtesting
The indicator includes hidden plots for comprehensive backtesting:
- Individual stock momentum values
- Composite breadth percentage
- S&P 500 Equal Weight momentum
- Relative performance calculations
These metrics enable quantitative strategy development and historical performance analysis.
References
¹Jegadeesh, N., & Titman, S. (1993). Returns to buying winners and selling losers: Implications for stock market efficiency. Journal of Finance, 48(1), 65-91.
Carhart, M. M. (1997). On persistence in mutual fund performance. Journal of Finance, 52(1), 57-82.
Fama, E. F., & French, K. R. (2015). A five-factor asset pricing model. Journal of Financial Economics, 116(1), 1-22.
Wilder, J. W. (1978). New concepts in technical trading systems. Trend Research.
SmartPhase Analyzer📝 SmartPhase Analyzer – Composite Market Regime Classifier
SmartPhase Analyzer is an adaptive regime classification tool that scores market conditions using a customizable set of statistical indicators. It blends multiple normalized metrics into a composite score, which is dynamically evaluated against rolling statistical thresholds to determine the current market regime.
✅ Features:
Composite score calculated from 13+ toggleable statistical indicators:
Sharpe, Sortino, Omega, Alpha, Beta, CV, R², Entropy, Drawdown, Z-Score, PLF, SRI, and Momentum Rank
Uses dynamic thresholds (mean ± std deviation) to classify regime states:
🟢 BULL – Strongly bullish
🟩 ACCUM – Mildly bullish
⚪ NEUTRAL – Sideways
🟧 DISTRIB – Mildly bearish
🔴 BEAR – Strongly bearish
Color-coded histogram for composite score clarity
Real-time regime label plotted on chart
Benchmark-aware metrics (Alpha, Beta, etc.)
Modular design using the StatMetrics library by RWCS_LTD
🧠 How to Use:
Enable/disable metrics in the settings panel to customize your composite model
Use the composite histogram and regime background for discretionary or systematic analysis
⚠️ Disclaimer:
This indicator is for educational and informational purposes only. It does not constitute financial advice or a trading recommendation. Always consult your financial advisor before making investment decisions.

ATR RopeATR Rope is inspired by DonovanWall's "Range Filter". It implements a similar concept of filtering out smaller market movements and adjusting only for larger moves. In addition, this indicator goes one step deeper by producing actionable zones to determine market state. (Trend vs. Consolidation)
> Background
When reading up on the Range Filter indicator, it reminded me exactly of a Rope stabilization drawing tool in a program I use frequently. Rope stabilization essentially attaches a fixed length "rope" to your cursor and an anchor point (Brush). As you move your cursor, you are pulling the brush behind it. The cursor (of course) will not pull the brush until the rope is fully extended, this behavior filters out jittery movements and is used to produce smoother drawing curves.
If compared visually side-by-side, you will notice that this indicator bears striking resemblance to its inspiration.
> Goal
Other than simply distinguishing price movements between meaningful and noise, this indicator strives to create a rigid structure to frame market movements and lack-there-of, such as when to anticipate trend, and when to suspect consolidation.
Since the indicator works based on an ATR range, the resulting ATR Channel does well to get reactions from price at its extremes. Naturally, when consolidating, price will remain within the channel, neither pushing the channel significantly up or down. Likewise, when trending, price will continue to push the channel in a single direction.
With the goal of keeping it quick and simple, this indicator does not do any smoothing of data feeds, and is simply based on the deviation of price from the central rope. Adjusting the rope when price extends past the threshold created by +/- ATR from the rope.
> Features & Behaviors
- ATR Rope
ATR Rope is displayed as a 3 color single line.
This can be considered the center line, or the directional line, whichever you'd prefer.
The main point of the Rope display is to indicate direction, however it also is factually the center of the current working range.
- ATR Rope Color
When the rope's value moves up, it changes to green (uptrend), when down, red (downtrend).
When the source crosses the rope, it turns blue (flat).
With these simple rules, we've formed a structure to view market movements.
- Consolidation Zones
Consolidation Zones generate from "Flat" areas, and extend into subsequent trend areas. Consolidation is simply areas where price has crossed the Rope and remains inside the range. Over these periods, the upper and lower values are accumulated and averaged together to form the "Consolidation Zone" values. These zones are draw live, so values are averaged as the flat areas progress and don't repaint, so all values seen historically are as they would appear live.
- ATR Channel
ATR Channel displays the upper and lower bounds of the working range.
When the source moves beyond this range, the rope is adjusted based on the distance from the source to the channel. This range can be extremely useful to view, but by default it is hidden.
> Application
This indicator is not created to provide signals, or serve as a "complete" system.
(People who didn't read this far will still comment for signals. :) )
This is created to be used alongside manual interpretation and intuition. This indicator is not meant to constrain any users into a box, and I would actually encourage an open mind and idea generation, as the application of this indicator can take various forms.
> Examples
As you would probably already know, price movement can be fast impulses, and movement can be slow bleeds. In the screenshot below, we are using movements from and to consolidation zones to classify weak trend and strong trend. As you can see, there are also areas of consolidation which get broken out of and confirmed for the larger moves.
Author's Note: In each of these examples, I have outlined the start and end of each session. These examples come from 1 Min Future charts, and have specifically been framed with day trading in mind.
"Breakout Retest" or "Support/Resistance Flips" or "Structure Retests" are all generally the same thing, with different traders referring to them by different names, all of which can be seen throughout these examples.
In the next example, we have a day which started with an early reversal leading into long, slow, trend. Notice how each area throughout the trend essentially moves slightly higher, then consolidates while holding support of the previous zone. This day had a few sharp movements, however there was a large amount of neutrality throughout this day with continuous higher lows.
In contrast to the previous example, next up, we have a very choppy day. Throughout which we see a significant amount of retests before fast directional movements. We also see a few examples of places where previous zones remained relevant into the future. While the zones only display into the resulting trend area, they do not become immediately meaningless once they stop drawing.
> Abstract
In the screenshot below, I have stacked 2 of these indicators, using the high as the source for one and the low as the source for the other. I've hidden lines of the high and low channels to create a 4 lined channel based on the wicks of price.
This is not necessary to use the indicator, but should help provide an idea of creative ways the simple indicator could be used to produce more complicated analysis.
If you've made it this far, I would hope it's clear to you how this indicator could provide value to your trading.
Thank you to DonovonWall for the inspiration.
Enjoy!

Langlands-Operadic Möbius Vortex (LOMV)Langlands-Operadic Möbius Vortex (LOMV)
Where Pure Mathematics Meets Market Reality
A Revolutionary Synthesis of Number Theory, Category Theory, and Market Dynamics
🎓 THEORETICAL FOUNDATION
The Langlands-Operadic Möbius Vortex represents a groundbreaking fusion of three profound mathematical frameworks that have never before been combined for market analysis:
The Langlands Program: Harmonic Analysis in Markets
Developed by Robert Langlands (Fields Medal recipient), the Langlands Program creates bridges between number theory, algebraic geometry, and harmonic analysis. In our indicator:
L-Function Implementation:
- Utilizes the Möbius function μ(n) for weighted price analysis
- Applies Riemann zeta function convergence principles
- Calculates quantum harmonic resonance between -2 and +2
- Measures deep mathematical patterns invisible to traditional analysis
The L-Function core calculation employs:
L_sum = Σ(return_val × μ(n) × n^(-s))
Where s is the critical strip parameter (0.5-2.5), controlling mathematical precision and signal smoothness.
Operadic Composition Theory: Multi-Strategy Democracy
Category theory and operads provide the mathematical framework for composing multiple trading strategies into a unified signal. This isn't simple averaging - it's mathematical composition using:
Strategy Composition Arity (2-5 strategies):
- Momentum analysis via RSI transformation
- Mean reversion through Bollinger Band mathematics
- Order Flow Polarity Index (revolutionary T3-smoothed volume analysis)
- Trend detection using Directional Movement
- Higher timeframe momentum confirmation
Agreement Threshold System: Democratic voting where strategies must reach consensus before signal generation. This prevents false signals during market uncertainty.
Möbius Function: Number Theory in Action
The Möbius function μ(n) forms the mathematical backbone:
- μ(n) = 1 if n is a square-free positive integer with even number of prime factors
- μ(n) = -1 if n is a square-free positive integer with odd number of prime factors
- μ(n) = 0 if n has a squared prime factor
This creates oscillating weights that reveal hidden market periodicities and harmonic structures.
🔧 COMPREHENSIVE INPUT SYSTEM
Langlands Program Parameters
Modular Level N (5-50, default 30):
Primary lookback for quantum harmonic analysis. Optimized by timeframe:
- Scalping (1-5min): 15-25
- Day Trading (15min-1H): 25-35
- Swing Trading (4H-1D): 35-50
- Asset-specific: Crypto 15-25, Stocks 30-40, Forex 35-45
L-Function Critical Strip (0.5-2.5, default 1.5):
Controls Riemann zeta convergence precision:
- Higher values: More stable, smoother signals
- Lower values: More reactive, catches quick moves
- High frequency: 0.8-1.2, Medium: 1.3-1.7, Low: 1.8-2.3
Frobenius Trace Period (5-50, default 21):
Galois representation lookback for price-volume correlation:
- Measures harmonic relationships in market flows
- Scalping: 8-15, Day Trading: 18-25, Swing: 25-40
HTF Multi-Scale Analysis:
Higher timeframe context prevents trading against major trends:
- Provides market bias and filters signals
- Improves win rates by 15-25% through trend alignment
Operadic Composition Parameters
Strategy Composition Arity (2-5, default 4):
Number of algorithms composed for final signal:
- Conservative: 4-5 strategies (higher confidence)
- Moderate: 3-4 strategies (balanced approach)
- Aggressive: 2-3 strategies (more frequent signals)
Category Agreement Threshold (2-5, default 3):
Democratic voting minimum for signal generation:
- Higher agreement: Fewer but higher quality signals
- Lower agreement: More signals, potential false positives
Swiss-Cheese Mixing (0.1-0.5, default 0.382):
Golden ratio φ⁻¹ based blending of trend factors:
- 0.382 is φ⁻¹, optimal for natural market fractals
- Higher values: Stronger trend following
- Lower values: More contrarian signals
OFPI Configuration:
- OFPI Length (5-30, default 14): Order Flow calculation period
- T3 Smoothing (3-10, default 5): Advanced exponential smoothing
- T3 Volume Factor (0.5-1.0, default 0.7): Smoothing aggressiveness control
Unified Scoring System
Component Weights (sum ≈ 1.0):
- L-Function Weight (0.1-0.5, default 0.3): Mathematical harmony emphasis
- Galois Rank Weight (0.1-0.5, default 0.2): Market structure complexity
- Operadic Weight (0.1-0.5, default 0.3): Multi-strategy consensus
- Correspondence Weight (0.1-0.5, default 0.2): Theory-practice alignment
Signal Threshold (0.5-10.0, default 5.0):
Quality filter producing:
- 8.0+: EXCEPTIONAL signals only
- 6.0-7.9: STRONG signals
- 4.0-5.9: MODERATE signals
- 2.0-3.9: WEAK signals
🎨 ADVANCED VISUAL SYSTEM
Multi-Dimensional Quantum Aura Bands
Five-layer resonance field showing market energy:
- Colors: Theme-matched gradients (Quantum purple, Holographic cyan, etc.)
- Expansion: Dynamic based on score intensity and volatility
- Function: Multi-timeframe support/resistance zones
Morphism Flow Portals
Category theory visualization showing market topology:
- Green/Cyan Portals: Bullish mathematical flow
- Red/Orange Portals: Bearish mathematical flow
- Size/Intensity: Proportional to signal strength
- Recursion Depth (1-8): Nested patterns for flow evolution
Fractal Grid System
Dynamic support/resistance with projected L-Scores:
- Multiple Timeframes: 10, 20, 30, 40, 50-period highs/lows
- Smart Spacing: Prevents level overlap using ATR-based minimum distance
- Projections: Estimated signal scores when price reaches levels
- Usage: Precise entry/exit timing with mathematical confirmation
Wick Pressure Analysis
Rejection level prediction using candle mathematics:
- Upper Wicks: Selling pressure zones (purple/red lines)
- Lower Wicks: Buying pressure zones (purple/green lines)
- Glow Intensity (1-8): Visual emphasis and line reach
- Application: Confluence with fractal grid creates high-probability zones
Regime Intensity Heatmap
Background coloring showing market energy:
- Black/Dark: Low activity, range-bound markets
- Purple Glow: Building momentum and trend development
- Bright Purple: High activity, strong directional moves
- Calculation: Combines trend, momentum, volatility, and score intensity
Six Professional Themes
- Quantum: Purple/violet for general trading and mathematical focus
- Holographic: Cyan/magenta optimized for cryptocurrency markets
- Crystalline: Blue/turquoise for conservative, stability-focused trading
- Plasma: Gold/magenta for high-energy volatility trading
- Cosmic Neon: Bright neon colors for maximum visibility and aggressive trading
📊 INSTITUTIONAL-GRADE DASHBOARD
Unified AI Score Section
- Total Score (-10 to +10): Primary decision metric
- >5: Strong bullish signals
- <-5: Strong bearish signals
- Quality ratings: EXCEPTIONAL > STRONG > MODERATE > WEAK
- Component Analysis: Individual L-Function, Galois, Operadic, and Correspondence contributions
Order Flow Analysis
Revolutionary OFPI integration:
- OFPI Value (-100% to +100%): Real buying vs selling pressure
- Visual Gauge: Horizontal bar chart showing flow intensity
- Momentum Status: SHIFTING, ACCELERATING, STRONG, MODERATE, or WEAK
- Trading Application: Flow shifts often precede major moves
Signal Performance Tracking
- Win Rate Monitoring: Real-time success percentage with emoji indicators
- Signal Count: Total signals generated for frequency analysis
- Current Position: LONG, SHORT, or NONE with P&L tracking
- Volatility Regime: HIGH, MEDIUM, or LOW classification
Market Structure Analysis
- Möbius Field Strength: Mathematical field oscillation intensity
- CHAOTIC: High complexity, use wider stops
- STRONG: Active field, normal position sizing
- MODERATE: Balanced conditions
- WEAK: Low activity, consider smaller positions
- HTF Trend: Higher timeframe bias (BULL/BEAR/NEUTRAL)
- Strategy Agreement: Multi-algorithm consensus level
Position Management
When in trades, displays:
- Entry Price: Original signal price
- Current P&L: Real-time percentage with risk level assessment
- Duration: Bars in trade for timing analysis
- Risk Level: HIGH/MEDIUM/LOW based on current exposure
🚀 SIGNAL GENERATION LOGIC
Balanced Long/Short Architecture
The indicator generates signals through multiple convergent pathways:
Long Entry Conditions:
- Score threshold breach with algorithmic agreement
- Strong bullish order flow (OFPI > 0.15) with positive composite signal
- Bullish pattern recognition with mathematical confirmation
- HTF trend alignment with momentum shifting
- Extreme bullish OFPI (>0.3) with any positive score
Short Entry Conditions:
- Score threshold breach with bearish agreement
- Strong bearish order flow (OFPI < -0.15) with negative composite signal
- Bearish pattern recognition with mathematical confirmation
- HTF trend alignment with momentum shifting
- Extreme bearish OFPI (<-0.3) with any negative score
Exit Logic:
- Score deterioration below continuation threshold
- Signal quality degradation
- Opposing order flow acceleration
- 10-bar minimum between signals prevents overtrading
⚙️ OPTIMIZATION GUIDELINES
Asset-Specific Settings
Cryptocurrency Trading:
- Modular Level: 15-25 (capture volatility)
- L-Function Precision: 0.8-1.3 (reactive to price swings)
- OFPI Length: 10-20 (fast correlation shifts)
- Cascade Levels: 5-7, Theme: Holographic
Stock Index Trading:
- Modular Level: 25-35 (balanced trending)
- L-Function Precision: 1.5-1.8 (stable patterns)
- OFPI Length: 14-20 (standard correlation)
- Cascade Levels: 4-5, Theme: Quantum
Forex Trading:
- Modular Level: 35-45 (smooth trends)
- L-Function Precision: 1.6-2.1 (high smoothing)
- OFPI Length: 18-25 (disable volume amplification)
- Cascade Levels: 3-4, Theme: Crystalline
Timeframe Optimization
Scalping (1-5 minute charts):
- Reduce all lookback parameters by 30-40%
- Increase L-Function precision for noise reduction
- Enable all visual elements for maximum information
- Use Small dashboard to save screen space
Day Trading (15 minute - 1 hour):
- Use default parameters as starting point
- Adjust based on market volatility
- Normal dashboard provides optimal information density
- Focus on OFPI momentum shifts for entries
Swing Trading (4 hour - Daily):
- Increase lookback parameters by 30-50%
- Higher L-Function precision for stability
- Large dashboard for comprehensive analysis
- Emphasize HTF trend alignment
🏆 ADVANCED TRADING STRATEGIES
The Mathematical Confluence Method
1. Wait for Fractal Grid level approach
2. Confirm with projected L-Score > threshold
3. Verify OFPI alignment with direction
4. Enter on portal signal with quality ≥ STRONG
5. Exit on score deterioration or opposing flow
The Regime Trading System
1. Monitor Aether Flow background intensity
2. Trade aggressively during bright purple periods
3. Reduce position size during dark periods
4. Use Möbius Field strength for stop placement
5. Align with HTF trend for maximum probability
The OFPI Momentum Strategy
1. Watch for momentum shifting detection
2. Confirm with accelerating flow in direction
3. Enter on immediate portal signal
4. Scale out at Fibonacci levels
5. Exit on flow deceleration or reversal
⚠️ RISK MANAGEMENT INTEGRATION
Mathematical Position Sizing
- Use Galois Rank for volatility-adjusted sizing
- Möbius Field strength determines stop width
- Fractal Dimension guides maximum exposure
- OFPI momentum affects entry timing
Signal Quality Filtering
- Trade only STRONG or EXCEPTIONAL quality signals
- Increase position size with higher agreement levels
- Reduce risk during CHAOTIC Möbius field periods
- Respect HTF trend alignment for directional bias
🔬 DEVELOPMENT JOURNEY
Creating the LOMV was an extraordinary mathematical undertaking that pushed the boundaries of what's possible in technical analysis. This indicator almost didn't happen. The theoretical complexity nearly proved insurmountable.
The Mathematical Challenge
Implementing the Langlands Program required deep research into:
- Number theory and the Möbius function
- Riemann zeta function convergence properties
- L-function analytical continuation
- Galois representations in finite fields
The mathematical literature spans decades of pure mathematics research, requiring translation from abstract theory to practical market application.
The Computational Complexity
Operadic composition theory demanded:
- Category theory implementation in Pine Script
- Multi-dimensional array management for strategy composition
- Real-time democratic voting algorithms
- Performance optimization for complex calculations
The Integration Breakthrough
Bringing together three disparate mathematical frameworks required:
- Novel approaches to signal weighting and combination
- Revolutionary Order Flow Polarity Index development
- Advanced T3 smoothing implementation
- Balanced signal generation preventing directional bias
Months of intensive research culminated in breakthrough moments when the mathematics finally aligned with market reality. The result is an indicator that reveals market structure invisible to conventional analysis while maintaining practical trading utility.
🎯 PRACTICAL IMPLEMENTATION
Getting Started
1. Apply indicator with default settings
2. Select appropriate theme for your markets
3. Observe dashboard metrics during different market conditions
4. Practice signal identification without trading
5. Gradually adjust parameters based on observations
Signal Confirmation Process
- Never trade on score alone - verify quality rating
- Confirm OFPI alignment with intended direction
- Check fractal grid level proximity for timing
- Ensure Möbius field strength supports position size
- Validate against HTF trend for bias confirmation
Performance Monitoring
- Track win rate in dashboard for strategy assessment
- Monitor component contributions for optimization
- Adjust threshold based on desired signal frequency
- Document performance across different market regimes
🌟 UNIQUE INNOVATIONS
1. First Integration of Langlands Program mathematics with practical trading
2. Revolutionary OFPI with T3 smoothing and momentum detection
3. Operadic Composition using category theory for signal democracy
4. Dynamic Fractal Grid with projected L-Score calculations
5. Multi-Dimensional Visualization through morphism flow portals
6. Regime-Adaptive Background showing market energy intensity
7. Balanced Signal Generation preventing directional bias
8. Professional Dashboard with institutional-grade metrics
📚 EDUCATIONAL VALUE
The LOMV serves as both a practical trading tool and an educational gateway to advanced mathematics. Traders gain exposure to:
- Pure mathematics applications in markets
- Category theory and operadic composition
- Number theory through Möbius function implementation
- Harmonic analysis via L-function calculations
- Advanced signal processing through T3 smoothing
⚖️ RESPONSIBLE USAGE
This indicator represents advanced mathematical research applied to market analysis. While the underlying mathematics are rigorously implemented, markets remain inherently unpredictable.
Key Principles:
- Use as part of comprehensive trading strategy
- Implement proper risk management at all times
- Backtest thoroughly before live implementation
- Understand that past performance does not guarantee future results
- Never risk more than you can afford to lose
The mathematics reveal deep market structure, but successful trading requires discipline, patience, and sound risk management beyond any indicator.
🔮 CONCLUSION
The Langlands-Operadic Möbius Vortex represents a quantum leap forward in technical analysis, bringing PhD-level pure mathematics to practical trading while maintaining visual elegance and usability.
From the harmonic analysis of the Langlands Program to the democratic composition of operadic theory, from the number-theoretic precision of the Möbius function to the revolutionary Order Flow Polarity Index, every component works in mathematical harmony to reveal the hidden order within market chaos.
This is more than an indicator - it's a mathematical lens that transforms how you see and understand market structure.
Trade with mathematical precision. Trade with the LOMV.
*"Mathematics is the language with which God has written the universe." - Galileo Galilei*
*In markets, as in nature, profound mathematical beauty underlies apparent chaos. The LOMV reveals this hidden order.*
— Dskyz, Trade with insight. Trade with anticipation.

Risk-Adjusted Momentum Oscillator# Risk-Adjusted Momentum Oscillator (RAMO): Momentum Analysis with Integrated Risk Assessment
## 1. Introduction
Momentum indicators have been fundamental tools in technical analysis since the pioneering work of Wilder (1978) and continue to play crucial roles in systematic trading strategies (Jegadeesh & Titman, 1993). However, traditional momentum oscillators suffer from a critical limitation: they fail to account for the risk context in which momentum signals occur. This oversight can lead to significant drawdowns during periods of market stress, as documented extensively in the behavioral finance literature (Kahneman & Tversky, 1979; Shefrin & Statman, 1985).
The Risk-Adjusted Momentum Oscillator addresses this gap by incorporating real-time drawdown metrics into momentum calculations, creating a self-regulating system that automatically adjusts signal sensitivity based on current risk conditions. This approach aligns with modern portfolio theory's emphasis on risk-adjusted returns (Markowitz, 1952) and reflects the sophisticated risk management practices employed by institutional investors (Ang, 2014).
## 2. Theoretical Foundation
### 2.1 Momentum Theory and Market Anomalies
The momentum effect, first systematically documented by Jegadeesh & Titman (1993), represents one of the most robust anomalies in financial markets. Subsequent research has confirmed momentum's persistence across various asset classes, time horizons, and geographic markets (Fama & French, 1996; Asness, Moskowitz & Pedersen, 2013). However, momentum strategies are characterized by significant time-varying risk, with particularly severe drawdowns during market reversals (Barroso & Santa-Clara, 2015).
### 2.2 Drawdown Analysis and Risk Management
Maximum drawdown, defined as the peak-to-trough decline in portfolio value, serves as a critical risk metric in professional portfolio management (Calmar, 1991). Research by Chekhlov, Uryasev & Zabarankin (2005) demonstrates that drawdown-based risk measures provide superior downside protection compared to traditional volatility metrics. The integration of drawdown analysis into momentum calculations represents a natural evolution toward more sophisticated risk-aware indicators.
### 2.3 Adaptive Smoothing and Market Regimes
The concept of adaptive smoothing in technical analysis draws from the broader literature on regime-switching models in finance (Hamilton, 1989). Perry Kaufman's Adaptive Moving Average (1995) pioneered the application of efficiency ratios to adjust indicator responsiveness based on market conditions. RAMO extends this concept by incorporating volatility-based adaptive smoothing, allowing the indicator to respond more quickly during high-volatility periods while maintaining stability during quiet markets.
## 3. Methodology
### 3.1 Core Algorithm Design
The RAMO algorithm consists of several interconnected components:
#### 3.1.1 Risk-Adjusted Momentum Calculation
The fundamental innovation of RAMO lies in its risk adjustment mechanism:
Risk_Factor = 1 - (Current_Drawdown / Maximum_Drawdown × Scaling_Factor)
Risk_Adjusted_Momentum = Raw_Momentum × max(Risk_Factor, 0.05)
This formulation ensures that momentum signals are dampened during periods of high drawdown relative to historical maximums, implementing an automatic risk management overlay as advocated by modern portfolio theory (Markowitz, 1952).
#### 3.1.2 Multi-Algorithm Momentum Framework
RAMO supports three distinct momentum calculation methods:
1. Rate of Change: Traditional percentage-based momentum (Pring, 2002)
2. Price Momentum: Absolute price differences
3. Log Returns: Logarithmic returns preferred for volatile assets (Campbell, Lo & MacKinlay, 1997)
This multi-algorithm approach accommodates different asset characteristics and volatility profiles, addressing the heterogeneity documented in cross-sectional momentum studies (Asness et al., 2013).
### 3.2 Leading Indicator Components
#### 3.2.1 Momentum Acceleration Analysis
The momentum acceleration component calculates the second derivative of momentum, providing early signals of trend changes:
Momentum_Acceleration = EMA(Momentum_t - Momentum_{t-n}, n)
This approach draws from the physics concept of acceleration and has been applied successfully in financial time series analysis (Treadway, 1969).
#### 3.2.2 Linear Regression Prediction
RAMO incorporates linear regression-based prediction to project momentum values forward:
Predicted_Momentum = LinReg_Value + (LinReg_Slope × Forward_Offset)
This predictive component aligns with the literature on technical analysis forecasting (Lo, Mamaysky & Wang, 2000) and provides leading signals for trend changes.
#### 3.2.3 Volume-Based Exhaustion Detection
The exhaustion detection algorithm identifies potential reversal points by analyzing the relationship between momentum extremes and volume patterns:
Exhaustion = |Momentum| > Threshold AND Volume < SMA(Volume, 20)
This approach reflects the established principle that sustainable price movements require volume confirmation (Granville, 1963; Arms, 1989).
### 3.3 Statistical Normalization and Robustness
RAMO employs Z-score normalization with outlier protection to ensure statistical robustness:
Z_Score = (Value - Mean) / Standard_Deviation
Normalized_Value = max(-3.5, min(3.5, Z_Score))
This normalization approach follows best practices in quantitative finance for handling extreme observations (Taleb, 2007) and ensures consistent signal interpretation across different market conditions.
### 3.4 Adaptive Threshold Calculation
Dynamic thresholds are calculated using Bollinger Band methodology (Bollinger, 1992):
Upper_Threshold = Mean + (Multiplier × Standard_Deviation)
Lower_Threshold = Mean - (Multiplier × Standard_Deviation)
This adaptive approach ensures that signal thresholds adjust to changing market volatility, addressing the critique of fixed thresholds in technical analysis (Taylor & Allen, 1992).
## 4. Implementation Details
### 4.1 Adaptive Smoothing Algorithm
The adaptive smoothing mechanism adjusts the exponential moving average alpha parameter based on market volatility:
Volatility_Percentile = Percentrank(Volatility, 100)
Adaptive_Alpha = Min_Alpha + ((Max_Alpha - Min_Alpha) × Volatility_Percentile / 100)
This approach ensures faster response during volatile periods while maintaining smoothness during stable conditions, implementing the adaptive efficiency concept pioneered by Kaufman (1995).
### 4.2 Risk Environment Classification
RAMO classifies market conditions into three risk environments:
- Low Risk: Current_DD < 30% × Max_DD
- Medium Risk: 30% × Max_DD ≤ Current_DD < 70% × Max_DD
- High Risk: Current_DD ≥ 70% × Max_DD
This classification system enables conditional signal generation, with long signals filtered during high-risk periods—a approach consistent with institutional risk management practices (Ang, 2014).
## 5. Signal Generation and Interpretation
### 5.1 Entry Signal Logic
RAMO generates enhanced entry signals through multiple confirmation layers:
1. Primary Signal: Crossover between indicator and signal line
2. Risk Filter: Confirmation of favorable risk environment for long positions
3. Leading Component: Early warning signals via acceleration analysis
4. Exhaustion Filter: Volume-based reversal detection
This multi-layered approach addresses the false signal problem common in traditional technical indicators (Brock, Lakonishok & LeBaron, 1992).
### 5.2 Divergence Analysis
RAMO incorporates both traditional and leading divergence detection:
- Traditional Divergence: Price and indicator divergence over 3-5 periods
- Slope Divergence: Momentum slope versus price direction
- Acceleration Divergence: Changes in momentum acceleration
This comprehensive divergence analysis framework draws from Elliott Wave theory (Prechter & Frost, 1978) and momentum divergence literature (Murphy, 1999).
## 6. Empirical Advantages and Applications
### 6.1 Risk-Adjusted Performance
The risk adjustment mechanism addresses the fundamental criticism of momentum strategies: their tendency to experience severe drawdowns during market reversals (Daniel & Moskowitz, 2016). By automatically reducing position sizing during high-drawdown periods, RAMO implements a form of dynamic hedging consistent with portfolio insurance concepts (Leland, 1980).
### 6.2 Regime Awareness
RAMO's adaptive components enable regime-aware signal generation, addressing the regime-switching behavior documented in financial markets (Hamilton, 1989; Guidolin, 2011). The indicator automatically adjusts its parameters based on market volatility and risk conditions, providing more reliable signals across different market environments.
### 6.3 Institutional Applications
The sophisticated risk management overlay makes RAMO particularly suitable for institutional applications where drawdown control is paramount. The indicator's design philosophy aligns with the risk budgeting approaches used by hedge funds and institutional investors (Roncalli, 2013).
## 7. Limitations and Future Research
### 7.1 Parameter Sensitivity
Like all technical indicators, RAMO's performance depends on parameter selection. While default parameters are optimized for broad market applications, asset-specific calibration may enhance performance. Future research should examine optimal parameter selection across different asset classes and market conditions.
### 7.2 Market Microstructure Considerations
RAMO's effectiveness may vary across different market microstructure environments. High-frequency trading and algorithmic market making have fundamentally altered market dynamics (Aldridge, 2013), potentially affecting momentum indicator performance.
### 7.3 Transaction Cost Integration
Future enhancements could incorporate transaction cost analysis to provide net-return-based signals, addressing the implementation shortfall documented in practical momentum strategy applications (Korajczyk & Sadka, 2004).
## References
Aldridge, I. (2013). *High-Frequency Trading: A Practical Guide to Algorithmic Strategies and Trading Systems*. 2nd ed. Hoboken, NJ: John Wiley & Sons.
Ang, A. (2014). *Asset Management: A Systematic Approach to Factor Investing*. New York: Oxford University Press.
Arms, R. W. (1989). *The Arms Index (TRIN): An Introduction to the Volume Analysis of Stock and Bond Markets*. Homewood, IL: Dow Jones-Irwin.
Asness, C. S., Moskowitz, T. J., & Pedersen, L. H. (2013). Value and momentum everywhere. *Journal of Finance*, 68(3), 929-985.
Barroso, P., & Santa-Clara, P. (2015). Momentum has its moments. *Journal of Financial Economics*, 116(1), 111-120.
Bollinger, J. (1992). *Bollinger on Bollinger Bands*. New York: McGraw-Hill.
Brock, W., Lakonishok, J., & LeBaron, B. (1992). Simple technical trading rules and the stochastic properties of stock returns. *Journal of Finance*, 47(5), 1731-1764.
Calmar, T. (1991). The Calmar ratio: A smoother tool. *Futures*, 20(1), 40.
Campbell, J. Y., Lo, A. W., & MacKinlay, A. C. (1997). *The Econometrics of Financial Markets*. Princeton, NJ: Princeton University Press.
Chekhlov, A., Uryasev, S., & Zabarankin, M. (2005). Drawdown measure in portfolio optimization. *International Journal of Theoretical and Applied Finance*, 8(1), 13-58.
Daniel, K., & Moskowitz, T. J. (2016). Momentum crashes. *Journal of Financial Economics*, 122(2), 221-247.
Fama, E. F., & French, K. R. (1996). Multifactor explanations of asset pricing anomalies. *Journal of Finance*, 51(1), 55-84.
Granville, J. E. (1963). *Granville's New Key to Stock Market Profits*. Englewood Cliffs, NJ: Prentice-Hall.
Guidolin, M. (2011). Markov switching models in empirical finance. In D. N. Drukker (Ed.), *Missing Data Methods: Time-Series Methods and Applications* (pp. 1-86). Bingley: Emerald Group Publishing.
Hamilton, J. D. (1989). A new approach to the economic analysis of nonstationary time series and the business cycle. *Econometrica*, 57(2), 357-384.
Jegadeesh, N., & Titman, S. (1993). Returns to buying winners and selling losers: Implications for stock market efficiency. *Journal of Finance*, 48(1), 65-91.
Kahneman, D., & Tversky, A. (1979). Prospect theory: An analysis of decision under risk. *Econometrica*, 47(2), 263-291.
Kaufman, P. J. (1995). *Smarter Trading: Improving Performance in Changing Markets*. New York: McGraw-Hill.
Korajczyk, R. A., & Sadka, R. (2004). Are momentum profits robust to trading costs? *Journal of Finance*, 59(3), 1039-1082.
Leland, H. E. (1980). Who should buy portfolio insurance? *Journal of Finance*, 35(2), 581-594.
Lo, A. W., Mamaysky, H., & Wang, J. (2000). Foundations of technical analysis: Computational algorithms, statistical inference, and empirical implementation. *Journal of Finance*, 55(4), 1705-1765.
Markowitz, H. (1952). Portfolio selection. *Journal of Finance*, 7(1), 77-91.
Murphy, J. J. (1999). *Technical Analysis of the Financial Markets: A Comprehensive Guide to Trading Methods and Applications*. New York: New York Institute of Finance.
Prechter, R. R., & Frost, A. J. (1978). *Elliott Wave Principle: Key to Market Behavior*. Gainesville, GA: New Classics Library.
Pring, M. J. (2002). *Technical Analysis Explained: The Successful Investor's Guide to Spotting Investment Trends and Turning Points*. 4th ed. New York: McGraw-Hill.
Roncalli, T. (2013). *Introduction to Risk Parity and Budgeting*. Boca Raton, FL: CRC Press.
Shefrin, H., & Statman, M. (1985). The disposition to sell winners too early and ride losers too long: Theory and evidence. *Journal of Finance*, 40(3), 777-790.
Taleb, N. N. (2007). *The Black Swan: The Impact of the Highly Improbable*. New York: Random House.
Taylor, M. P., & Allen, H. (1992). The use of technical analysis in the foreign exchange market. *Journal of International Money and Finance*, 11(3), 304-314.
Treadway, A. B. (1969). On rational entrepreneurial behavior and the demand for investment. *Review of Economic Studies*, 36(2), 227-239.
Wilder, J. W. (1978). *New Concepts in Technical Trading Systems*. Greensboro, NC: Trend Research.
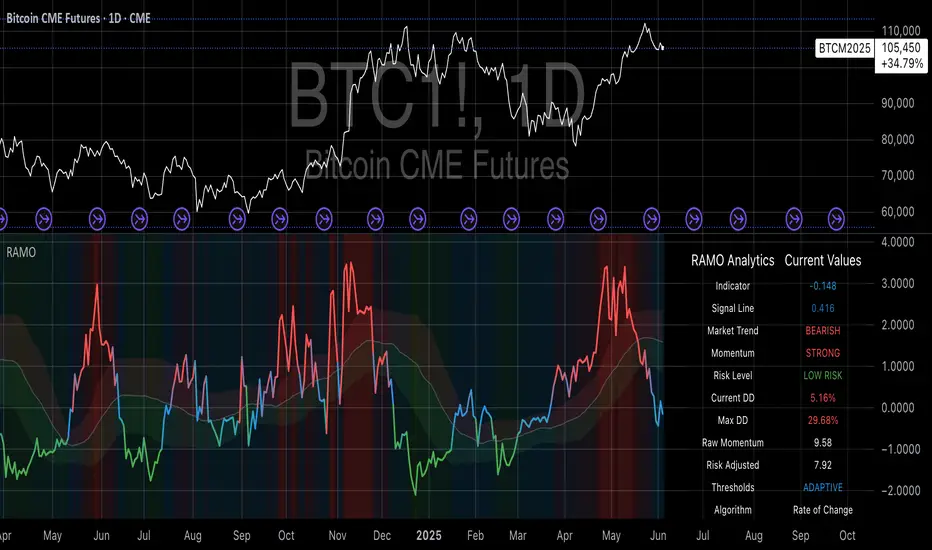
TrendMaster Pro 2.3 with Alerts
Hello friends,
A member of the community approached me and asked me how to write an indicator that would achieve a particular set of goals involving comprehensive trend analysis, risk management, and session-based trading controls. Here is one example method of how to create such a system:
Core Strategy Components
Multi-Moving Average System - Uses configurable MA types (EMA, SMA, SMMA) with short-term (9) and long-term (21) periods for primary signal generation through crossovers
Higher Timeframe Trend Filter - Optional trend confirmation using a separate MA (default 50-period) to ensure trades align with broader market direction
Band Power Indicator - Dynamic high/low bands calculated using different MA types to identify price channels and volatility zones
Advanced Signal Filtering
Bollinger Bands Volatility Filter - Prevents trading during low-volatility ranging markets by requiring sufficient band width
RSI Momentum Filter - Uses customizable thresholds (55 for longs, 45 for shorts) to confirm momentum direction
MACD Trend Confirmation - Ensures MACD line position relative to signal line aligns with trade direction
Stochastic Oscillator - Adds momentum confirmation with overbought/oversold levels
ADX Strength Filter - Only allows trades when trend strength exceeds 25 threshold
Session-Based Trading Management
Four Trading Sessions - Asia (18:00-00:00), London (00:00-08:00), NY AM (08:00-13:00), NY PM (13:00-18:00)
Individual Session Limits - Separate maximum trade counts for each session (default 5 per session)
Automatic Session Closure - All positions close at specified market close time
Risk Management Features
Multiple Stop Loss Options - Percentage-based, MA cross, or band-based SL methods
Risk/Reward Ratio - Configurable TP levels based on SL distance (default 1:2)
Auto-Risk Calculation - Dynamic position sizing based on dollar risk limits ($150-$250 range)
Daily Limits - Stop trading after reaching specified TP or SL counts per day
Support & Resistance System
Multiple Pivot Types - Traditional, Fibonacci, Woodie, Classic, DM, and Camarilla calculations
Flexible Timeframes - Auto-adjusting or manual timeframe selection for S/R levels
Historical Levels - Configurable number of past S/R levels to display
Visual Customization - Individual color and display settings for each S/R level
Additional Features
Alert System - Customizable buy/sell alert messages with once-per-bar frequency
Visual Trade Management - Color-coded entry, SL, and TP levels with fill areas
Session Highlighting - Optional background colors for different trading sessions
Comprehensive Filtering - All signals must pass through multiple confirmation layers before execution
This approach demonstrates how to build a professional-grade trading system that combines multiple technical analysis methods with robust risk management and session-based controls, suitable for algorithmic trading across different market sessions.
Good luck and stay safe!
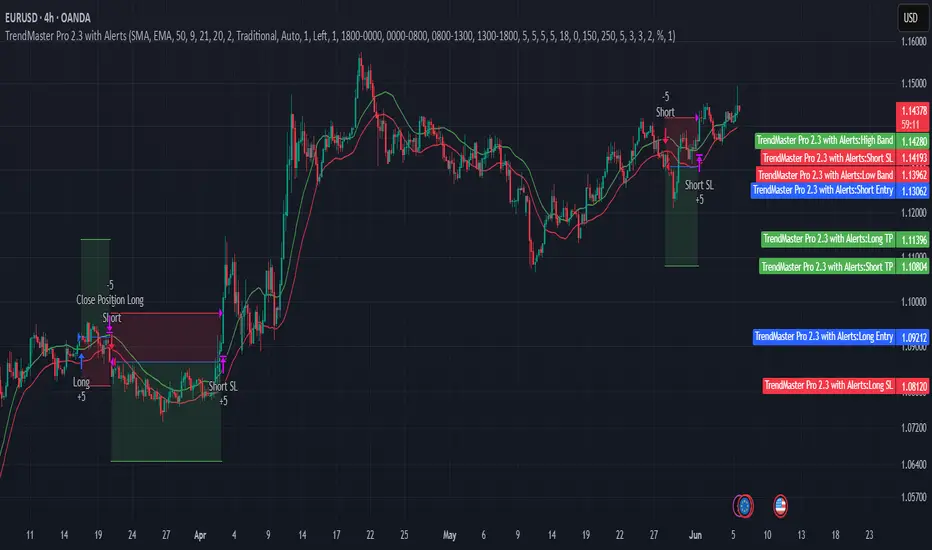
Support and Resistance Logistic Regression | Flux Charts💎 GENERAL OVERVIEW
Introducing our new Logistic Regression Support / Resistance indicator! This tool leverages advanced statistical modeling "Logistic Regressions" to identify and project key price levels where the market is likely to find support or resistance. For more information about the process, please check the "HOW DOES IT WORK ?" section.
Logistic Regression Support / Resistance Features :
Intelligent S/R Identification : The indicator uses a logistic regression model to intelligently identify and plot significant support and resistance levels.
Predictive Probability : Each identified level comes with a calculated probability, indicating how likely it is to act as a true support or resistance based on historical data.
Retest & Break Labels : The indicator clearly marks on your chart when a detected support or resistance level is retested (price touches and respects the level) or broken (price decisively crosses through the level).
Alerts : Real-time alerts for support retests, resistance retests, support breaks, and resistance breaks.
Customizable : You can change support & resistance line style, width and colors.
🚩 UNIQUENESS
What makes this indicator truly unique is its application of logistic regression to the concept of support and resistance. Instead of merely identifying historical highs and lows, our indicator uses a statistical model to predict the future efficacy of these levels. It analyzes underlying market conditions (like RSI and body size at pivot formation) to assign a probability to each potential S/R zone. This predictive insight, combined with dynamic, real-time labeling of retests and breaks, provides a more robust and adaptive understanding of market structure than traditional, purely historical methods.
📌HOW DOES IT WORK ?
The Logistic Regression Support / Resistance indicator operates in several key steps:
First, it identifies significant pivot highs and lows on the chart based on a user-defined "Pivot Length." These pivots are potential areas of support or resistance.
For each detected pivot, the indicator extracts relevant market data at that specific point, including the RSI (Relative Strength Index) and the Body Size (the absolute difference between the open and close price of the candle). These serve as input features for the model.
The core of the indicator lies in its logistic regression model. This model is continuously trained on past pivot data and their subsequent behavior (i.e., whether they were "respected" as support/resistance multiple times). It learns the relationship between the extracted features (RSI, Body Size) and the likelihood of a pivot becoming a significant S/R level.
When a new pivot is identified, the model uses its learned insights to calculate a prediction value—a probability (from 0 to 1) that this specific pivot will act as a strong support or resistance.
If the calculated probability exceeds a user-defined "Probability Threshold," the pivot is designated a "Regression Pivot" and drawn on the chart as a support or resistance line. The indicator then actively tracks how price interacts with these levels, displaying "R" labels for retests when the price bounces off the level and "B" labels for breaks when the price closes beyond it.
⚙️ SETTINGS
1. General Configuration
Pivot Length: This setting defines the number of bars used to determine a significant high or low for pivot detection.
Target Respects: This input specifies how many times a level must be "respected" by price action for it to be considered a strong support or resistance level by the underlying model.
Probability Threshold: This is the minimum probability output from the logistic regression model for a detected pivot to be considered a valid support or resistance level and be plotted on the chart.
2. Style
Show Prediction Labels: Enable or disable labels that display the calculated probability of a newly identified regression S/R level.
Show Retests: Toggle the visibility of "R" labels on the chart, which mark instances where price has retested a support or resistance level.
Show Breaks: Toggle the visibility of "B" labels on the chart, which mark instances where price has broken through a support or resistance level.
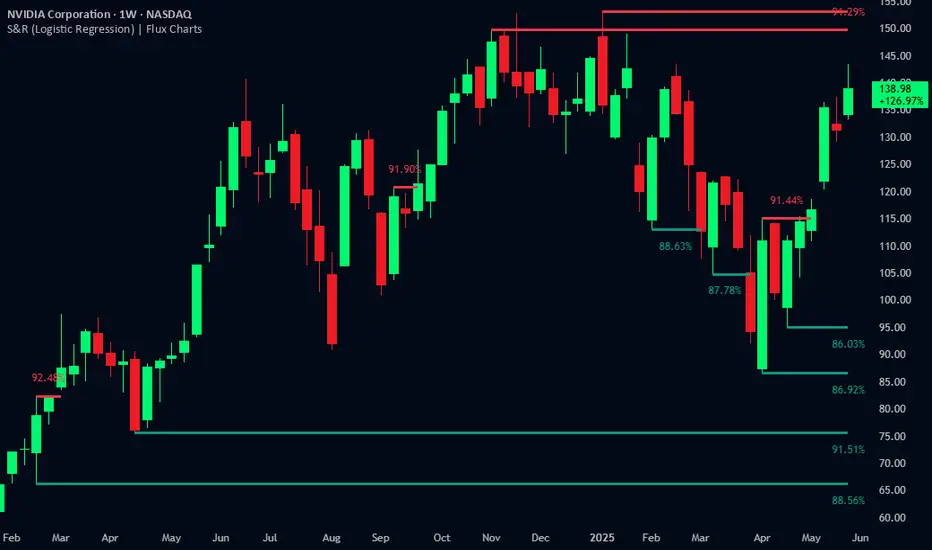
Mandelbrot-Fibonacci Cascade Vortex (MFCV)Mandelbrot-Fibonacci Cascade Vortex (MFCV) - Where Chaos Theory Meets Sacred Geometry
A Revolutionary Synthesis of Fractal Mathematics and Golden Ratio Dynamics
What began as an exploration into Benoit Mandelbrot's fractal market hypothesis and the mysterious appearance of Fibonacci sequences in nature has culminated in a groundbreaking indicator that reveals the hidden mathematical structure underlying market movements. This indicator represents months of research into chaos theory, fractal geometry, and the golden ratio's manifestation in financial markets.
The Theoretical Foundation
Mandelbrot's Fractal Market Hypothesis Traditional efficient market theory assumes normal distributions and random walks. Mandelbrot proved markets are fractal - self-similar patterns repeating across all timeframes with power-law distributions. The MFCV implements this through:
Hurst Exponent Calculation: H = log(R/S) / log(n/2)
Where:
R = Range of cumulative deviations
S = Standard deviation
n = Period length
This measures market memory:
H > 0.5: Trending (persistent) behavior
H = 0.5: Random walk
H < 0.5: Mean-reverting (anti-persistent) behavior
Fractal Dimension: D = 2 - H
This quantifies market complexity, where higher dimensions indicate more chaotic behavior.
Fibonacci Vortex Theory Markets don't move linearly - they spiral. The MFCV reveals these spirals using Fibonacci sequences:
Vortex Calculation: Vortex(n) = Price + sin(bar_index × φ / Fn) × ATR(Fn) × Volume_Factor
Where:
φ = 0.618 (golden ratio)
Fn = Fibonacci number (8, 13, 21, 34, 55)
Volume_Factor = 1 + (Volume/SMA(Volume,50) - 1) × 0.5
This creates oscillating spirals that contract and expand with market energy.
The Volatility Cascade System
Markets exhibit volatility clustering - Mandelbrot's "Noah Effect." The MFCV captures this through cascading volatility bands:
Cascade Level Calculation: Level(i) = ATR(20) × φ^i
Each level represents a different fractal scale, creating a multi-dimensional view of market structure. The golden ratio spacing ensures harmonic resonance between levels.
Implementation Architecture
Core Components:
Fractal Analysis Engine
Calculates Hurst exponent over user-defined periods
Derives fractal dimension for complexity measurement
Identifies market regime (trending/ranging/chaotic)
Fibonacci Vortex Generator
Creates 5 independent spiral oscillators
Each spiral follows a Fibonacci period
Volume amplification creates dynamic response
Cascade Band System
Up to 8 volatility levels
Golden ratio expansion between levels
Dynamic coloring based on fractal state
Confluence Detection
Identifies convergence of vortex and cascade levels
Highlights high-probability reversal zones
Real-time confluence strength calculation
Signal Generation Logic
The MFCV generates two primary signal types:
Fractal Signals: Generated when:
Hurst > 0.65 (strong trend) AND volatility expanding
Hurst < 0.35 (mean reversion) AND RSI < 35
Trend strength > 0.4 AND vortex alignment
Cascade Signals: Triggered by:
RSI > 60 AND price > SMA(50) AND bearish vortex
RSI < 40 AND price < SMA(50) AND bullish vortex
Volatility expansion AND trend strength > 0.3
Both signals implement a 15-bar cooldown to prevent overtrading.
Advanced Input System
Mandelbrot Parameters:
Cascade Levels (3-8):
Controls number of volatility bands
Crypto: 5-7 (high volatility)
Indices: 4-5 (moderate volatility)
Forex: 3-4 (low volatility)
Hurst Period (20-200):
Lookback for fractal calculation
Scalping: 20-50
Day Trading: 50-100
Swing Trading: 100-150
Position Trading: 150-200
Cascade Ratio (1.0-3.0):
Band width multiplier
1.618: Golden ratio (default)
Higher values for trending markets
Lower values for ranging markets
Fractal Memory (21-233):
Fibonacci retracement lookback
Uses Fibonacci numbers for harmonic alignment
Fibonacci Vortex Settings:
Spiral Periods:
Comma-separated Fibonacci sequence
Fast: "5,8,13,21,34" (scalping)
Standard: "8,13,21,34,55" (balanced)
Extended: "13,21,34,55,89" (swing)
Rotation Speed (0.1-2.0):
Controls spiral oscillation frequency
0.618: Golden ratio (balanced)
Higher = more signals, more noise
Lower = smoother, fewer signals
Volume Amplification:
Enables dynamic spiral expansion
Essential for stocks and crypto
Disable for forex (no central volume)
Visual System Architecture
Cascade Bands:
Multi-level volatility envelopes
Gradient coloring from primary to secondary theme
Transparency increases with distance from price
Fill between bands shows fractal structure
Vortex Spirals:
5 Fibonacci-period oscillators
Blue above price (bullish pressure)
Red below price (bearish pressure)
Multiple display styles: Lines, Circles, Dots, Cross
Dynamic Fibonacci Levels:
Auto-updating retracement levels
Smart update logic prevents disruption near levels
Distance-based transparency (closer = more visible)
Updates every 50 bars or on volatility spikes
Confluence Zones:
Highlighted boxes where indicators converge
Stronger confluence = stronger support/resistance
Key areas for reversal trades
Professional Dashboard System
Main Fractal Dashboard: Displays real-time:
Hurst Exponent with market state
Fractal Dimension with complexity level
Volatility Cascade status
Vortex rotation impact
Market regime classification
Signal strength percentage
Active indicator levels
Vortex Metrics Panel: Shows:
Individual spiral deviations
Convergence/divergence metrics
Real-time vortex positioning
Fibonacci period performance
Fractal Metrics Display: Tracks:
Dimension D value
Market complexity rating
Self-similarity strength
Trend quality assessment
Theory Guide Panel: Educational reference showing:
Mandelbrot principles
Fibonacci vortex concepts
Dynamic trading suggestions
Trading Applications
Trend Following:
High Hurst (>0.65) indicates strong trends
Follow cascade band direction
Use vortex spirals for entry timing
Exit when Hurst drops below 0.5
Mean Reversion:
Low Hurst (<0.35) signals reversal potential
Trade toward vortex spiral convergence
Use Fibonacci levels as targets
Tighten stops in chaotic regimes
Breakout Trading:
Monitor cascade band compression
Watch for vortex spiral alignment
Volatility expansion confirms breakouts
Use confluence zones for targets
Risk Management:
Position size based on fractal dimension
Wider stops in high complexity markets
Tighter stops when Hurst is extreme
Scale out at Fibonacci levels
Market-Specific Optimization
Cryptocurrency:
Cascade Levels: 5-7
Hurst Period: 50-100
Rotation Speed: 0.786-1.2
Enable volume amplification
Stock Indices:
Cascade Levels: 4-5
Hurst Period: 80-120
Rotation Speed: 0.5-0.786
Moderate cascade ratio
Forex:
Cascade Levels: 3-4
Hurst Period: 100-150
Rotation Speed: 0.382-0.618
Disable volume amplification
Commodities:
Cascade Levels: 4-6
Hurst Period: 60-100
Rotation Speed: 0.5-1.0
Seasonal adjustment consideration
Innovation and Originality
The MFCV represents several breakthrough innovations:
First Integration of Mandelbrot Fractals with Fibonacci Vortex Theory
Unique synthesis of chaos theory and sacred geometry
Novel application of Hurst exponent to spiral dynamics
Dynamic Volatility Cascade System
Golden ratio-based band expansion
Multi-timeframe fractal analysis
Self-adjusting to market conditions
Volume-Amplified Vortex Spirals
Revolutionary spiral calculation method
Dynamic response to market participation
Multiple Fibonacci period integration
Intelligent Signal Generation
Cooldown system prevents overtrading
Multi-factor confirmation required
Regime-aware signal filtering
Professional Analytics Dashboard
Institutional-grade metrics display
Real-time fractal analysis
Educational integration
Development Journey
Creating the MFCV involved overcoming numerous challenges:
Mathematical Complexity: Implementing Hurst exponent calculations efficiently
Visual Clarity: Displaying multiple indicators without cluttering
Performance Optimization: Managing array operations and calculations
Signal Quality: Balancing sensitivity with reliability
User Experience: Making complex theory accessible
The result is an indicator that brings PhD-level mathematics to practical trading while maintaining visual elegance and usability.
Best Practices and Guidelines
Start Simple: Use default settings initially
Match Timeframe: Adjust parameters to your trading style
Confirm Signals: Never trade MFCV signals in isolation
Respect Regimes: Adapt strategy to market state
Manage Risk: Use fractal dimension for position sizing
Color Themes
Six professional themes included:
Fractal: Balanced blue/purple palette
Golden: Warm Fibonacci-inspired colors
Plasma: Vibrant modern aesthetics
Cosmic: Dark mode optimized
Matrix: Classic green terminal
Fire: Heat map visualization
Disclaimer
This indicator is for educational and research purposes only. It does not constitute financial advice. While the MFCV reveals deep market structure through advanced mathematics, markets remain inherently unpredictable. Past performance does not guarantee future results.
The integration of Mandelbrot's fractal theory with Fibonacci vortex dynamics provides unique market insights, but should be used as part of a comprehensive trading strategy. Always use proper risk management and never risk more than you can afford to lose.
Acknowledgments
Special thanks to Benoit Mandelbrot for revolutionizing our understanding of markets through fractal geometry, and to the ancient mathematicians who discovered the golden ratio's universal significance.
"The geometry of nature is fractal... Markets are fractal too." - Benoit Mandelbrot
Revealing the Hidden Order in Market Chaos Trade with Mathematical Precision. Trade with MFCV.
— Created with passion for the TradingView community
Trade with insight. Trade with anticipation.
— Dskyz , for DAFE Trading Systems

EMD Trend [InvestorUnknown]EMD Trend is a dynamic trend-following indicator that utilizes Exponential Moving Deviation (EMD) to build adaptive channels around a selected moving average. Designed for traders who value responsive trend signals with built-in volatility sensitivity, this tool highlights directional bias, market regime shifts, and potential breakout opportunities.
How It Works
Instead of using standard deviation, EMD Trend employs the exponential moving average of the absolute deviation from a moving average—producing smoother, faster-reacting upper and lower bounds:
Bullish (Risk-ON Long): Price crosses above the upper EMD band
Bearish (Risk-ON Short): Price crosses below the lower EMD band
Neutral: Price stays within the channel, indicating potential mean reversion or low momentum
Trend direction is defined by price interaction with these bands, and visual cues (color-coded bars and fills) help quickly identify market conditions.
Features
7 Moving Average Types: SMA, EMA, HMA, DEMA, TEMA, RMA, FRAMA
Custom Price Source: Choose close, hl2, ohlc4, or others
EMD Multiplier: Controls the width of the deviation envelope
Bar Coloring: Candles change color based on current trend
Intra-bar Signal Option: Enables faster updates (with optional repainting)
Speculative Zones: Fills highlight aggressive momentum moves beyond EMD bounds
Backtest Mode
Switch to Backtest Mode for performance evaluation over historical data:
Equity Curve Plot: Compare EMD Trend strategy vs. Buy & Hold
Trade Metrics Table: View number of trades, win/loss stats, profits
Performance Metrics Table: Includes CAGR, Sharpe, max drawdown, and more
Custom Start Date: Select from which date the backtest should begin
Trade Sizing: Configure capital and trade percentage per entry
Signal Filters: Choose from Long Only, Short Only, or Both
Alerts
Built-in alerts let you automate entries, exits, and trend transitions:
LONG (EMD Trend) - Trend flips to Long
SHORT (EMD Trend) - Trend flips to Short
RISK-ON LONG - Price crosses above upper EMD band
RISK-OFF LONG - Price crosses back below upper EMD band
RISK-ON SHORT - Price crosses below lower EMD band
RISK-OFF SHORT - Price crosses back above lower EMD band
Use Cases
Trend Confirmation with volatility-sensitive boundaries
Momentum Entry Filtering via breakout zones
Mean Reversion Avoidance in sideways markets
Backtesting & Strategy Building with real-time metrics
Disclaimer
This indicator is intended for informational and educational purposes only. It does not constitute investment advice. Historical performance does not guarantee future results. Always backtest and use in simulation before live trading.

Bear Market Probability Model# Bear Market Probability Model: A Multi-Factor Risk Assessment Framework
The Bear Market Probability Model represents a comprehensive quantitative framework for assessing systemic market risk through the integration of 13 distinct risk factors across four analytical categories: macroeconomic indicators, technical analysis factors, market sentiment measures, and market breadth metrics. This indicator synthesizes established financial research methodologies to provide real-time probabilistic assessments of impending bear market conditions, offering institutional-grade risk management capabilities to retail and professional traders alike.
## Theoretical Foundation
### Historical Context of Bear Market Prediction
Bear market prediction has been a central focus of financial research since the seminal work of Dow (1901) and the subsequent development of technical analysis theory. The challenge of predicting market downturns gained renewed academic attention following the market crashes of 1929, 1987, 2000, and 2008, leading to the development of sophisticated multi-factor models.
Fama and French (1989) demonstrated that certain financial variables possess predictive power for stock returns, particularly during market stress periods. Their three-factor model laid the groundwork for multi-dimensional risk assessment, which this indicator extends through the incorporation of real-time market microstructure data.
### Methodological Framework
The model employs a weighted composite scoring methodology based on the theoretical framework established by Campbell and Shiller (1998) for market valuation assessment, extended through the incorporation of high-frequency sentiment and technical indicators as proposed by Baker and Wurgler (2006) in their seminal work on investor sentiment.
The mathematical foundation follows the general form:
Bear Market Probability = Σ(Wi × Ci) / ΣWi × 100
Where:
- Wi = Category weight (i = 1,2,3,4)
- Ci = Normalized category score
- Categories: Macroeconomic, Technical, Sentiment, Breadth
## Component Analysis
### 1. Macroeconomic Risk Factors
#### Yield Curve Analysis
The inclusion of yield curve inversion as a primary predictor follows extensive research by Estrella and Mishkin (1998), who demonstrated that the term spread between 3-month and 10-year Treasury securities has historically preceded all major recessions since 1969. The model incorporates both the 2Y-10Y and 3M-10Y spreads to capture different aspects of monetary policy expectations.
Implementation:
- 2Y-10Y Spread: Captures market expectations of monetary policy trajectory
- 3M-10Y Spread: Traditional recession predictor with 12-18 month lead time
Scientific Basis: Harvey (1988) and subsequent research by Ang, Piazzesi, and Wei (2006) established the theoretical foundation linking yield curve inversions to economic contractions through the expectations hypothesis of the term structure.
#### Credit Risk Premium Assessment
High-yield credit spreads serve as a real-time gauge of systemic risk, following the methodology established by Gilchrist and Zakrajšek (2012) in their excess bond premium research. The model incorporates the ICE BofA High Yield Master II Option-Adjusted Spread as a proxy for credit market stress.
Threshold Calibration:
- Normal conditions: < 350 basis points
- Elevated risk: 350-500 basis points
- Severe stress: > 500 basis points
#### Currency and Commodity Stress Indicators
The US Dollar Index (DXY) momentum serves as a risk-off indicator, while the Gold-to-Oil ratio captures commodity market stress dynamics. This approach follows the methodology of Akram (2009) and Beckmann, Berger, and Czudaj (2015) in analyzing commodity-currency relationships during market stress.
### 2. Technical Analysis Factors
#### Multi-Timeframe Moving Average Analysis
The technical component incorporates the well-established moving average convergence methodology, drawing from the work of Brock, Lakonishok, and LeBaron (1992), who provided empirical evidence for the profitability of technical trading rules.
Implementation:
- Price relative to 50-day and 200-day simple moving averages
- Moving average convergence/divergence analysis
- Multi-timeframe MACD assessment (daily and weekly)
#### Momentum and Volatility Analysis
The model integrates Relative Strength Index (RSI) analysis following Wilder's (1978) original methodology, combined with maximum drawdown analysis based on the work of Magdon-Ismail and Atiya (2004) on optimal drawdown measurement.
### 3. Market Sentiment Factors
#### Volatility Index Analysis
The VIX component follows the established research of Whaley (2009) and subsequent work by Bekaert and Hoerova (2014) on VIX as a predictor of market stress. The model incorporates both absolute VIX levels and relative VIX spikes compared to the 20-day moving average.
Calibration:
- Low volatility: VIX < 20
- Elevated concern: VIX 20-25
- High fear: VIX > 25
- Panic conditions: VIX > 30
#### Put-Call Ratio Analysis
Options flow analysis through put-call ratios provides insight into sophisticated investor positioning, following the methodology established by Pan and Poteshman (2006) in their analysis of informed trading in options markets.
### 4. Market Breadth Factors
#### Advance-Decline Analysis
Market breadth assessment follows the classic work of Fosback (1976) and subsequent research by Brown and Cliff (2004) on market breadth as a predictor of future returns.
Components:
- Daily advance-decline ratio
- Advance-decline line momentum
- McClellan Oscillator (Ema19 - Ema39 of A-D difference)
#### New Highs-New Lows Analysis
The new highs-new lows ratio serves as a market leadership indicator, based on the research of Zweig (1986) and validated in academic literature by Zarowin (1990).
## Dynamic Threshold Methodology
The model incorporates adaptive thresholds based on rolling volatility and trend analysis, following the methodology established by Pagan and Sossounov (2003) for business cycle dating. This approach allows the model to adjust sensitivity based on prevailing market conditions.
Dynamic Threshold Calculation:
- Warning Level: Base threshold ± (Volatility × 1.0)
- Danger Level: Base threshold ± (Volatility × 1.5)
- Bounds: ±10-20 points from base threshold
## Professional Implementation
### Institutional Usage Patterns
Professional risk managers typically employ multi-factor bear market models in several contexts:
#### 1. Portfolio Risk Management
- Tactical Asset Allocation: Reducing equity exposure when probability exceeds 60-70%
- Hedging Strategies: Implementing protective puts or VIX calls when warning thresholds are breached
- Sector Rotation: Shifting from growth to defensive sectors during elevated risk periods
#### 2. Risk Budgeting
- Value-at-Risk Adjustment: Incorporating bear market probability into VaR calculations
- Stress Testing: Using probability levels to calibrate stress test scenarios
- Capital Requirements: Adjusting regulatory capital based on systemic risk assessment
#### 3. Client Communication
- Risk Reporting: Quantifying market risk for client presentations
- Investment Committee Decisions: Providing objective risk metrics for strategic decisions
- Performance Attribution: Explaining defensive positioning during market stress
### Implementation Framework
Professional traders typically implement such models through:
#### Signal Hierarchy:
1. Probability < 30%: Normal risk positioning
2. Probability 30-50%: Increased hedging, reduced leverage
3. Probability 50-70%: Defensive positioning, cash building
4. Probability > 70%: Maximum defensive posture, short exposure consideration
#### Risk Management Integration:
- Position Sizing: Inverse relationship between probability and position size
- Stop-Loss Adjustment: Tighter stops during elevated risk periods
- Correlation Monitoring: Increased attention to cross-asset correlations
## Strengths and Advantages
### 1. Comprehensive Coverage
The model's primary strength lies in its multi-dimensional approach, avoiding the single-factor bias that has historically plagued market timing models. By incorporating macroeconomic, technical, sentiment, and breadth factors, the model provides robust risk assessment across different market regimes.
### 2. Dynamic Adaptability
The adaptive threshold mechanism allows the model to adjust sensitivity based on prevailing volatility conditions, reducing false signals during low-volatility periods and maintaining sensitivity during high-volatility regimes.
### 3. Real-Time Processing
Unlike traditional academic models that rely on monthly or quarterly data, this indicator processes daily market data, providing timely risk assessment for active portfolio management.
### 4. Transparency and Interpretability
The component-based structure allows users to understand which factors are driving risk assessment, enabling informed decision-making about model signals.
### 5. Historical Validation
Each component has been validated in academic literature, providing theoretical foundation for the model's predictive power.
## Limitations and Weaknesses
### 1. Data Dependencies
The model's effectiveness depends heavily on the availability and quality of real-time economic data. Federal Reserve Economic Data (FRED) updates may have lags that could impact model responsiveness during rapidly evolving market conditions.
### 2. Regime Change Sensitivity
Like most quantitative models, the indicator may struggle during unprecedented market conditions or structural regime changes where historical relationships break down (Taleb, 2007).
### 3. False Signal Risk
Multi-factor models inherently face the challenge of balancing sensitivity with specificity. The model may generate false positive signals during normal market volatility periods.
### 4. Currency and Geographic Bias
The model focuses primarily on US market indicators, potentially limiting its effectiveness for global portfolio management or non-USD denominated assets.
### 5. Correlation Breakdown
During extreme market stress, correlations between risk factors may increase dramatically, reducing the model's diversification benefits (Forbes and Rigobon, 2002).
## References
Akram, Q. F. (2009). Commodity prices, interest rates and the dollar. Energy Economics, 31(6), 838-851.
Ang, A., Piazzesi, M., & Wei, M. (2006). What does the yield curve tell us about GDP growth? Journal of Econometrics, 131(1-2), 359-403.
Baker, M., & Wurgler, J. (2006). Investor sentiment and the cross‐section of stock returns. The Journal of Finance, 61(4), 1645-1680.
Baker, S. R., Bloom, N., & Davis, S. J. (2016). Measuring economic policy uncertainty. The Quarterly Journal of Economics, 131(4), 1593-1636.
Barber, B. M., & Odean, T. (2001). Boys will be boys: Gender, overconfidence, and common stock investment. The Quarterly Journal of Economics, 116(1), 261-292.
Beckmann, J., Berger, T., & Czudaj, R. (2015). Does gold act as a hedge or a safe haven for stocks? A smooth transition approach. Economic Modelling, 48, 16-24.
Bekaert, G., & Hoerova, M. (2014). The VIX, the variance premium and stock market volatility. Journal of Econometrics, 183(2), 181-192.
Brock, W., Lakonishok, J., & LeBaron, B. (1992). Simple technical trading rules and the stochastic properties of stock returns. The Journal of Finance, 47(5), 1731-1764.
Brown, G. W., & Cliff, M. T. (2004). Investor sentiment and the near-term stock market. Journal of Empirical Finance, 11(1), 1-27.
Campbell, J. Y., & Shiller, R. J. (1998). Valuation ratios and the long-run stock market outlook. The Journal of Portfolio Management, 24(2), 11-26.
Dow, C. H. (1901). Scientific stock speculation. The Magazine of Wall Street.
Estrella, A., & Mishkin, F. S. (1998). Predicting US recessions: Financial variables as leading indicators. Review of Economics and Statistics, 80(1), 45-61.
Fama, E. F., & French, K. R. (1989). Business conditions and expected returns on stocks and bonds. Journal of Financial Economics, 25(1), 23-49.
Forbes, K. J., & Rigobon, R. (2002). No contagion, only interdependence: measuring stock market comovements. The Journal of Finance, 57(5), 2223-2261.
Fosback, N. G. (1976). Stock market logic: A sophisticated approach to profits on Wall Street. The Institute for Econometric Research.
Gilchrist, S., & Zakrajšek, E. (2012). Credit spreads and business cycle fluctuations. American Economic Review, 102(4), 1692-1720.
Harvey, C. R. (1988). The real term structure and consumption growth. Journal of Financial Economics, 22(2), 305-333.
Kahneman, D., & Tversky, A. (1979). Prospect theory: An analysis of decision under risk. Econometrica, 47(2), 263-291.
Magdon-Ismail, M., & Atiya, A. F. (2004). Maximum drawdown. Risk, 17(10), 99-102.
Nickerson, R. S. (1998). Confirmation bias: A ubiquitous phenomenon in many guises. Review of General Psychology, 2(2), 175-220.
Pagan, A. R., & Sossounov, K. A. (2003). A simple framework for analysing bull and bear markets. Journal of Applied Econometrics, 18(1), 23-46.
Pan, J., & Poteshman, A. M. (2006). The information in option volume for future stock prices. The Review of Financial Studies, 19(3), 871-908.
Taleb, N. N. (2007). The black swan: The impact of the highly improbable. Random House.
Whaley, R. E. (2009). Understanding the VIX. The Journal of Portfolio Management, 35(3), 98-105.
Wilder, J. W. (1978). New concepts in technical trading systems. Trend Research.
Zarowin, P. (1990). Size, seasonality, and stock market overreaction. Journal of Financial and Quantitative Analysis, 25(1), 113-125.
Zweig, M. E. (1986). Winning on Wall Street. Warner Books.
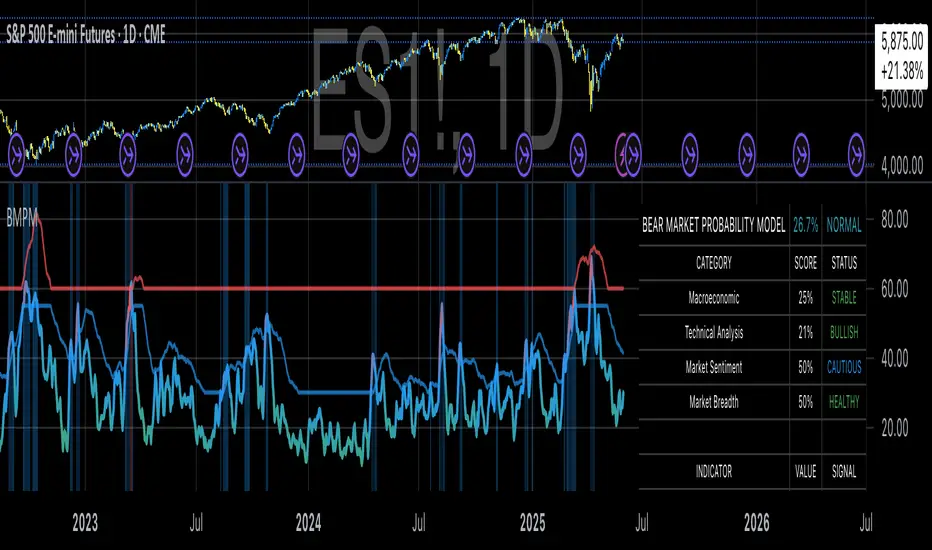
Range Filter [DW]This is an experimental study designed to filter out minor price action for a clearer view of trends.
Inspired by the QQE's volatility filter, this filter applies the process directly to price rather than to a smoothed RSI.
First, a smooth average price range is calculated for the basis of the filter and multiplied by a specified amount.
Next, the filter is calculated by gating price movements that do not exceed the specified range.
Lastly the target ranges are plotted to display the prices that will trigger filter movement.
Custom bar colors are included. The color scheme is based on the filtered price trend.
