Tìm kiếm tập lệnh với "ha溢价率"
HA VisualizerImposes Heiken Ashi values and colors onto pure candlestick charts.
Mostly just to provide you with the ability to see the real data while still being able to enjoy the benefits of Heiken Ashi candlesticks.


Minervini VCP Pattern -Indian ContextThis script implements Mark Minervini's Trend Template and VCP (Volatility Contraction Pattern) pattern, specifically adapted for Indian stock markets (NSE). It helps identify stocks that are in strong uptrends and ready to break out.
Core Concepts Explained
1. What is the Minervini Trend Template?
Mark Minervini's method identifies stocks in Stage 2 uptrends - the sweet spot where institutional money is accumulating and stocks show the strongest momentum. Think of it as finding stocks that are "leaders" rather than "laggards."
2. What is VCP (Volatility Contraction Pattern)?
A VCP occurs when:
Stock price consolidates (moves sideways) after an uptrend
Price swings get tighter and tighter (like a coiled spring)
Volume dries up (fewer people trading)
Then it breaks out with force.
You can customize the strategy settings without editing code.
Key Settings:
Minimum Price (₹50): Filters out penny stocks that are too volatile
Min Distance from 52W Low (30%): Stock should be at least 30% above its yearly low
Max Distance from 52W High (25%): Stock should be within 25% of its yearly high (showing strength)
Moving Average Periods: 10, 50, 150, 200 days (industry standard)
Minimum Volume (100,000 shares): Ensures the stock is liquid enough to trade
Indian Market Adaptation: The default values (₹50 minimum, volume thresholds) are adjusted for NSE stocks, which behave differently than US markets.
The script pulls weekly chart data even when you're viewing daily charts.
Why it matters: Weekly trends are more reliable than daily noise. Professional traders use weekly charts to confirm the bigger picture.
What are Moving Averages (MAs)?
Simple averages of closing prices over X days
They smooth out price action to show trends
Think of them as the "average cost" of buyers over different time periods
The 4 Key MAs:
10 MA (Fast): Very short-term trend
50 MA: Short to medium-term trend
150 MA: Medium to long-term trend
200 MA: Long-term trend (the "grandfather" of all MAs)
Why Weekly MAs?
The script also calculates 10 and 50 MAs on weekly data for additional confirmation of the bigger trend.
The script Finds the highest and lowest prices over the past 52 weeks (1 year).
Why it matters:
Stocks near 52-week highs are showing strength (institutions buying)
Stocks far from 52-week lows have "room to run" upward
This is a psychological level that influences trader behaviour.
What is Volume here ?
The number of shares traded each day
High volume = many traders interested (conviction)
Low volume = lack of interest (weakness or consolidation)
Volume in VCP:
During consolidation (sideways movement), volume should dry up - this shows sellers are exhausted and buyers are holding. When volume spikes on a breakout, it confirms the move.
NSE Context: Indian stocks often have different volume patterns than US stocks, so the 50-day average is used as a baseline.
Relative Strength vs Nifty:
Example:
If your stock is up 20% and Nifty is up 10%, your stock has strong RS
If your stock is up 5% and Nifty is up 15%, your stock has weak RS (avoid it!)
Why it matters: The best performing stocks almost always have strong relative strength before major moves.
The 13 Minervini Conditions:-
Condition 1: Price > 50/150/200 MA
Meaning: Current price must be above ALL three major moving averages.
Why: This confirms the stock is in a clear uptrend. If price is below these MAs, the stock is weak or in a downtrend.
Condition 2: MA 50 > 150 > 200
Meaning: The moving averages themselves must be in proper order.
Analogy: Think of this like layers in a cake - short-term on top, long-term at bottom. If they're tangled, the trend is unclear.
Condition 3: 200 MA Rising (1 Month)
Meaning: The 200 MA today must be higher than it was 20 days ago.
Why: This confirms the long-term trend is UP, not flat or down. The means "20 bars ago."
Condition 4: 50 MA Rising
Meaning: The 50 MA today must be higher than 5 days ago.
Why: Confirms short-term momentum is accelerating upward.
Condition 5: Within 25% of 52-Week High
Meaning: Current price should be within 25% of its 1-year high.
Example:
52-week high = ₹1000
Current price must be above ₹750 (within 25%)
Why: Strong stocks stay near their highs. Weak stocks fall far from highs.
Condition 6: 30%+ Above 52-Week Low (OPTIONAL)
Meaning: Stock should be at least 30% above its yearly low.
Note: The script marks this as "SECONDARY - Optional" because the other conditions are more important. However, it's still a good confirmation.
Condition 7: Price > 10 MA
Meaning: Very short-term strength - price above the 10-day moving average.
Why: Ensures the stock hasn't just rolled over in the immediate term.
Condition 8: Price >= ₹50
Meaning: Filters out stocks below ₹50.
Why: In Indian markets, stocks below ₹50 tend to be penny stocks with poor liquidity and higher manipulation risk.
Condition 9: Weekly Uptrend
Meaning: On the weekly chart, price must be above both weekly MAs, and they must be properly aligned.
Why: Confirms the bigger picture trend, not just daily fluctuations.
Condition 10: 150 MA Rising
Meaning: The 150 MA is trending upward over the past 10 days.
Why: Another confirmation of medium-term trend health.
Condition 11: Sufficient Volume
Meaning: Average volume must exceed 100,000 shares (or your custom setting).
Why: Ensures you can actually buy/sell the stock without moving the price too much (liquidity).
Condition 12: RS vs Nifty Strong
Meaning: The stock's relative strength vs Nifty must be improving.
Why: You want stocks that are outperforming the market, not underperforming.
Condition 13: Nifty in Uptrend
Meaning: The Nifty 50 index itself must be above its 50 MA.
Why: "A rising tide lifts all boats." It's easier to make money in individual stocks when the overall market is bullish.
VCP Requirements:
Volatility Contracting: Price swings getting tighter (coiling spring)
Volume Drying Up: Fewer shares trading + trending lower
The Setup: When volatility contracts and volume dries up WHILE all 13 trend conditions are met, you have a VCP setup ready to explode.
What You See on Chart:
Colored Lines: 10 MA (green), 50 MA (blue), 150 MA (orange), 200 MA (red)
Blue Background: Trend template conditions met (watch zone)
Green Background: Full VCP setup detected (buy zone)
↟ Symbol Below Price: New VCP buy signal just triggered
Information Table:
What it does: Creates a checklist table on your chart showing the status of all conditions.
Table Structure:
Column 1: Condition name
Column 2: Status (✓ green = met, ✗ red = not met)
Final Row: Shows "BUY" (green) or "WAIT" (red) based on full VCP setup status.
Dos:
Example:
Account size: ₹5,00,000
Risk per trade: 1% = ₹5,000
Entry: ₹1000
Stop loss: ₹920 (8% below)
Distance to stop: ₹80
Shares to buy: ₹5,000 / ₹80 = 62 shares
Exit Strategy:
Sell 1/3 at +20% profit
Sell another 1/3 at +40% profit
Let the final 1/3 run with a trailing stop
Always exit if price closes below 10 MA on heavy volume
What This Script Does NOT Do:
Guarantee profits - No strategy works 100% of the time
Account for news events - Earnings, regulatory changes, etc.
Consider fundamentals - Company financials, debt, management quality
Adapt to market crashes - Works best in bull markets
Best Market Conditions:
✅ Nifty in uptrend (above 50 MA)
✅ Market breadth positive (more stocks advancing)
✅ Sector rotation happening
❌ Avoid in bear markets or high volatility periods
References:
Trade Like a Stock Market Wizard by Mark Minervini
Think & Trade Like a Champion by Mark Minervini
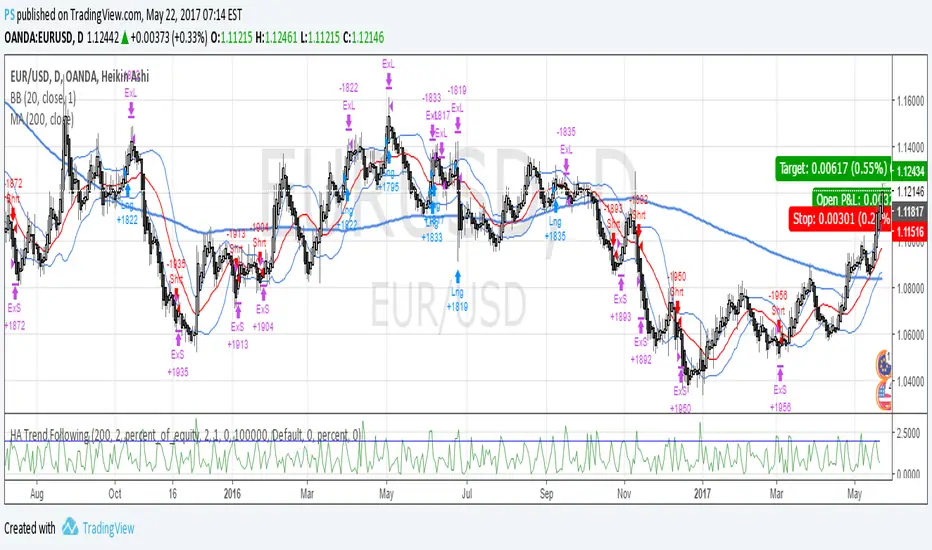
Chart attached: AU Small Finance Bank as on EoD dated 28/11/25
This script is a powerful tool for educational purpose only, remember: It's a tool, not a crystal ball. Use it to find high-probability setups, then apply proper risk management and patience. Good luck!

Previous/Current Day High/Low/Open/Close LevelsThis Pine Script creates a TradingView indicator that displays key price levels from previous and current trading days. Here's what it does:
Main Features
Price Level Display:
Previous Day High (PDH) - Highest price from yesterday
Previous Day Low (PDL) - Lowest price from yesterday
Previous Day Close (PDC) - Closing price from yesterday
Current Day Open (DO) - Opening price of today
Intraday High (IDH) - Highest price reached so far today
Intraday Low (IDL) - Lowest price reached so far today
Key Settings
Days Back - Shows levels for the last 1-30 days (default: 5 days)
Line Extension - Projects lines forward beyond the current candle (default: 25 bars)
Toggle Controls - Turn each level on/off individually
Customizable Colors - Each level has its own color (red for highs, green for lows, etc.)
Labels - Optional text labels (PDH, PDL, etc.) positioned on left or right side
How It Works
The script draws horizontal lines at these key price levels throughout the trading day. Lines break at each new day to avoid connecting across sessions. Dashed connector lines extend to the labels for easy identification.
This is particularly useful for intraday traders who watch these levels for potential support/resistance zones and breakout opportunities.
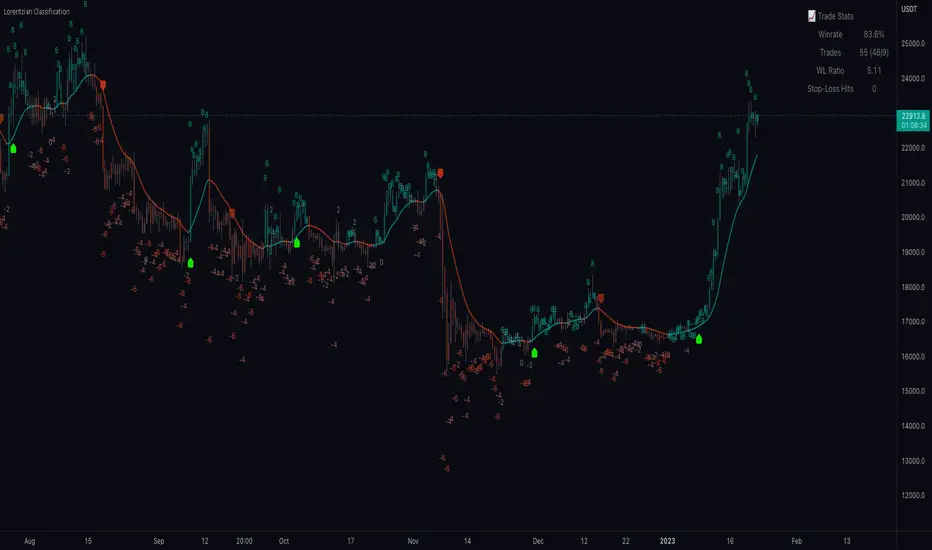
Machine Learning: Lorentzian Classification█ OVERVIEW
A Lorentzian Distance Classifier (LDC) is a Machine Learning classification algorithm capable of categorizing historical data from a multi-dimensional feature space. This indicator demonstrates how Lorentzian Classification can also be used to predict the direction of future price movements when used as the distance metric for a novel implementation of an Approximate Nearest Neighbors (ANN) algorithm.
█ BACKGROUND
In physics, Lorentzian space is perhaps best known for its role in describing the curvature of space-time in Einstein's theory of General Relativity (2). Interestingly, however, this abstract concept from theoretical physics also has tangible real-world applications in trading.
Recently, it was hypothesized that Lorentzian space was also well-suited for analyzing time-series data (4), (5). This hypothesis has been supported by several empirical studies that demonstrate that Lorentzian distance is more robust to outliers and noise than the more commonly used Euclidean distance (1), (3), (6). Furthermore, Lorentzian distance was also shown to outperform dozens of other highly regarded distance metrics, including Manhattan distance, Bhattacharyya similarity, and Cosine similarity (1), (3). Outside of Dynamic Time Warping based approaches, which are unfortunately too computationally intensive for PineScript at this time, the Lorentzian Distance metric consistently scores the highest mean accuracy over a wide variety of time series data sets (1).
Euclidean distance is commonly used as the default distance metric for NN-based search algorithms, but it may not always be the best choice when dealing with financial market data. This is because financial market data can be significantly impacted by proximity to major world events such as FOMC Meetings and Black Swan events. This event-based distortion of market data can be framed as similar to the gravitational warping caused by a massive object on the space-time continuum. For financial markets, the analogous continuum that experiences warping can be referred to as "price-time".
Below is a side-by-side comparison of how neighborhoods of similar historical points appear in three-dimensional Euclidean Space and Lorentzian Space:
This figure demonstrates how Lorentzian space can better accommodate the warping of price-time since the Lorentzian distance function compresses the Euclidean neighborhood in such a way that the new neighborhood distribution in Lorentzian space tends to cluster around each of the major feature axes in addition to the origin itself. This means that, even though some nearest neighbors will be the same regardless of the distance metric used, Lorentzian space will also allow for the consideration of historical points that would otherwise never be considered with a Euclidean distance metric.
Intuitively, the advantage inherent in the Lorentzian distance metric makes sense. For example, it is logical that the price action that occurs in the hours after Chairman Powell finishes delivering a speech would resemble at least some of the previous times when he finished delivering a speech. This may be true regardless of other factors, such as whether or not the market was overbought or oversold at the time or if the macro conditions were more bullish or bearish overall. These historical reference points are extremely valuable for predictive models, yet the Euclidean distance metric would miss these neighbors entirely, often in favor of irrelevant data points from the day before the event. By using Lorentzian distance as a metric, the ML model is instead able to consider the warping of price-time caused by the event and, ultimately, transcend the temporal bias imposed on it by the time series.
For more information on the implementation details of the Approximate Nearest Neighbors (ANN) algorithm used in this indicator, please refer to the detailed comments in the source code.
█ HOW TO USE
Below is an explanatory breakdown of the different parts of this indicator as it appears in the interface:
Below is an explanation of the different settings for this indicator:
General Settings:
Source - This has a default value of "hlc3" and is used to control the input data source.
Neighbors Count - This has a default value of 8, a minimum value of 1, a maximum value of 100, and a step of 1. It is used to control the number of neighbors to consider.
Max Bars Back - This has a default value of 2000.
Feature Count - This has a default value of 5, a minimum value of 2, and a maximum value of 5. It controls the number of features to use for ML predictions.
Color Compression - This has a default value of 1, a minimum value of 1, and a maximum value of 10. It is used to control the compression factor for adjusting the intensity of the color scale.
Show Exits - This has a default value of false. It controls whether to show the exit threshold on the chart.
Use Dynamic Exits - This has a default value of false. It is used to control whether to attempt to let profits ride by dynamically adjusting the exit threshold based on kernel regression.
Feature Engineering Settings:
Note: The Feature Engineering section is for fine-tuning the features used for ML predictions. The default values are optimized for the 4H to 12H timeframes for most charts, but they should also work reasonably well for other timeframes. By default, the model can support features that accept two parameters (Parameter A and Parameter B, respectively). Even though there are only 4 features provided by default, the same feature with different settings counts as two separate features. If the feature only accepts one parameter, then the second parameter will default to EMA-based smoothing with a default value of 1. These features represent the most effective combination I have encountered in my testing, but additional features may be added as additional options in the future.
Feature 1 - This has a default value of "RSI" and options are: "RSI", "WT", "CCI", "ADX".
Feature 2 - This has a default value of "WT" and options are: "RSI", "WT", "CCI", "ADX".
Feature 3 - This has a default value of "CCI" and options are: "RSI", "WT", "CCI", "ADX".
Feature 4 - This has a default value of "ADX" and options are: "RSI", "WT", "CCI", "ADX".
Feature 5 - This has a default value of "RSI" and options are: "RSI", "WT", "CCI", "ADX".
Filters Settings:
Use Volatility Filter - This has a default value of true. It is used to control whether to use the volatility filter.
Use Regime Filter - This has a default value of true. It is used to control whether to use the trend detection filter.
Use ADX Filter - This has a default value of false. It is used to control whether to use the ADX filter.
Regime Threshold - This has a default value of -0.1, a minimum value of -10, a maximum value of 10, and a step of 0.1. It is used to control the Regime Detection filter for detecting Trending/Ranging markets.
ADX Threshold - This has a default value of 20, a minimum value of 0, a maximum value of 100, and a step of 1. It is used to control the threshold for detecting Trending/Ranging markets.
Kernel Regression Settings:
Trade with Kernel - This has a default value of true. It is used to control whether to trade with the kernel.
Show Kernel Estimate - This has a default value of true. It is used to control whether to show the kernel estimate.
Lookback Window - This has a default value of 8 and a minimum value of 3. It is used to control the number of bars used for the estimation. Recommended range: 3-50
Relative Weighting - This has a default value of 8 and a step size of 0.25. It is used to control the relative weighting of time frames. Recommended range: 0.25-25
Start Regression at Bar - This has a default value of 25. It is used to control the bar index on which to start regression. Recommended range: 0-25
Display Settings:
Show Bar Colors - This has a default value of true. It is used to control whether to show the bar colors.
Show Bar Prediction Values - This has a default value of true. It controls whether to show the ML model's evaluation of each bar as an integer.
Use ATR Offset - This has a default value of false. It controls whether to use the ATR offset instead of the bar prediction offset.
Bar Prediction Offset - This has a default value of 0 and a minimum value of 0. It is used to control the offset of the bar predictions as a percentage from the bar high or close.
Backtesting Settings:
Show Backtest Results - This has a default value of true. It is used to control whether to display the win rate of the given configuration.
█ WORKS CITED
(1) R. Giusti and G. E. A. P. A. Batista, "An Empirical Comparison of Dissimilarity Measures for Time Series Classification," 2013 Brazilian Conference on Intelligent Systems, Oct. 2013, DOI: 10.1109/bracis.2013.22.
(2) Y. Kerimbekov, H. Ş. Bilge, and H. H. Uğurlu, "The use of Lorentzian distance metric in classification problems," Pattern Recognition Letters, vol. 84, 170–176, Dec. 2016, DOI: 10.1016/j.patrec.2016.09.006.
(3) A. Bagnall, A. Bostrom, J. Large, and J. Lines, "The Great Time Series Classification Bake Off: An Experimental Evaluation of Recently Proposed Algorithms." ResearchGate, Feb. 04, 2016.
(4) H. Ş. Bilge, Yerzhan Kerimbekov, and Hasan Hüseyin Uğurlu, "A new classification method by using Lorentzian distance metric," ResearchGate, Sep. 02, 2015.
(5) Y. Kerimbekov and H. Şakir Bilge, "Lorentzian Distance Classifier for Multiple Features," Proceedings of the 6th International Conference on Pattern Recognition Applications and Methods, 2017, DOI: 10.5220/0006197004930501.
(6) V. Surya Prasath et al., "Effects of Distance Measure Choice on KNN Classifier Performance - A Review." .
█ ACKNOWLEDGEMENTS
@veryfid - For many invaluable insights, discussions, and advice that helped to shape this project.
@capissimo - For open sourcing his interesting ideas regarding various KNN implementations in PineScript, several of which helped inspire my original undertaking of this project.
@RikkiTavi - For many invaluable physics-related conversations and for his helping me develop a mechanism for visualizing various distance algorithms in 3D using JavaScript
@jlaurel - For invaluable literature recommendations that helped me to understand the underlying subject matter of this project.
@annutara - For help in beta-testing this indicator and for sharing many helpful ideas and insights early on in its development.
@jasontaylor7 - For helping to beta-test this indicator and for many helpful conversations that helped to shape my backtesting workflow
@meddymarkusvanhala - For helping to beta-test this indicator
@dlbnext - For incredibly detailed backtesting testing of this indicator and for sharing numerous ideas on how the user experience could be improved.
RSI_Heikinashi📜 Title:
Heikin-Ashi RSI Candle Plot with Multi-Timeframe Analysis and EMA Overlay
📖 Full Description:
This is an original custom indicator that transforms the traditional Relative Strength Index (RSI) into a Heikin-Ashi (HA) candle representation, allowing traders to visualize RSI trends with greater clarity, less noise, and multi-timeframe perspective.
🛠️ Core Concept and Original Method:
Rather than plotting a single RSI line, this script recalculates RSI into a Heikin-Ashi candle format, using a double EMA smoothing method on the RSI data itself.
Here's how the transformation works:
RSI Calculation:
RSI is computed traditionally using Wilder's Moving Average (RMA) for smoothing gains and losses.
The RSI period and price source are fully customizable (default length = 28, source = close).
Heikin-Ashi Style Smoothing (applied to RSI):
The HA Close is calculated as the EMA of the average between the current RSI and previous HA Close.
The HA Open is calculated as the EMA of the average between the previous HA Open and the current HA Close.
The HA High and HA Low are dynamically calculated based on the maximum/minimum values of the current RSI, HA Open, and HA Close.
Smoothing is done via 5-period EMA, which adds a unique layer of trend smoothing without traditional price-based HA calculation.
Multi-Timeframe Comparison:
In addition to plotting the chart timeframe HA RSI, the indicator retrieves the 1-hour timeframe HA RSI using request.security.
This allows traders to align trades with higher timeframe RSI trends, a powerful technique for multi-timeframe confirmation.
50 EMA Overlay:
A 50-period Exponential Moving Average (EMA) is plotted over both the chart timeframe HA RSI and the 1-hour HA RSI.
EMA acts as a trend filter or dynamic support/resistance for RSI behavior.
RSI Bands and Visual Aids:
Standard RSI bands at 70 (Overbought), 50 (Midline), and 30 (Oversold) are plotted.
A shaded background between the 30–70 levels helps highlight RSI range-bound movements versus breakout momentum.
🔥 Why this script is original and useful:
Unique Application:
This is not a simple RSI plot or standard Heikin-Ashi candle — it is a specialized smoothing method applied directly to RSI values for a clearer, noise-reduced momentum reading.
Multi-Timeframe Advantage:
Unlike typical RSI indicators, it includes a 1-hour timeframe comparison alongside the chart timeframe, improving decision-making across intraday and swing strategies.
Advanced Smoothing Logic:
Double EMA smoothing of RSI and HA-style recalculations offer a much smoother signal than traditional RSI or basic RSI/EMA crossovers.
Visualized Trend Strength:
Using colored candles instead of just a line enhances readability and gives an intuitive sense of momentum direction, strength, and possible reversals.
Fully Customizable:
Traders can adjust the RSI period and source depending on asset volatility or timeframe preferences.
📋 How to Use:
Look for HA RSI candles color changes for early momentum shifts.
Use the 50 EMA crossovers on HA RSI to confirm larger trend changes.
Compare chart timeframe vs 1H timeframe HA RSI for stronger signal alignment.
Watch for overbought/oversold breaks beyond the 70/30 bands for trade entries or exits.
⚙️ Inputs:
RSI Length (Default: 28)
RSI Source (Default: Close)
📢 Important Note:
This script is originally conceptualized and custom-built.
It is not a mashup of existing open-source indicators and introduces a new smoothing technique for RSI visualization.
🙏 Credits:
Script developed by Sri_RSI.
Any Oscillator Underlay [TTF]We are proud to release a new indicator that has been a while in the making - the Any Oscillator Underlay (AOU) !
Note: There is a lot to discuss regarding this indicator, including its intent and some of how it operates, so please be sure to read this entire description before using this indicator to help ensure you understand both the intent and some limitations with this tool.
Our intent for building this indicator was to accomplish the following:
Combine all of the oscillators that we like to use into a single indicator
Take up a bit less screen space for the underlay indicators for strategies that utilize multiple oscillators
Provide a tool for newer traders to be able to leverage multiple oscillators in a single indicator
Features:
Includes 8 separate, fully-functional indicators combined into one
Ability to easily enable/disable and configure each included indicator independently
Clearly named plots to support user customization of color and styling, as well as manual creation of alerts
Ability to customize sub-indicator title position and color
Ability to customize sub-indicator divider lines style and color
Indicators that are included in this initial release:
TSI
2x RSIs (dubbed the Twin RSI )
Stochastic RSI
Stochastic
Ultimate Oscillator
Awesome Oscillator
MACD
Outback RSI (Color-coding only)
Quick note on OB/OS:
Before we get into covering each included indicator, we first need to cover a core concept for how we're defining OB and OS levels. To help illustrate this, we will use the TSI as an example.
The TSI by default has a mid-point of 0 and a range of -100 to 100. As a result, a common practice is to place lines on the -30 and +30 levels to represent OS and OB zones, respectively. Most people tend to view these levels as distance from the edges/outer bounds or as absolute levels, but we feel a more way to frame the OB/OS concept is to instead define it as distance ("offset") from the mid-line. In keeping with the -30 and +30 levels in our example, the offset in this case would be "30".
Taking this a step further, let's say we decided we wanted an offset of 25. Since the mid-point is 0, we'd then calculate the OB level as 0 + 25 (+25), and the OS level as 0 - 25 (-25).
Now that we've covered the concept of how we approach defining OB and OS levels (based on offset/distance from the mid-line), and since we did apply some transformations, rescaling, and/or repositioning to all of the indicators noted above, we are going to discuss each component indicator to detail both how it was modified from the original to fit the stacked-indicator model, as well as the various major components that the indicator contains.
TSI:
This indicator contains the following major elements:
TSI and TSI Signal Line
Color-coded fill for the TSI/TSI Signal lines
Moving Average for the TSI
TSI Histogram
Mid-line and OB/OS lines
Default TSI fill color coding:
Green : TSI is above the signal line
Red : TSI is below the signal line
Note: The TSI traditionally has a range of -100 to +100 with a mid-point of 0 (range of 200). To fit into our stacking model, we first shrunk the range to 100 (-50 to +50 - cut it in half), then repositioned it to have a mid-point of 50. Since this is the "bottom" of our indicator-stack, no additional repositioning is necessary.
Twin RSI:
This indicator contains the following major elements:
Fast RSI (useful if you want to leverage 2x RSIs as it makes it easier to see the overlaps and crosses - can be disabled if desired)
Slow RSI (primary RSI)
Color-coded fill for the Fast/Slow RSI lines (if Fast RSI is enabled and configured)
Moving Average for the Slow RSI
Mid-line and OB/OS lines
Default Twin RSI fill color coding:
Dark Red : Fast RSI below Slow RSI and Slow RSI below Slow RSI MA
Light Red : Fast RSI below Slow RSI and Slow RSI above Slow RSI MA
Dark Green : Fast RSI above Slow RSI and Slow RSI below Slow RSI MA
Light Green : Fast RSI above Slow RSI and Slow RSI above Slow RSI MA
Note: The RSI naturally has a range of 0 to 100 with a mid-point of 50, so no rescaling or transformation is done on this indicator. The only manipulation done is to properly position it in the indicator-stack based on which other indicators are also enabled.
Stochastic and Stochastic RSI:
These indicators contain the following major elements:
Configurable lengths for the RSI (for the Stochastic RSI only), K, and D values
Configurable base price source
Mid-line and OB/OS lines
Note: The Stochastic and Stochastic RSI both have a normal range of 0 to 100 with a mid-point of 50, so no rescaling or transformations are done on either of these indicators. The only manipulation done is to properly position it in the indicator-stack based on which other indicators are also enabled.
Ultimate Oscillator (UO):
This indicator contains the following major elements:
Configurable lengths for the Fast, Middle, and Slow BP/TR components
Mid-line and OB/OS lines
Moving Average for the UO
Color-coded fill for the UO/UO MA lines (if UO MA is enabled and configured)
Default UO fill color coding:
Green : UO is above the moving average line
Red : UO is below the moving average line
Note: The UO naturally has a range of 0 to 100 with a mid-point of 50, so no rescaling or transformation is done on this indicator. The only manipulation done is to properly position it in the indicator-stack based on which other indicators are also enabled.
Awesome Oscillator (AO):
This indicator contains the following major elements:
Configurable lengths for the Fast and Slow moving averages used in the AO calculation
Configurable price source for the moving averages used in the AO calculation
Mid-line
Option to display the AO as a line or pseudo-histogram
Moving Average for the AO
Color-coded fill for the AO/AO MA lines (if AO MA is enabled and configured)
Default AO fill color coding (Note: Fill was disabled in the image above to improve clarity):
Green : AO is above the moving average line
Red : AO is below the moving average line
Note: The AO is technically has an infinite (unbound) range - -∞ to ∞ - and the effective range is bound to the underlying security price (e.g. BTC will have a wider range than SP500, and SP500 will have a wider range than EUR/USD). We employed some special techniques to rescale this indicator into our desired range of 100 (-50 to 50), and then repositioned it to have a midpoint of 50 (range of 0 to 100) to meet the constraints of our stacking model. We then do one final repositioning to place it in the correct position the indicator-stack based on which other indicators are also enabled. For more details on how we accomplished this, read our section "Binding Infinity" below.
MACD:
This indicator contains the following major elements:
Configurable lengths for the Fast and Slow moving averages used in the MACD calculation
Configurable price source for the moving averages used in the MACD calculation
Configurable length and calculation method for the MACD Signal Line calculation
Mid-line
Note: Like the AO, the MACD also technically has an infinite (unbound) range. We employed the same principles here as we did with the AO to rescale and reposition this indicator as well. For more details on how we accomplished this, read our section "Binding Infinity" below.
Outback RSI (ORSI):
This is a stripped-down version of the Outback RSI indicator (linked above) that only includes the color-coding background (suffice it to say that it was not technically feasible to attempt to rescale the other components in a way that could consistently be clearly seen on-chart). As this component is a bit of a niche/special-purpose sub-indicator, it is disabled by default, and we suggest it remain disabled unless you have some pre-defined strategy that leverages the color-coding element of the Outback RSI that you wish to use.
Binding Infinity - How We Incorporated the AO and MACD (Warning - Math Talk Ahead!)
Note: This applies only to the AO and MACD at time of original publication. If any other indicators are added in the future that also fall into the category of "binding an infinite-range oscillator", we will make that clear in the release notes when that new addition is published.
To help set the stage for this discussion, it's important to note that the broader challenge of "equalizing inputs" is nothing new. In fact, it's a key element in many of the most popular fields of data science, such as AI and Machine Learning. They need to take a diverse set of inputs with a wide variety of ranges and seemingly-random inputs (referred to as "features"), and build a mathematical or computational model in order to work. But, when the raw inputs can vary significantly from one another, there is an inherent need to do some pre-processing to those inputs so that one doesn't overwhelm another simply due to the difference in raw values between them. This is where feature scaling comes into play.
With this in mind, we implemented 2 of the most common methods of Feature Scaling - Min-Max Normalization (which we call "Normalization" in our settings), and Z-Score Normalization (which we call "Standardization" in our settings). Let's take a look at each of those methods as they have been implemented in this script.
Min-Max Normalization (Normalization)
This is one of the most common - and most basic - methods of feature scaling. The basic formula is: y = (x - min)/(max - min) - where x is the current data sample, min is the lowest value in the dataset, and max is the highest value in the dataset. In this transformation, the max would evaluate to 1, and the min would evaluate to 0, and any value in between the min and the max would evaluate somewhere between 0 and 1.
The key benefits of this method are:
It can be used to transform datasets of any range into a new dataset with a consistent and known range (0 to 1).
It has no dependency on the "shape" of the raw input dataset (i.e. does not assume the input dataset can be approximated to a normal distribution).
But there are a couple of "gotchas" with this technique...
First, it assumes the input dataset is complete, or an accurate representation of the population via random sampling. While in most situations this is a valid assumption, in trading indicators we don't really have that luxury as we're often limited in what sample data we can access (i.e. number of historical bars available).
Second, this method is highly sensitive to outliers. Since the crux of this transformation is based on the max-min to define the initial range, a single significant outlier can result in skewing the post-transformation dataset (i.e. major price movement as a reaction to a significant news event).
You can potentially mitigate those 2 "gotchas" by using a mechanism or technique to find and discard outliers (e.g. calculate the mean and standard deviation of the input dataset and discard any raw values more than 5 standard deviations from the mean), but if your most recent datapoint is an "outlier" as defined by that algorithm, processing it using the "scrubbed" dataset would result in that new datapoint being outside the intended range of 0 to 1 (e.g. if the new datapoint is greater than the "scrubbed" max, it's post-transformation value would be greater than 1). Even though this is a bit of an edge-case scenario, it is still sure to happen in live markets processing live data, so it's not an ideal solution in our opinion (which is why we chose not to attempt to discard outliers in this manner).
Z-Score Normalization (Standardization)
This method of rescaling is a bit more complex than the Min-Max Normalization method noted above, but it is also a widely used process. The basic formula is: y = (x – μ) / σ - where x is the current data sample, μ is the mean (average) of the input dataset, and σ is the standard deviation of the input dataset. While this transformation still results in a technically-infinite possible range, the output of this transformation has a 2 very significant properties - the mean (average) of the output dataset has a mean (μ) of 0 and a standard deviation (σ) of 1.
The key benefits of this method are:
As it's based on normalizing the mean and standard deviation of the input dataset instead of a linear range conversion, it is far less susceptible to outliers significantly affecting the result (and in fact has the effect of "squishing" outliers).
It can be used to accurately transform disparate sets of data into a similar range regardless of the original dataset's raw/actual range.
But there are a couple of "gotchas" with this technique as well...
First, it still technically does not do any form of range-binding, so it is still technically unbounded (range -∞ to ∞ with a mid-point of 0).
Second, it implicitly assumes that the raw input dataset to be transformed is normally distributed, which won't always be the case in financial markets.
The first "gotcha" is a bit of an annoyance, but isn't a huge issue as we can apply principles of normal distribution to conceptually limit the range by defining a fixed number of standard deviations from the mean. While this doesn't totally solve the "infinite range" problem (a strong enough sudden move can still break out of our "conceptual range" boundaries), the amount of movement needed to achieve that kind of impact will generally be pretty rare.
The bigger challenge is how to deal with the assumption of the input dataset being normally distributed. While most financial markets (and indicators) do tend towards a normal distribution, they are almost never going to match that distribution exactly. So let's dig a bit deeper into distributions are defined and how things like trending markets can affect them.
Skew (skewness): This is a measure of asymmetry of the bell curve, or put another way, how and in what way the bell curve is disfigured when comparing the 2 halves. The easiest way to visualize this is to draw an imaginary vertical line through the apex of the bell curve, then fold the curve in half along that line. If both halves are exactly the same, the skew is 0 (no skew/perfectly symmetrical) - which is what a normal distribution has (skew = 0). Most financial markets tend to have short, medium, and long-term trends, and these trends will cause the distribution curve to skew in one direction or another. Bullish markets tend to skew to the right (positive), and bearish markets to the left (negative).
Kurtosis: This is a measure of the "tail size" of the bell curve. Another way to state this could be how "flat" or "steep" the bell-shape is. If the bell is steep with a strong drop from the apex (like a steep cliff), it has low kurtosis. If the bell has a shallow, more sweeping drop from the apex (like a tall hill), is has high kurtosis. Translating this to financial markets, kurtosis is generally a metric of volatility as the bell shape is largely defined by the strength and frequency of outliers. This is effectively a measure of volatility - volatile markets tend to have a high level of kurtosis (>3), and stable/consolidating markets tend to have a low level of kurtosis (<3). A normal distribution (our reference), has a kurtosis value of 3.
So to try and bring all that back together, here's a quick recap of the Standardization rescaling method:
The Standardization method has an assumption of a normal distribution of input data by using the mean (average) and standard deviation to handle the transformation
Most financial markets do NOT have a normal distribution (as discussed above), and will have varying degrees of skew and kurtosis
Q: Why are we still favoring the Standardization method over the Normalization method, and how are we accounting for the innate skew and/or kurtosis inherent in most financial markets?
A: Well, since we're only trying to rescale oscillators that by-definition have a midpoint of 0, kurtosis isn't a major concern beyond the affect it has on the post-transformation scaling (specifically, the number of standard deviations from the mean we need to include in our "artificially-bound" range definition).
Q: So that answers the question about kurtosis, but what about skew?
A: So - for skew, the answer is in the formula - specifically the mean (average) element. The standard mean calculation assumes a complete dataset and therefore uses a standard (i.e. simple) average, but we're limited by the data history available to us. So we adapted the transformation formula to leverage a moving average that included a weighting element to it so that it favored recent datapoints more heavily than older ones. By making the average component more adaptive, we gained the effect of reducing the skew element by having the average itself be more responsive to recent movements, which significantly reduces the effect historical outliers have on the dataset as a whole. While this is certainly not a perfect solution, we've found that it serves the purpose of rescaling the MACD and AO to a far more well-defined range while still preserving the oscillator behavior and mid-line exceptionally well.
The most difficult parts to compensate for are periods where markets have low volatility for an extended period of time - to the point where the oscillators are hovering around the 0/midline (in the case of the AO), or when the oscillator and signal lines converge and remain close to each other (in the case of the MACD). It's during these periods where even our best attempt at ensuring accurate mirrored-behavior when compared to the original can still occasionally lead or lag by a candle.
Note: If this is a make-or-break situation for you or your strategy, then we recommend you do not use any of the included indicators that leverage this kind of bounding technique (the AO and MACD at time of publication) and instead use the Trandingview built-in versions!
We know this is a lot to read and digest, so please take your time and feel free to ask questions - we will do our best to answer! And as always, constructive feedback is always welcome!

Stock Relative Strength Power IndexAs always, this is not financial advice and use at your own risk. Trading is risky and can cost you significant sums of money if you are not careful. Make sure you always have a proper entry and exit plan that includes defining your risk before you enter a trade.
This idea recently came out of some discussions I stumbled across in a trading group I am a part of regarding Relative Strength and Relative Weakness (shortened to RS and RW from here on out). The whole mechanism behind this trading system is to filter out underperforming securities relative to the current market direction to be in only the strongest or weakest stocks when the market is currently experiencing a bullish or bearish cycle. The idea behind this is there is no point in parking your money into a stock that is treading water or even going down if the market is making strong moves upwards. At that point, you are at worst losing money, and at best trading equal to the index/ETF, in which case the argument is why are you not just trading the index/ETF instead? RS or RW will filter out these sector laggards and allow you to position yourself into strong (or the strongest) stocks at any given time to help improve portfolio performance. Further, not only does it protect your position should the market shift against you briefly, it also often sees exceptional performance in the same cycle. For example, if $SPY makes a 5% move over the course of a month, a stock with RS/RW may make a 10% move, or more, allowing you to see increased profit potential.
RS/RW is based on the idea of performance, that is the raw percent change of a security over a given time period relative to a benchmark. This benchmark is often the S&P500 (ES/SPX/SPY and their derivatives). I have to stress that this is not beta, which measures the volatility of a stock over a given period (i.e. if $SPY moves $1, $NVDA will often move $1.74). This is a measurement of the market (i.e. $SPY) has moved 1% over the course of a day, $NVDA has moved 8% over the course of the day. This is very often used as a signal of institutional interest as apart from some very unique moments, retail traders cannot and will not provide enough market pressure to move a market outside of a stock's normal trading range, nor will they outperform the sector or market as a whole consistently over time without some big money to make them move. The problem with running strict performance analysis (i.e. % change from period T ago to period T + n at present) is that while it gives us a baseline of how much the stock has moved, it doesn't overall mean much. For instance, if a $100 stock has moved 5% today, but has been experiencing a period of increased volatility and it's Average True Range (ATR) (the amount a stock will move over X number of periods, on average) is $7, performance seems impressive but is actually generally fairly weak to what the stock has been doing recently. Conversely, if we take a second stock, this time worth $20, and it too has moved 5% in one day but has an ATR of only $0.25, that stock has made an exceptional move and we want to be part of that.
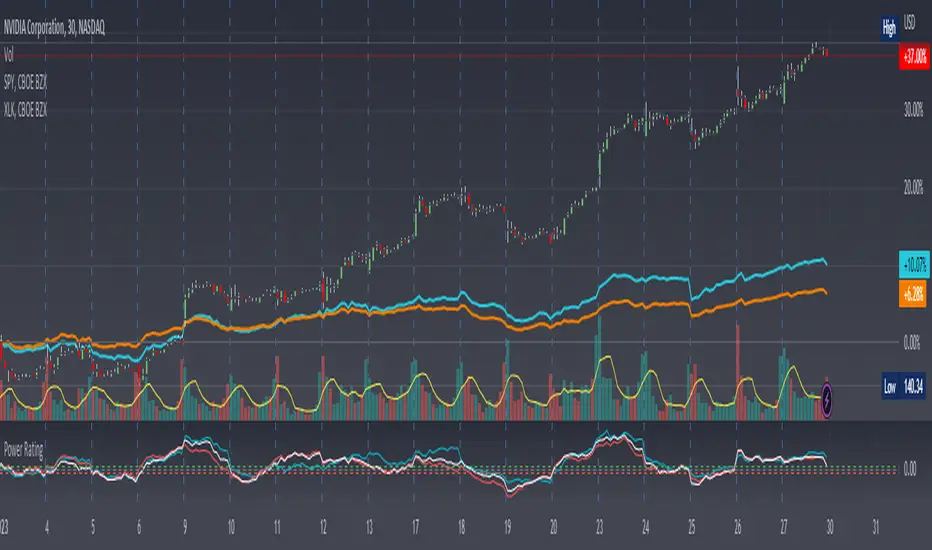
Here, I have created an indicator called the Stock Relative Strength Power Index. This takes the stock's rate of change (ROC) (the % move it has made over X number of periods), the stock's normalized ATR (the ATR represented as a percentage instead of a raw value), and compares these to one another to get the "Power Rating": a representation of the true strength of a stock over X number of periods. The indicator does two things. First, the raw ROC is divided by the stock's normalized ATR to assess whether the stock is moving outside of its normal range of variation or not. Second, since we are interested in trading only stocks with exceptional RS/RW to the market, I have also applied this same calculation to the S&P500 ($SPY) and the various SPDR sector indexes. These comparisons allow for a rapid and accurate assessment of the true strength of a stock at any given time on any given time frame. To cycle back above to our examples, the $100 stock has a Power Rating of only 0.71 (i.e. it is trading less than its current average), while our $20 stock has a Power Rating of 5. If we then compare these to both the market as a whole and the sector that the stock is a part of, we get a much clearer indication of the true buying or selling pressure imposed on the stock at any given time.
Use:
The indicator has 3 lines. The blue line is the security of interest, the red line is the market baseline (i.e. the sector ETF $SPY), and the white line is the sector index. I have given an example above on the semiconductor/tech stock $NVDA on a 30min timeframe. You can see that since the start of 2023, $NVDA has generally been strong to the market and its own sector since the blue line is greater than both the red and white lines over many days. This would have provided some nice day trading opportunities, or even some nice short term swing trades. The values themselves are generally meaningless outside of either the 1 or -1 value lines. All that matters is that the current ticker is surpassing both the market and the sector while being > 1.0 for a long trade or less than -1.0 for a short trade. However, I must stress this indicator gives no trade signals on its own, it is purely a confirmation indicator. An example of a trade would be if you had a trade signal given by either an indicator or by price action suggesting to buy some $NVDA for a trade to the upside, the Power Rating indicator would confirm this by showing if $NVDA was actually showing true strength by being both greater than 1 (the cutoff for it surpassing its ATR) and being above both the red and white lines. Further, you can see $NVDA has been stronger than the market when using the comparison function as well, but the has fluxed in and out of strength intraday when using the actual indicator vs. the static performance ratio chart (plotted as line graphs on the chart).
I have made it possible to change the colour of the plots and the line levels. The adjustment of the line levels gives the trader the flexibility to change their target breakout level (i.e. only trading stocks that have a Power Rating > 2, for example, meaning they are trading at least 2X their normal trading range). The third security comparison is flexible and can be used to compare to the sector ETF (initial intention) or it can be used to compare to other tickers within the same sector, for example. The trader should select the appropriate ETF for the given security of interest to avoid false confirmation if they want to use an ETF as their third input. The proper sector should be readily available on most online websites and accessible in a matter of seconds meaning that the delay is minimal, at worst. If a trader wishes to add additional functionality, such as a crypto trader using BTCUSD as the benchmark instead of $SPY, I encourage them to copy and paste this script and modify as needed since I have made this open source.
This indicator works on all timeframes. The lookback period can be changed, so a day trader who may use a 5min chart (and use a period of 12 to get the hourly Power Rating) will find this equally useful as someone who may be a core trader who wants to look at the performance over the course of years and may use a 60 period on a monthly chart.
Happy trading and I hope this helps!
Quantum Rotational Field MappingQuantum Rotational Field Mapping (QRFM):
Phase Coherence Detection Through Complex-Plane Oscillator Analysis
Quantum Rotational Field Mapping applies complex-plane mathematics and phase-space analysis to oscillator ensembles, identifying high-probability trend ignition points by measuring when multiple independent oscillators achieve phase coherence. Unlike traditional multi-oscillator approaches that simply stack indicators or use boolean AND/OR logic, this system converts each oscillator into a rotating phasor (vector) in the complex plane and calculates the Coherence Index (CI) —a mathematical measure of how tightly aligned the ensemble has become—then generates signals only when alignment, phase direction, and pairwise entanglement all converge.
The indicator combines three mathematical frameworks: phasor representation using analytic signal theory to extract phase and amplitude from each oscillator, coherence measurement using vector summation in the complex plane to quantify group alignment, and entanglement analysis that calculates pairwise phase agreement across all oscillator combinations. This creates a multi-dimensional confirmation system that distinguishes between random oscillator noise and genuine regime transitions.
What Makes This Original
Complex-Plane Phasor Framework
This indicator implements classical signal processing mathematics adapted for market oscillators. Each oscillator—whether RSI, MACD, Stochastic, CCI, Williams %R, MFI, ROC, or TSI—is first normalized to a common scale, then converted into a complex-plane representation using an in-phase (I) and quadrature (Q) component. The in-phase component is the oscillator value itself, while the quadrature component is calculated as the first difference (derivative proxy), creating a velocity-aware representation.
From these components, the system extracts:
Phase (φ) : Calculated as φ = atan2(Q, I), representing the oscillator's position in its cycle (mapped to -180° to +180°)
Amplitude (A) : Calculated as A = √(I² + Q²), representing the oscillator's strength or conviction
This mathematical approach is fundamentally different from simply reading oscillator values. A phasor captures both where an oscillator is in its cycle (phase angle) and how strongly it's expressing that position (amplitude). Two oscillators can have the same value but be in opposite phases of their cycles—traditional analysis would see them as identical, while QRFM sees them as 180° out of phase (contradictory).
Coherence Index Calculation
The core innovation is the Coherence Index (CI) , borrowed from physics and signal processing. When you have N oscillators, each with phase φₙ, you can represent each as a unit vector in the complex plane: e^(iφₙ) = cos(φₙ) + i·sin(φₙ).
The CI measures what happens when you sum all these vectors:
Resultant Vector : R = Σ e^(iφₙ) = Σ cos(φₙ) + i·Σ sin(φₙ)
Coherence Index : CI = |R| / N
Where |R| is the magnitude of the resultant vector and N is the number of active oscillators.
The CI ranges from 0 to 1:
CI = 1.0 : Perfect coherence—all oscillators have identical phase angles, vectors point in the same direction, creating maximum constructive interference
CI = 0.0 : Complete decoherence—oscillators are randomly distributed around the circle, vectors cancel out through destructive interference
0 < CI < 1 : Partial alignment—some clustering with some scatter
This is not a simple average or correlation. The CI captures phase synchronization across the entire ensemble simultaneously. When oscillators phase-lock (align their cycles), the CI spikes regardless of their individual values. This makes it sensitive to regime transitions that traditional indicators miss.
Dominant Phase and Direction Detection
Beyond measuring alignment strength, the system calculates the dominant phase of the ensemble—the direction the resultant vector points:
Dominant Phase : φ_dom = atan2(Σ sin(φₙ), Σ cos(φₙ))
This gives the "average direction" of all oscillator phases, mapped to -180° to +180°:
+90° to -90° (right half-plane): Bullish phase dominance
+90° to +180° or -90° to -180° (left half-plane): Bearish phase dominance
The combination of CI magnitude (coherence strength) and dominant phase angle (directional bias) creates a two-dimensional signal space. High CI alone is insufficient—you need high CI plus dominant phase pointing in a tradeable direction. This dual requirement is what separates QRFM from simple oscillator averaging.
Entanglement Matrix and Pairwise Coherence
While the CI measures global alignment, the entanglement matrix measures local pairwise relationships. For every pair of oscillators (i, j), the system calculates:
E(i,j) = |cos(φᵢ - φⱼ)|
This represents the phase agreement between oscillators i and j:
E = 1.0 : Oscillators are in-phase (0° or 360° apart)
E = 0.0 : Oscillators are in quadrature (90° apart, orthogonal)
E between 0 and 1 : Varying degrees of alignment
The system counts how many oscillator pairs exceed a user-defined entanglement threshold (e.g., 0.7). This entangled pairs count serves as a confirmation filter: signals require not just high global CI, but also a minimum number of strong pairwise agreements. This prevents false ignitions where CI is high but driven by only two oscillators while the rest remain scattered.
The entanglement matrix creates an N×N symmetric matrix that can be visualized as a web—when many cells are bright (high E values), the ensemble is highly interconnected. When cells are dark, oscillators are moving independently.
Phase-Lock Tolerance Mechanism
A complementary confirmation layer is the phase-lock detector . This calculates the maximum phase spread across all oscillators:
For all pairs (i,j), compute angular distance: Δφ = |φᵢ - φⱼ|, wrapping at 180°
Max Spread = maximum Δφ across all pairs
If max spread < user threshold (e.g., 35°), the ensemble is considered phase-locked —all oscillators are within a narrow angular band.
This differs from entanglement: entanglement measures pairwise cosine similarity (magnitude of alignment), while phase-lock measures maximum angular deviation (tightness of clustering). Both must be satisfied for the highest-conviction signals.
Multi-Layer Visual Architecture
QRFM includes six visual components that represent the same underlying mathematics from different perspectives:
Circular Orbit Plot : A polar coordinate grid showing each oscillator as a vector from origin to perimeter. Angle = phase, radius = amplitude. This is a real-time snapshot of the complex plane. When vectors converge (point in similar directions), coherence is high. When scattered randomly, coherence is low. Users can see phase alignment forming before CI numerically confirms it.
Phase-Time Heat Map : A 2D matrix with rows = oscillators and columns = time bins. Each cell is colored by the oscillator's phase at that time (using a gradient where color hue maps to angle). Horizontal color bands indicate sustained phase alignment over time. Vertical color bands show moments when all oscillators shared the same phase (ignition points). This provides historical pattern recognition.
Entanglement Web Matrix : An N×N grid showing E(i,j) for all pairs. Cells are colored by entanglement strength—bright yellow/gold for high E, dark gray for low E. This reveals which oscillators are driving coherence and which are lagging. For example, if RSI and MACD show high E but Stochastic shows low E with everything, Stochastic is the outlier.
Quantum Field Cloud : A background color overlay on the price chart. Color (green = bullish, red = bearish) is determined by dominant phase. Opacity is determined by CI—high CI creates dense, opaque cloud; low CI creates faint, nearly invisible cloud. This gives an atmospheric "feel" for regime strength without looking at numbers.
Phase Spiral : A smoothed plot of dominant phase over recent history, displayed as a curve that wraps around price. When the spiral is tight and rotating steadily, the ensemble is in coherent rotation (trending). When the spiral is loose or erratic, coherence is breaking down.
Dashboard : A table showing real-time metrics: CI (as percentage), dominant phase (in degrees with directional arrow), field strength (CI × average amplitude), entangled pairs count, phase-lock status (locked/unlocked), quantum state classification ("Ignition", "Coherent", "Collapse", "Chaos"), and collapse risk (recent CI change normalized to 0-100%).
Each component is independently toggleable, allowing users to customize their workspace. The orbit plot is the most essential—it provides intuitive, visual feedback on phase alignment that no numerical dashboard can match.
Core Components and How They Work Together
1. Oscillator Normalization Engine
The foundation is creating a common measurement scale. QRFM supports eight oscillators:
RSI : Normalized from to using overbought/oversold levels (70, 30) as anchors
MACD Histogram : Normalized by dividing by rolling standard deviation, then clamped to
Stochastic %K : Normalized from using (80, 20) anchors
CCI : Divided by 200 (typical extreme level), clamped to
Williams %R : Normalized from using (-20, -80) anchors
MFI : Normalized from using (80, 20) anchors
ROC : Divided by 10, clamped to
TSI : Divided by 50, clamped to
Each oscillator can be individually enabled/disabled. Only active oscillators contribute to phase calculations. The normalization removes scale differences—a reading of +0.8 means "strongly bullish" regardless of whether it came from RSI or TSI.
2. Analytic Signal Construction
For each active oscillator at each bar, the system constructs the analytic signal:
In-Phase (I) : The normalized oscillator value itself
Quadrature (Q) : The bar-to-bar change in the normalized value (first derivative approximation)
This creates a 2D representation: (I, Q). The phase is extracted as:
φ = atan2(Q, I) × (180 / π)
This maps the oscillator to a point on the unit circle. An oscillator at the same value but rising (positive Q) will have a different phase than one that is falling (negative Q). This velocity-awareness is critical—it distinguishes between "at resistance and stalling" versus "at resistance and breaking through."
The amplitude is extracted as:
A = √(I² + Q²)
This represents the distance from origin in the (I, Q) plane. High amplitude means the oscillator is far from neutral (strong conviction). Low amplitude means it's near zero (weak/transitional state).
3. Coherence Calculation Pipeline
For each bar (or every Nth bar if phase sample rate > 1 for performance):
Step 1 : Extract phase φₙ for each of the N active oscillators
Step 2 : Compute complex exponentials: Zₙ = e^(i·φₙ·π/180) = cos(φₙ·π/180) + i·sin(φₙ·π/180)
Step 3 : Sum the complex exponentials: R = Σ Zₙ = (Σ cos φₙ) + i·(Σ sin φₙ)
Step 4 : Calculate magnitude: |R| = √
Step 5 : Normalize by count: CI_raw = |R| / N
Step 6 : Smooth the CI: CI = SMA(CI_raw, smoothing_window)
The smoothing step (default 2 bars) removes single-bar noise spikes while preserving structural coherence changes. Users can adjust this to control reactivity versus stability.
The dominant phase is calculated as:
φ_dom = atan2(Σ sin φₙ, Σ cos φₙ) × (180 / π)
This is the angle of the resultant vector R in the complex plane.
4. Entanglement Matrix Construction
For all unique pairs of oscillators (i, j) where i < j:
Step 1 : Get phases φᵢ and φⱼ
Step 2 : Compute phase difference: Δφ = φᵢ - φⱼ (in radians)
Step 3 : Calculate entanglement: E(i,j) = |cos(Δφ)|
Step 4 : Store in symmetric matrix: matrix = matrix = E(i,j)
The matrix is then scanned: count how many E(i,j) values exceed the user-defined threshold (default 0.7). This count is the entangled pairs metric.
For visualization, the matrix is rendered as an N×N table where cell brightness maps to E(i,j) intensity.
5. Phase-Lock Detection
Step 1 : For all unique pairs (i, j), compute angular distance: Δφ = |φᵢ - φⱼ|
Step 2 : Wrap angles: if Δφ > 180°, set Δφ = 360° - Δφ
Step 3 : Find maximum: max_spread = max(Δφ) across all pairs
Step 4 : Compare to tolerance: phase_locked = (max_spread < tolerance)
If phase_locked is true, all oscillators are within the specified angular cone (e.g., 35°). This is a boolean confirmation filter.
6. Signal Generation Logic
Signals are generated through multi-layer confirmation:
Long Ignition Signal :
CI crosses above ignition threshold (e.g., 0.80)
AND dominant phase is in bullish range (-90° < φ_dom < +90°)
AND phase_locked = true
AND entangled_pairs >= minimum threshold (e.g., 4)
Short Ignition Signal :
CI crosses above ignition threshold
AND dominant phase is in bearish range (φ_dom < -90° OR φ_dom > +90°)
AND phase_locked = true
AND entangled_pairs >= minimum threshold
Collapse Signal :
CI at bar minus CI at current bar > collapse threshold (e.g., 0.55)
AND CI at bar was above 0.6 (must collapse from coherent state, not from already-low state)
These are strict conditions. A high CI alone does not generate a signal—dominant phase must align with direction, oscillators must be phase-locked, and sufficient pairwise entanglement must exist. This multi-factor gating dramatically reduces false signals compared to single-condition triggers.
Calculation Methodology
Phase 1: Oscillator Computation and Normalization
On each bar, the system calculates the raw values for all enabled oscillators using standard Pine Script functions:
RSI: ta.rsi(close, length)
MACD: ta.macd() returning histogram component
Stochastic: ta.stoch() smoothed with ta.sma()
CCI: ta.cci(close, length)
Williams %R: ta.wpr(length)
MFI: ta.mfi(hlc3, length)
ROC: ta.roc(close, length)
TSI: ta.tsi(close, short, long)
Each raw value is then passed through a normalization function:
normalize(value, overbought_level, oversold_level) = 2 × (value - oversold) / (overbought - oversold) - 1
This maps the oscillator's typical range to , where -1 represents extreme bearish, 0 represents neutral, and +1 represents extreme bullish.
For oscillators without fixed ranges (MACD, ROC, TSI), statistical normalization is used: divide by a rolling standard deviation or fixed divisor, then clamp to .
Phase 2: Phasor Extraction
For each normalized oscillator value val:
I = val (in-phase component)
Q = val - val (quadrature component, first difference)
Phase calculation:
phi_rad = atan2(Q, I)
phi_deg = phi_rad × (180 / π)
Amplitude calculation:
A = √(I² + Q²)
These values are stored in arrays: osc_phases and osc_amps for each oscillator n.
Phase 3: Complex Summation and Coherence
Initialize accumulators:
sum_cos = 0
sum_sin = 0
For each oscillator n = 0 to N-1:
phi_rad = osc_phases × (π / 180)
sum_cos += cos(phi_rad)
sum_sin += sin(phi_rad)
Resultant magnitude:
resultant_mag = √(sum_cos² + sum_sin²)
Coherence Index (raw):
CI_raw = resultant_mag / N
Smoothed CI:
CI = SMA(CI_raw, smoothing_window)
Dominant phase:
phi_dom_rad = atan2(sum_sin, sum_cos)
phi_dom_deg = phi_dom_rad × (180 / π)
Phase 4: Entanglement Matrix Population
For i = 0 to N-2:
For j = i+1 to N-1:
phi_i = osc_phases × (π / 180)
phi_j = osc_phases × (π / 180)
delta_phi = phi_i - phi_j
E = |cos(delta_phi)|
matrix_index_ij = i × N + j
matrix_index_ji = j × N + i
entangle_matrix = E
entangle_matrix = E
if E >= threshold:
entangled_pairs += 1
The matrix uses flat array storage with index mapping: index(row, col) = row × N + col.
Phase 5: Phase-Lock Check
max_spread = 0
For i = 0 to N-2:
For j = i+1 to N-1:
delta = |osc_phases - osc_phases |
if delta > 180:
delta = 360 - delta
max_spread = max(max_spread, delta)
phase_locked = (max_spread < tolerance)
Phase 6: Signal Evaluation
Ignition Long :
ignition_long = (CI crosses above threshold) AND
(phi_dom > -90 AND phi_dom < 90) AND
phase_locked AND
(entangled_pairs >= minimum)
Ignition Short :
ignition_short = (CI crosses above threshold) AND
(phi_dom < -90 OR phi_dom > 90) AND
phase_locked AND
(entangled_pairs >= minimum)
Collapse :
CI_prev = CI
collapse = (CI_prev - CI > collapse_threshold) AND (CI_prev > 0.6)
All signals are evaluated on bar close. The crossover and crossunder functions ensure signals fire only once when conditions transition from false to true.
Phase 7: Field Strength and Visualization Metrics
Average Amplitude :
avg_amp = (Σ osc_amps ) / N
Field Strength :
field_strength = CI × avg_amp
Collapse Risk (for dashboard):
collapse_risk = (CI - CI) / max(CI , 0.1)
collapse_risk_pct = clamp(collapse_risk × 100, 0, 100)
Quantum State Classification :
if (CI > threshold AND phase_locked):
state = "Ignition"
else if (CI > 0.6):
state = "Coherent"
else if (collapse):
state = "Collapse"
else:
state = "Chaos"
Phase 8: Visual Rendering
Orbit Plot : For each oscillator, convert polar (phase, amplitude) to Cartesian (x, y) for grid placement:
radius = amplitude × grid_center × 0.8
x = radius × cos(phase × π/180)
y = radius × sin(phase × π/180)
col = center + x (mapped to grid coordinates)
row = center - y
Heat Map : For each oscillator row and time column, retrieve historical phase value at lookback = (columns - col) × sample_rate, then map phase to color using a hue gradient.
Entanglement Web : Render matrix as table cell with background color opacity = E(i,j).
Field Cloud : Background color = (phi_dom > -90 AND phi_dom < 90) ? green : red, with opacity = mix(min_opacity, max_opacity, CI).
All visual components render only on the last bar (barstate.islast) to minimize computational overhead.
How to Use This Indicator
Step 1 : Apply QRFM to your chart. It works on all timeframes and asset classes, though 15-minute to 4-hour timeframes provide the best balance of responsiveness and noise reduction.
Step 2 : Enable the dashboard (default: top right) and the circular orbit plot (default: middle left). These are your primary visual feedback tools.
Step 3 : Optionally enable the heat map, entanglement web, and field cloud based on your preference. New users may find all visuals overwhelming; start with dashboard + orbit plot.
Step 4 : Observe for 50-100 bars to let the indicator establish baseline coherence patterns. Markets have different "normal" CI ranges—some instruments naturally run higher or lower coherence.
Understanding the Circular Orbit Plot
The orbit plot is a polar grid showing oscillator vectors in real-time:
Center point : Neutral (zero phase and amplitude)
Each vector : A line from center to a point on the grid
Vector angle : The oscillator's phase (0° = right/east, 90° = up/north, 180° = left/west, -90° = down/south)
Vector length : The oscillator's amplitude (short = weak signal, long = strong signal)
Vector label : First letter of oscillator name (R = RSI, M = MACD, etc.)
What to watch :
Convergence : When all vectors cluster in one quadrant or sector, CI is rising and coherence is forming. This is your pre-signal warning.
Scatter : When vectors point in random directions (360° spread), CI is low and the market is in a non-trending or transitional regime.
Rotation : When the cluster rotates smoothly around the circle, the ensemble is in coherent oscillation—typically seen during steady trends.
Sudden flips : When the cluster rapidly jumps from one side to the opposite (e.g., +90° to -90°), a phase reversal has occurred—often coinciding with trend reversals.
Example: If you see RSI, MACD, and Stochastic all pointing toward 45° (northeast) with long vectors, while CCI, TSI, and ROC point toward 40-50° as well, coherence is high and dominant phase is bullish. Expect an ignition signal if CI crosses threshold.
Reading Dashboard Metrics
The dashboard provides numerical confirmation of what the orbit plot shows visually:
CI : Displays as 0-100%. Above 70% = high coherence (strong regime), 40-70% = moderate, below 40% = low (poor conditions for trend entries).
Dom Phase : Angle in degrees with directional arrow. ⬆ = bullish bias, ⬇ = bearish bias, ⬌ = neutral.
Field Strength : CI weighted by amplitude. High values (> 0.6) indicate not just alignment but strong alignment.
Entangled Pairs : Count of oscillator pairs with E > threshold. Higher = more confirmation. If minimum is set to 4, you need at least 4 pairs entangled for signals.
Phase Lock : 🔒 YES (all oscillators within tolerance) or 🔓 NO (spread too wide).
State : Real-time classification:
🚀 IGNITION: CI just crossed threshold with phase-lock
⚡ COHERENT: CI is high and stable
💥 COLLAPSE: CI has dropped sharply
🌀 CHAOS: Low CI, scattered phases
Collapse Risk : 0-100% scale based on recent CI change. Above 50% warns of imminent breakdown.
Interpreting Signals
Long Ignition (Blue Triangle Below Price) :
Occurs when CI crosses above threshold (e.g., 0.80)
Dominant phase is in bullish range (-90° to +90°)
All oscillators are phase-locked (within tolerance)
Minimum entangled pairs requirement met
Interpretation : The oscillator ensemble has transitioned from disorder to coherent bullish alignment. This is a high-probability long entry point. The multi-layer confirmation (CI + phase direction + lock + entanglement) ensures this is not a single-oscillator whipsaw.
Short Ignition (Red Triangle Above Price) :
Same conditions as long, but dominant phase is in bearish range (< -90° or > +90°)
Interpretation : Coherent bearish alignment has formed. High-probability short entry.
Collapse (Circles Above and Below Price) :
CI has dropped by more than the collapse threshold (e.g., 0.55) over a 5-bar window
CI was previously above 0.6 (collapsing from coherent state)
Interpretation : Phase coherence has broken down. If you are in a position, this is an exit warning. If looking to enter, stand aside—regime is transitioning.
Phase-Time Heat Map Patterns
Enable the heat map and position it at bottom right. The rows represent individual oscillators, columns represent time bins (most recent on left).
Pattern: Horizontal Color Bands
If a row (e.g., RSI) shows consistent color across columns (say, green for several bins), that oscillator has maintained stable phase over time. If all rows show horizontal bands of similar color, the entire ensemble has been phase-locked for an extended period—this is a strong trending regime.
Pattern: Vertical Color Bands
If a column (single time bin) shows all cells with the same or very similar color, that moment in time had high coherence. These vertical bands often align with ignition signals or major price pivots.
Pattern: Rainbow Chaos
If cells are random colors (red, green, yellow mixed with no pattern), coherence is low. The ensemble is scattered. Avoid trading during these periods unless you have external confirmation.
Pattern: Color Transition
If you see a row transition from red to green (or vice versa) sharply, that oscillator has phase-flipped. If multiple rows do this simultaneously, a regime change is underway.
Entanglement Web Analysis
Enable the web matrix (default: opposite corner from heat map). It shows an N×N grid where N = number of active oscillators.
Bright Yellow/Gold Cells : High pairwise entanglement. For example, if the RSI-MACD cell is bright gold, those two oscillators are moving in phase. If the RSI-Stochastic cell is bright, they are entangled as well.
Dark Gray Cells : Low entanglement. Oscillators are decorrelated or in quadrature.
Diagonal : Always marked with "—" because an oscillator is always perfectly entangled with itself.
How to use :
Scan for clustering: If most cells are bright, coherence is high across the board. If only a few cells are bright, coherence is driven by a subset (e.g., RSI and MACD are aligned, but nothing else is—weak signal).
Identify laggards: If one row/column is entirely dark, that oscillator is the outlier. You may choose to disable it or monitor for when it joins the group (late confirmation).
Watch for web formation: During low-coherence periods, the matrix is mostly dark. As coherence builds, cells begin lighting up. A sudden "web" of connections forming visually precedes ignition signals.
Trading Workflow
Step 1: Monitor Coherence Level
Check the dashboard CI metric or observe the orbit plot. If CI is below 40% and vectors are scattered, conditions are poor for trend entries. Wait.
Step 2: Detect Coherence Building
When CI begins rising (say, from 30% to 50-60%) and you notice vectors on the orbit plot starting to cluster, coherence is forming. This is your alert phase—do not enter yet, but prepare.
Step 3: Confirm Phase Direction
Check the dominant phase angle and the orbit plot quadrant where clustering is occurring:
Clustering in right half (0° to ±90°): Bullish bias forming
Clustering in left half (±90° to 180°): Bearish bias forming
Verify the dashboard shows the corresponding directional arrow (⬆ or ⬇).
Step 4: Wait for Signal Confirmation
Do not enter based on rising CI alone. Wait for the full ignition signal:
CI crosses above threshold
Phase-lock indicator shows 🔒 YES
Entangled pairs count >= minimum
Directional triangle appears on chart
This ensures all layers have aligned.
Step 5: Execute Entry
Long : Blue triangle below price appears → enter long
Short : Red triangle above price appears → enter short
Step 6: Position Management
Initial Stop : Place stop loss based on your risk management rules (e.g., recent swing low/high, ATR-based buffer).
Monitoring :
Watch the field cloud density. If it remains opaque and colored in your direction, the regime is intact.
Check dashboard collapse risk. If it rises above 50%, prepare for exit.
Monitor the orbit plot. If vectors begin scattering or the cluster flips to the opposite side, coherence is breaking.
Exit Triggers :
Collapse signal fires (circles appear)
Dominant phase flips to opposite half-plane
CI drops below 40% (coherence lost)
Price hits your profit target or trailing stop
Step 7: Post-Exit Analysis
After exiting, observe whether a new ignition forms in the opposite direction (reversal) or if CI remains low (transition to range). Use this to decide whether to re-enter, reverse, or stand aside.
Best Practices
Use Price Structure as Context
QRFM identifies when coherence forms but does not specify where price will go. Combine ignition signals with support/resistance levels, trendlines, or chart patterns. For example:
Long ignition near a major support level after a pullback: high-probability bounce
Long ignition in the middle of a range with no structure: lower probability
Multi-Timeframe Confirmation
Open QRFM on two timeframes simultaneously:
Higher timeframe (e.g., 4-hour): Use CI level to determine regime bias. If 4H CI is above 60% and dominant phase is bullish, the market is in a bullish regime.
Lower timeframe (e.g., 15-minute): Execute entries on ignition signals that align with the higher timeframe bias.
This prevents counter-trend trades and increases win rate.
Distinguish Between Regime Types
High CI, stable dominant phase (State: Coherent) : Trending market. Ignitions are continuation signals; collapses are profit-taking or reversal warnings.
Low CI, erratic dominant phase (State: Chaos) : Ranging or choppy market. Avoid ignition signals or reduce position size. Wait for coherence to establish.
Moderate CI with frequent collapses : Whipsaw environment. Use wider stops or stand aside.
Adjust Parameters to Instrument and Timeframe
Crypto/Forex (high volatility) : Lower ignition threshold (0.65-0.75), lower CI smoothing (2-3), shorter oscillator lengths (7-10).
Stocks/Indices (moderate volatility) : Standard settings (threshold 0.75-0.85, smoothing 5-7, oscillator lengths 14).
Lower timeframes (5-15 min) : Reduce phase sample rate to 1-2 for responsiveness.
Higher timeframes (daily+) : Increase CI smoothing and oscillator lengths for noise reduction.
Use Entanglement Count as Conviction Filter
The minimum entangled pairs setting controls signal strictness:
Low (1-2) : More signals, lower quality (acceptable if you have other confirmation)
Medium (3-5) : Balanced (recommended for most traders)
High (6+) : Very strict, fewer signals, highest quality
Adjust based on your trade frequency preference and risk tolerance.
Monitor Oscillator Contribution
Use the entanglement web to see which oscillators are driving coherence. If certain oscillators are consistently dark (low E with all others), they may be adding noise. Consider disabling them. For example:
On low-volume instruments, MFI may be unreliable → disable MFI
On strongly trending instruments, mean-reversion oscillators (Stochastic, RSI) may lag → reduce weight or disable
Respect the Collapse Signal
Collapse events are early warnings. Price may continue in the original direction for several bars after collapse fires, but the underlying regime has weakened. Best practice:
If in profit: Take partial or full profit on collapse
If at breakeven/small loss: Exit immediately
If collapse occurs shortly after entry: Likely a false ignition; exit to avoid drawdown
Collapses do not guarantee immediate reversals—they signal uncertainty .
Combine with Volume Analysis
If your instrument has reliable volume:
Ignitions with expanding volume: Higher conviction
Ignitions with declining volume: Weaker, possibly false
Collapses with volume spikes: Strong reversal signal
Collapses with low volume: May just be consolidation
Volume is not built into QRFM (except via MFI), so add it as external confirmation.
Observe the Phase Spiral
The spiral provides a quick visual cue for rotation consistency:
Tight, smooth spiral : Ensemble is rotating coherently (trending)
Loose, erratic spiral : Phase is jumping around (ranging or transitional)
If the spiral tightens, coherence is building. If it loosens, coherence is dissolving.
Do Not Overtrade Low-Coherence Periods
When CI is persistently below 40% and the state is "Chaos," the market is not in a regime where phase analysis is predictive. During these times:
Reduce position size
Widen stops
Wait for coherence to return
QRFM's strength is regime detection. If there is no regime, the tool correctly signals "stand aside."
Use Alerts Strategically
Set alerts for:
Long Ignition
Short Ignition
Collapse
Phase Lock (optional)
Configure alerts to "Once per bar close" to avoid intrabar repainting and noise. When an alert fires, manually verify:
Orbit plot shows clustering
Dashboard confirms all conditions
Price structure supports the trade
Do not blindly trade alerts—use them as prompts for analysis.
Ideal Market Conditions
Best Performance
Instruments :
Liquid, actively traded markets (major forex pairs, large-cap stocks, major indices, top-tier crypto)
Instruments with clear cyclical oscillator behavior (avoid extremely illiquid or manipulated markets)
Timeframes :
15-minute to 4-hour: Optimal balance of noise reduction and responsiveness
1-hour to daily: Slower, higher-conviction signals; good for swing trading
5-minute: Acceptable for scalping if parameters are tightened and you accept more noise
Market Regimes :
Trending markets with periodic retracements (where oscillators cycle through phases predictably)
Breakout environments (coherence forms before/during breakout; collapse occurs at exhaustion)
Rotational markets with clear swings (oscillators phase-lock at turning points)
Volatility :
Moderate to high volatility (oscillators have room to move through their ranges)
Stable volatility regimes (sudden VIX spikes or flash crashes may create false collapses)
Challenging Conditions
Instruments :
Very low liquidity markets (erratic price action creates unstable oscillator phases)
Heavily news-driven instruments (fundamentals may override technical coherence)
Highly correlated instruments (oscillators may all reflect the same underlying factor, reducing independence)
Market Regimes :
Deep, prolonged consolidation (oscillators remain near neutral, CI is chronically low, few signals fire)
Extreme chop with no directional bias (oscillators whipsaw, coherence never establishes)
Gap-driven markets (large overnight gaps create phase discontinuities)
Timeframes :
Sub-5-minute charts: Noise dominates; oscillators flip rapidly; coherence is fleeting and unreliable
Weekly/monthly: Oscillators move extremely slowly; signals are rare; better suited for long-term positioning than active trading
Special Cases :
During major economic releases or earnings: Oscillators may lag price or become decorrelated as fundamentals overwhelm technicals. Reduce position size or stand aside.
In extremely low-volatility environments (e.g., holiday periods): Oscillators compress to neutral, CI may be artificially high due to lack of movement, but signals lack follow-through.
Adaptive Behavior
QRFM is designed to self-adapt to poor conditions:
When coherence is genuinely absent, CI remains low and signals do not fire
When only a subset of oscillators aligns, entangled pairs count stays below threshold and signals are filtered out
When phase-lock cannot be achieved (oscillators too scattered), the lock filter prevents signals
This means the indicator will naturally produce fewer (or zero) signals during unfavorable conditions, rather than generating false signals. This is a feature —it keeps you out of low-probability trades.
Parameter Optimization by Trading Style
Scalping (5-15 Minute Charts)
Goal : Maximum responsiveness, accept higher noise
Oscillator Lengths :
RSI: 7-10
MACD: 8/17/6
Stochastic: 8-10, smooth 2-3
CCI: 14-16
Others: 8-12
Coherence Settings :
CI Smoothing Window: 2-3 bars (fast reaction)
Phase Sample Rate: 1 (every bar)
Ignition Threshold: 0.65-0.75 (lower for more signals)
Collapse Threshold: 0.40-0.50 (earlier exit warnings)
Confirmation :
Phase Lock Tolerance: 40-50° (looser, easier to achieve)
Min Entangled Pairs: 2-3 (fewer oscillators required)
Visuals :
Orbit Plot + Dashboard only (reduce screen clutter for fast decisions)
Disable heavy visuals (heat map, web) for performance
Alerts :
Enable all ignition and collapse alerts
Set to "Once per bar close"
Day Trading (15-Minute to 1-Hour Charts)
Goal : Balance between responsiveness and reliability
Oscillator Lengths :
RSI: 14 (standard)
MACD: 12/26/9 (standard)
Stochastic: 14, smooth 3
CCI: 20
Others: 10-14
Coherence Settings :
CI Smoothing Window: 3-5 bars (balanced)
Phase Sample Rate: 2-3
Ignition Threshold: 0.75-0.85 (moderate selectivity)
Collapse Threshold: 0.50-0.55 (balanced exit timing)
Confirmation :
Phase Lock Tolerance: 30-40° (moderate tightness)
Min Entangled Pairs: 4-5 (reasonable confirmation)
Visuals :
Orbit Plot + Dashboard + Heat Map or Web (choose one)
Field Cloud for regime backdrop
Alerts :
Ignition and collapse alerts
Optional phase-lock alert for advance warning
Swing Trading (4-Hour to Daily Charts)
Goal : High-conviction signals, minimal noise, fewer trades
Oscillator Lengths :
RSI: 14-21
MACD: 12/26/9 or 19/39/9 (longer variant)
Stochastic: 14-21, smooth 3-5
CCI: 20-30
Others: 14-20
Coherence Settings :
CI Smoothing Window: 5-10 bars (very smooth)
Phase Sample Rate: 3-5
Ignition Threshold: 0.80-0.90 (high bar for entry)
Collapse Threshold: 0.55-0.65 (only significant breakdowns)
Confirmation :
Phase Lock Tolerance: 20-30° (tight clustering required)
Min Entangled Pairs: 5-7 (strong confirmation)
Visuals :
All modules enabled (you have time to analyze)
Heat Map for multi-bar pattern recognition
Web for deep confirmation analysis
Alerts :
Ignition and collapse
Review manually before entering (no rush)
Position/Long-Term Trading (Daily to Weekly Charts)
Goal : Rare, very high-conviction regime shifts
Oscillator Lengths :
RSI: 21-30
MACD: 19/39/9 or 26/52/12
Stochastic: 21, smooth 5
CCI: 30-50
Others: 20-30
Coherence Settings :
CI Smoothing Window: 10-14 bars
Phase Sample Rate: 5 (every 5th bar to reduce computation)
Ignition Threshold: 0.85-0.95 (only extreme alignment)
Collapse Threshold: 0.60-0.70 (major regime breaks only)
Confirmation :
Phase Lock Tolerance: 15-25° (very tight)
Min Entangled Pairs: 6+ (broad consensus required)
Visuals :
Dashboard + Orbit Plot for quick checks
Heat Map to study historical coherence patterns
Web to verify deep entanglement
Alerts :
Ignition only (collapses are less critical on long timeframes)
Manual review with fundamental analysis overlay
Performance Optimization (Low-End Systems)
If you experience lag or slow rendering:
Reduce Visual Load :
Orbit Grid Size: 8-10 (instead of 12+)
Heat Map Time Bins: 5-8 (instead of 10+)
Disable Web Matrix entirely if not needed
Disable Field Cloud and Phase Spiral
Reduce Calculation Frequency :
Phase Sample Rate: 5-10 (calculate every 5-10 bars)
Max History Depth: 100-200 (instead of 500+)
Disable Unused Oscillators :
If you only want RSI, MACD, and Stochastic, disable the other five. Fewer oscillators = smaller matrices, faster loops.
Simplify Dashboard :
Choose "Small" dashboard size
Reduce number of metrics displayed
These settings will not significantly degrade signal quality (signals are based on bar-close calculations, which remain accurate), but will improve chart responsiveness.
Important Disclaimers
This indicator is a technical analysis tool designed to identify periods of phase coherence across an ensemble of oscillators. It is not a standalone trading system and does not guarantee profitable trades. The Coherence Index, dominant phase, and entanglement metrics are mathematical calculations applied to historical price data—they measure past oscillator behavior and do not predict future price movements with certainty.
No Predictive Guarantee : High coherence indicates that oscillators are currently aligned, which historically has coincided with trending or directional price movement. However, past alignment does not guarantee future trends. Markets can remain coherent while prices consolidate, or lose coherence suddenly due to news, liquidity changes, or other factors not captured by oscillator mathematics.
Signal Confirmation is Probabilistic : The multi-layer confirmation system (CI threshold + dominant phase + phase-lock + entanglement) is designed to filter out low-probability setups. This increases the proportion of valid signals relative to false signals, but does not eliminate false signals entirely. Users should combine QRFM with additional analysis—support and resistance levels, volume confirmation, multi-timeframe alignment, and fundamental context—before executing trades.
Collapse Signals are Warnings, Not Reversals : A coherence collapse indicates that the oscillator ensemble has lost alignment. This often precedes trend exhaustion or reversals, but can also occur during healthy pullbacks or consolidations. Price may continue in the original direction after a collapse. Use collapses as risk management cues (tighten stops, take partial profits) rather than automatic reversal entries.
Market Regime Dependency : QRFM performs best in markets where oscillators exhibit cyclical, mean-reverting behavior and where trends are punctuated by retracements. In markets dominated by fundamental shocks, gap openings, or extreme low-liquidity conditions, oscillator coherence may be less reliable. During such periods, reduce position size or stand aside.
Risk Management is Essential : All trading involves risk of loss. Use appropriate stop losses, position sizing, and risk-per-trade limits. The indicator does not specify stop loss or take profit levels—these must be determined by the user based on their risk tolerance and account size. Never risk more than you can afford to lose.
Parameter Sensitivity : The indicator's behavior changes with input parameters. Aggressive settings (low thresholds, loose tolerances) produce more signals with lower average quality. Conservative settings (high thresholds, tight tolerances) produce fewer signals with higher average quality. Users should backtest and forward-test parameter sets on their specific instruments and timeframes before committing real capital.
No Repainting by Design : All signal conditions are evaluated on bar close using bar-close values. However, the visual components (orbit plot, heat map, dashboard) update in real-time during bar formation for monitoring purposes. For trade execution, rely on the confirmed signals (triangles and circles) that appear only after the bar closes.
Computational Load : QRFM performs extensive calculations, including nested loops for entanglement matrices and real-time table rendering. On lower-powered devices or when running multiple indicators simultaneously, users may experience lag. Use the performance optimization settings (reduce visual complexity, increase phase sample rate, disable unused oscillators) to improve responsiveness.
This system is most effective when used as one component within a broader trading methodology that includes sound risk management, multi-timeframe analysis, market context awareness, and disciplined execution. It is a tool for regime detection and signal confirmation, not a substitute for comprehensive trade planning.
Technical Notes
Calculation Timing : All signal logic (ignition, collapse) is evaluated using bar-close values. The barstate.isconfirmed or implicit bar-close behavior ensures signals do not repaint. Visual components (tables, plots) render on every tick for real-time feedback but do not affect signal generation.
Phase Wrapping : Phase angles are calculated in the range -180° to +180° using atan2. Angular distance calculations account for wrapping (e.g., the distance between +170° and -170° is 20°, not 340°). This ensures phase-lock detection works correctly across the ±180° boundary.
Array Management : The indicator uses fixed-size arrays for oscillator phases, amplitudes, and the entanglement matrix. The maximum number of oscillators is 8. If fewer oscillators are enabled, array sizes shrink accordingly (only active oscillators are processed).
Matrix Indexing : The entanglement matrix is stored as a flat array with size N×N, where N is the number of active oscillators. Index mapping: index(row, col) = row × N + col. Symmetric pairs (i,j) and (j,i) are stored identically.
Normalization Stability : Oscillators are normalized to using fixed reference levels (e.g., RSI overbought/oversold at 70/30). For unbounded oscillators (MACD, ROC, TSI), statistical normalization (division by rolling standard deviation) is used, with clamping to prevent extreme outliers from distorting phase calculations.
Smoothing and Lag : The CI smoothing window (SMA) introduces lag proportional to the window size. This is intentional—it filters out single-bar noise spikes in coherence. Users requiring faster reaction can reduce the smoothing window to 1-2 bars, at the cost of increased sensitivity to noise.
Complex Number Representation : Pine Script does not have native complex number types. Complex arithmetic is implemented using separate real and imaginary accumulators (sum_cos, sum_sin) and manual calculation of magnitude (sqrt(real² + imag²)) and argument (atan2(imag, real)).
Lookback Limits : The indicator respects Pine Script's maximum lookback constraints. Historical phase and amplitude values are accessed using the operator, with lookback limited to the chart's available bar history (max_bars_back=5000 declared).
Visual Rendering Performance : Tables (orbit plot, heat map, web, dashboard) are conditionally deleted and recreated on each update using table.delete() and table.new(). This prevents memory leaks but incurs redraw overhead. Rendering is restricted to barstate.islast (last bar) to minimize computational load—historical bars do not render visuals.
Alert Condition Triggers : alertcondition() functions evaluate on bar close when their boolean conditions transition from false to true. Alerts do not fire repeatedly while a condition remains true (e.g., CI stays above threshold for 10 bars fires only once on the initial cross).
Color Gradient Functions : The phaseColor() function maps phase angles to RGB hues using sine waves offset by 120° (red, green, blue channels). This creates a continuous spectrum where -180° to +180° spans the full color wheel. The amplitudeColor() function maps amplitude to grayscale intensity. The coherenceColor() function uses cos(phase) to map contribution to CI (positive = green, negative = red).
No External Data Requests : QRFM operates entirely on the chart's symbol and timeframe. It does not use request.security() or access external data sources. All calculations are self-contained, avoiding lookahead bias from higher-timeframe requests.
Deterministic Behavior : Given identical input parameters and price data, QRFM produces identical outputs. There are no random elements, probabilistic sampling, or time-of-day dependencies.
— Dskyz, Engineering precision. Trading coherence.

Dynamic Equity Allocation Model"Cash is Trash"? Not Always. Here's Why Science Beats Guesswork.
Every retail trader knows the frustration: you draw support and resistance lines, you spot patterns, you follow market gurus on social media—and still, when the next bear market hits, your portfolio bleeds red. Meanwhile, institutional investors seem to navigate market turbulence with ease, preserving capital when markets crash and participating when they rally. What's their secret?
The answer isn't insider information or access to exotic derivatives. It's systematic, scientifically validated decision-making. While most retail traders rely on subjective chart analysis and emotional reactions, professional portfolio managers use quantitative models that remove emotion from the equation and process multiple streams of market information simultaneously.
This document presents exactly such a system—not a proprietary black box available only to hedge funds, but a fully transparent, academically grounded framework that any serious investor can understand and apply. The Dynamic Equity Allocation Model (DEAM) synthesizes decades of financial research from Nobel laureates and leading academics into a practical tool for tactical asset allocation.
Stop drawing colorful lines on your chart and start thinking like a quant. This isn't about predicting where the market goes next week—it's about systematically adjusting your risk exposure based on what the data actually tells you. When valuations scream danger, when volatility spikes, when credit markets freeze, when multiple warning signals align—that's when cash isn't trash. That's when cash saves your portfolio.
The irony of "cash is trash" rhetoric is that it ignores timing. Yes, being 100% cash for decades would be disastrous. But being 100% equities through every crisis is equally foolish. The sophisticated approach is dynamic: aggressive when conditions favor risk-taking, defensive when they don't. This model shows you how to make that decision systematically, not emotionally.
Whether you're managing your own retirement portfolio or seeking to understand how institutional allocation strategies work, this comprehensive analysis provides the theoretical foundation, mathematical implementation, and practical guidance to elevate your investment approach from amateur to professional.
The choice is yours: keep hoping your chart patterns work out, or start using the same quantitative methods that professionals rely on. The tools are here. The research is cited. The methodology is explained. All you need to do is read, understand, and apply.
The Dynamic Equity Allocation Model (DEAM) is a quantitative framework for systematic allocation between equities and cash, grounded in modern portfolio theory and empirical market research. The model integrates five scientifically validated dimensions of market analysis—market regime, risk metrics, valuation, sentiment, and macroeconomic conditions—to generate dynamic allocation recommendations ranging from 0% to 100% equity exposure. This work documents the theoretical foundations, mathematical implementation, and practical application of this multi-factor approach.
1. Introduction and Theoretical Background
1.1 The Limitations of Static Portfolio Allocation
Traditional portfolio theory, as formulated by Markowitz (1952) in his seminal work "Portfolio Selection," assumes an optimal static allocation where investors distribute their wealth across asset classes according to their risk aversion. This approach rests on the assumption that returns and risks remain constant over time. However, empirical research demonstrates that this assumption does not hold in reality. Fama and French (1989) showed that expected returns vary over time and correlate with macroeconomic variables such as the spread between long-term and short-term interest rates. Campbell and Shiller (1988) demonstrated that the price-earnings ratio possesses predictive power for future stock returns, providing a foundation for dynamic allocation strategies.
The academic literature on tactical asset allocation has evolved considerably over recent decades. Ilmanen (2011) argues in "Expected Returns" that investors can improve their risk-adjusted returns by considering valuation levels, business cycles, and market sentiment. The Dynamic Equity Allocation Model presented here builds on this research tradition and operationalizes these insights into a practically applicable allocation framework.
1.2 Multi-Factor Approaches in Asset Allocation
Modern financial research has shown that different factors capture distinct aspects of market dynamics and together provide a more robust picture of market conditions than individual indicators. Ross (1976) developed the Arbitrage Pricing Theory, a model that employs multiple factors to explain security returns. Following this multi-factor philosophy, DEAM integrates five complementary analytical dimensions, each tapping different information sources and collectively enabling comprehensive market understanding.
2. Data Foundation and Data Quality
2.1 Data Sources Used
The model draws its data exclusively from publicly available market data via the TradingView platform. This transparency and accessibility is a significant advantage over proprietary models that rely on non-public data. The data foundation encompasses several categories of market information, each capturing specific aspects of market dynamics.
First, price data for the S&P 500 Index is obtained through the SPDR S&P 500 ETF (ticker: SPY). The use of a highly liquid ETF instead of the index itself has practical reasons, as ETF data is available in real-time and reflects actual tradability. In addition to closing prices, high, low, and volume data are captured, which are required for calculating advanced volatility measures.
Fundamental corporate metrics are retrieved via TradingView's Financial Data API. These include earnings per share, price-to-earnings ratio, return on equity, debt-to-equity ratio, dividend yield, and share buyback yield. Cochrane (2011) emphasizes in "Presidential Address: Discount Rates" the central importance of valuation metrics for forecasting future returns, making these fundamental data a cornerstone of the model.
Volatility indicators are represented by the CBOE Volatility Index (VIX) and related metrics. The VIX, often referred to as the market's "fear gauge," measures the implied volatility of S&P 500 index options and serves as a proxy for market participants' risk perception. Whaley (2000) describes in "The Investor Fear Gauge" the construction and interpretation of the VIX and its use as a sentiment indicator.
Macroeconomic data includes yield curve information through US Treasury bonds of various maturities and credit risk premiums through the spread between high-yield bonds and risk-free government bonds. These variables capture the macroeconomic conditions and financing conditions relevant for equity valuation. Estrella and Hardouvelis (1991) showed that the shape of the yield curve has predictive power for future economic activity, justifying the inclusion of these data.
2.2 Handling Missing Data
A practical problem when working with financial data is dealing with missing or unavailable values. The model implements a fallback system where a plausible historical average value is stored for each fundamental metric. When current data is unavailable for a specific point in time, this fallback value is used. This approach ensures that the model remains functional even during temporary data outages and avoids systematic biases from missing data. The use of average values as fallback is conservative, as it generates neither overly optimistic nor pessimistic signals.
3. Component 1: Market Regime Detection
3.1 The Concept of Market Regimes
The idea that financial markets exist in different "regimes" or states that differ in their statistical properties has a long tradition in financial science. Hamilton (1989) developed regime-switching models that allow distinguishing between different market states with different return and volatility characteristics. The practical application of this theory consists of identifying the current market state and adjusting portfolio allocation accordingly.
DEAM classifies market regimes using a scoring system that considers three main dimensions: trend strength, volatility level, and drawdown depth. This multidimensional view is more robust than focusing on individual indicators, as it captures various facets of market dynamics. Classification occurs into six distinct regimes: Strong Bull, Bull Market, Neutral, Correction, Bear Market, and Crisis.
3.2 Trend Analysis Through Moving Averages
Moving averages are among the oldest and most widely used technical indicators and have also received attention in academic literature. Brock, Lakonishok, and LeBaron (1992) examined in "Simple Technical Trading Rules and the Stochastic Properties of Stock Returns" the profitability of trading rules based on moving averages and found evidence for their predictive power, although later studies questioned the robustness of these results when considering transaction costs.
The model calculates three moving averages with different time windows: a 20-day average (approximately one trading month), a 50-day average (approximately one quarter), and a 200-day average (approximately one trading year). The relationship of the current price to these averages and the relationship of the averages to each other provide information about trend strength and direction. When the price trades above all three averages and the short-term average is above the long-term, this indicates an established uptrend. The model assigns points based on these constellations, with longer-term trends weighted more heavily as they are considered more persistent.
3.3 Volatility Regimes
Volatility, understood as the standard deviation of returns, is a central concept of financial theory and serves as the primary risk measure. However, research has shown that volatility is not constant but changes over time and occurs in clusters—a phenomenon first documented by Mandelbrot (1963) and later formalized through ARCH and GARCH models (Engle, 1982; Bollerslev, 1986).
DEAM calculates volatility not only through the classic method of return standard deviation but also uses more advanced estimators such as the Parkinson estimator and the Garman-Klass estimator. These methods utilize intraday information (high and low prices) and are more efficient than simple close-to-close volatility estimators. The Parkinson estimator (Parkinson, 1980) uses the range between high and low of a trading day and is based on the recognition that this information reveals more about true volatility than just the closing price difference. The Garman-Klass estimator (Garman and Klass, 1980) extends this approach by additionally considering opening and closing prices.
The calculated volatility is annualized by multiplying it by the square root of 252 (the average number of trading days per year), enabling standardized comparability. The model compares current volatility with the VIX, the implied volatility from option prices. A low VIX (below 15) signals market comfort and increases the regime score, while a high VIX (above 35) indicates market stress and reduces the score. This interpretation follows the empirical observation that elevated volatility is typically associated with falling markets (Schwert, 1989).
3.4 Drawdown Analysis
A drawdown refers to the percentage decline from the highest point (peak) to the lowest point (trough) during a specific period. This metric is psychologically significant for investors as it represents the maximum loss experienced. Calmar (1991) developed the Calmar Ratio, which relates return to maximum drawdown, underscoring the practical relevance of this metric.
The model calculates current drawdown as the percentage distance from the highest price of the last 252 trading days (one year). A drawdown below 3% is considered negligible and maximally increases the regime score. As drawdown increases, the score decreases progressively, with drawdowns above 20% classified as severe and indicating a crisis or bear market regime. These thresholds are empirically motivated by historical market cycles, in which corrections typically encompassed 5-10% drawdowns, bear markets 20-30%, and crises over 30%.
3.5 Regime Classification
Final regime classification occurs through aggregation of scores from trend (40% weight), volatility (30%), and drawdown (30%). The higher weighting of trend reflects the empirical observation that trend-following strategies have historically delivered robust results (Moskowitz, Ooi, and Pedersen, 2012). A total score above 80 signals a strong bull market with established uptrend, low volatility, and minimal losses. At a score below 10, a crisis situation exists requiring defensive positioning. The six regime categories enable a differentiated allocation strategy that not only distinguishes binarily between bullish and bearish but allows gradual gradations.
4. Component 2: Risk-Based Allocation
4.1 Volatility Targeting as Risk Management Approach
The concept of volatility targeting is based on the idea that investors should maximize not returns but risk-adjusted returns. Sharpe (1966, 1994) defined with the Sharpe Ratio the fundamental concept of return per unit of risk, measured as volatility. Volatility targeting goes a step further and adjusts portfolio allocation to achieve constant target volatility. This means that in times of low market volatility, equity allocation is increased, and in times of high volatility, it is reduced.
Moreira and Muir (2017) showed in "Volatility-Managed Portfolios" that strategies that adjust their exposure based on volatility forecasts achieve higher Sharpe Ratios than passive buy-and-hold strategies. DEAM implements this principle by defining a target portfolio volatility (default 12% annualized) and adjusting equity allocation to achieve it. The mathematical foundation is simple: if market volatility is 20% and target volatility is 12%, equity allocation should be 60% (12/20 = 0.6), with the remaining 40% held in cash with zero volatility.
4.2 Market Volatility Calculation
Estimating current market volatility is central to the risk-based allocation approach. The model uses several volatility estimators in parallel and selects the higher value between traditional close-to-close volatility and the Parkinson estimator. This conservative choice ensures the model does not underestimate true volatility, which could lead to excessive risk exposure.
Traditional volatility calculation uses logarithmic returns, as these have mathematically advantageous properties (additive linkage over multiple periods). The logarithmic return is calculated as ln(P_t / P_{t-1}), where P_t is the price at time t. The standard deviation of these returns over a rolling 20-trading-day window is then multiplied by √252 to obtain annualized volatility. This annualization is based on the assumption of independently identically distributed returns, which is an idealization but widely accepted in practice.
The Parkinson estimator uses additional information from the trading range (High minus Low) of each day. The formula is: σ_P = (1/√(4ln2)) × √(1/n × Σln²(H_i/L_i)) × √252, where H_i and L_i are high and low prices. Under ideal conditions, this estimator is approximately five times more efficient than the close-to-close estimator (Parkinson, 1980), as it uses more information per observation.
4.3 Drawdown-Based Position Size Adjustment
In addition to volatility targeting, the model implements drawdown-based risk control. The logic is that deep market declines often signal further losses and therefore justify exposure reduction. This behavior corresponds with the concept of path-dependent risk tolerance: investors who have already suffered losses are typically less willing to take additional risk (Kahneman and Tversky, 1979).
The model defines a maximum portfolio drawdown as a target parameter (default 15%). Since portfolio volatility and portfolio drawdown are proportional to equity allocation (assuming cash has neither volatility nor drawdown), allocation-based control is possible. For example, if the market exhibits a 25% drawdown and target portfolio drawdown is 15%, equity allocation should be at most 60% (15/25).
4.4 Dynamic Risk Adjustment
An advanced feature of DEAM is dynamic adjustment of risk-based allocation through a feedback mechanism. The model continuously estimates what actual portfolio volatility and portfolio drawdown would result at the current allocation. If risk utilization (ratio of actual to target risk) exceeds 1.0, allocation is reduced by an adjustment factor that grows exponentially with overutilization. This implements a form of dynamic feedback that avoids overexposure.
Mathematically, a risk adjustment factor r_adjust is calculated: if risk utilization u > 1, then r_adjust = exp(-0.5 × (u - 1)). This exponential function ensures that moderate overutilization is gently corrected, while strong overutilization triggers drastic reductions. The factor 0.5 in the exponent was empirically calibrated to achieve a balanced ratio between sensitivity and stability.
5. Component 3: Valuation Analysis
5.1 Theoretical Foundations of Fundamental Valuation
DEAM's valuation component is based on the fundamental premise that the intrinsic value of a security is determined by its future cash flows and that deviations between market price and intrinsic value are eventually corrected. Graham and Dodd (1934) established in "Security Analysis" the basic principles of fundamental analysis that remain relevant today. Translated into modern portfolio context, this means that markets with high valuation metrics (high price-earnings ratios) should have lower expected returns than cheaply valued markets.
Campbell and Shiller (1988) developed the Cyclically Adjusted P/E Ratio (CAPE), which smooths earnings over a full business cycle. Their empirical analysis showed that this ratio has significant predictive power for 10-year returns. Asness, Moskowitz, and Pedersen (2013) demonstrated in "Value and Momentum Everywhere" that value effects exist not only in individual stocks but also in asset classes and markets.
5.2 Equity Risk Premium as Central Valuation Metric
The Equity Risk Premium (ERP) is defined as the expected excess return of stocks over risk-free government bonds. It is the theoretical heart of valuation analysis, as it represents the compensation investors demand for bearing equity risk. Damodaran (2012) discusses in "Equity Risk Premiums: Determinants, Estimation and Implications" various methods for ERP estimation.
DEAM calculates ERP not through a single method but combines four complementary approaches with different weights. This multi-method strategy increases estimation robustness and avoids dependence on single, potentially erroneous inputs.
The first method (35% weight) uses earnings yield, calculated as 1/P/E or directly from operating earnings data, and subtracts the 10-year Treasury yield. This method follows Fed Model logic (Yardeni, 2003), although this model has theoretical weaknesses as it does not consistently treat inflation (Asness, 2003).
The second method (30% weight) extends earnings yield by share buyback yield. Share buybacks are a form of capital return to shareholders and increase value per share. Boudoukh et al. (2007) showed in "The Total Shareholder Yield" that the sum of dividend yield and buyback yield is a better predictor of future returns than dividend yield alone.
The third method (20% weight) implements the Gordon Growth Model (Gordon, 1962), which models stock value as the sum of discounted future dividends. Under constant growth g assumption: Expected Return = Dividend Yield + g. The model estimates sustainable growth as g = ROE × (1 - Payout Ratio), where ROE is return on equity and payout ratio is the ratio of dividends to earnings. This formula follows from equity theory: unretained earnings are reinvested at ROE and generate additional earnings growth.
The fourth method (15% weight) combines total shareholder yield (Dividend + Buybacks) with implied growth derived from revenue growth. This method considers that companies with strong revenue growth should generate higher future earnings, even if current valuations do not yet fully reflect this.
The final ERP is the weighted average of these four methods. A high ERP (above 4%) signals attractive valuations and increases the valuation score to 95 out of 100 possible points. A negative ERP, where stocks have lower expected returns than bonds, results in a minimal score of 10.
5.3 Quality Adjustments to Valuation
Valuation metrics alone can be misleading if not interpreted in the context of company quality. A company with a low P/E may be cheap or fundamentally problematic. The model therefore implements quality adjustments based on growth, profitability, and capital structure.
Revenue growth above 10% annually adds 10 points to the valuation score, moderate growth above 5% adds 5 points. This adjustment reflects that growth has independent value (Modigliani and Miller, 1961, extended by later growth theory). Net margin above 15% signals pricing power and operational efficiency and increases the score by 5 points, while low margins below 8% indicate competitive pressure and subtract 5 points.
Return on equity (ROE) above 20% characterizes outstanding capital efficiency and increases the score by 5 points. Piotroski (2000) showed in "Value Investing: The Use of Historical Financial Statement Information" that fundamental quality signals such as high ROE can improve the performance of value strategies.
Capital structure is evaluated through the debt-to-equity ratio. A conservative ratio below 1.0 multiplies the valuation score by 1.2, while high leverage above 2.0 applies a multiplier of 0.8. This adjustment reflects that high debt constrains financial flexibility and can become problematic in crisis times (Korteweg, 2010).
6. Component 4: Sentiment Analysis
6.1 The Role of Sentiment in Financial Markets
Investor sentiment, defined as the collective psychological attitude of market participants, influences asset prices independently of fundamental data. Baker and Wurgler (2006, 2007) developed a sentiment index and showed that periods of high sentiment are followed by overvaluations that later correct. This insight justifies integrating a sentiment component into allocation decisions.
Sentiment is difficult to measure directly but can be proxied through market indicators. The VIX is the most widely used sentiment indicator, as it aggregates implied volatility from option prices. High VIX values reflect elevated uncertainty and risk aversion, while low values signal market comfort. Whaley (2009) refers to the VIX as the "Investor Fear Gauge" and documents its role as a contrarian indicator: extremely high values typically occur at market bottoms, while low values occur at tops.
6.2 VIX-Based Sentiment Assessment
DEAM uses statistical normalization of the VIX by calculating the Z-score: z = (VIX_current - VIX_average) / VIX_standard_deviation. The Z-score indicates how many standard deviations the current VIX is from the historical average. This approach is more robust than absolute thresholds, as it adapts to the average volatility level, which can vary over longer periods.
A Z-score below -1.5 (VIX is 1.5 standard deviations below average) signals exceptionally low risk perception and adds 40 points to the sentiment score. This may seem counterintuitive—shouldn't low fear be bullish? However, the logic follows the contrarian principle: when no one is afraid, everyone is already invested, and there is limited further upside potential (Zweig, 1973). Conversely, a Z-score above 1.5 (extreme fear) adds -40 points, reflecting market panic but simultaneously suggesting potential buying opportunities.
6.3 VIX Term Structure as Sentiment Signal
The VIX term structure provides additional sentiment information. Normally, the VIX trades in contango, meaning longer-term VIX futures have higher prices than short-term. This reflects that short-term volatility is currently known, while long-term volatility is more uncertain and carries a risk premium. The model compares the VIX with VIX9D (9-day volatility) and identifies backwardation (VIX > 1.05 × VIX9D) and steep backwardation (VIX > 1.15 × VIX9D).
Backwardation occurs when short-term implied volatility is higher than longer-term, which typically happens during market stress. Investors anticipate immediate turbulence but expect calming. Psychologically, this reflects acute fear. The model subtracts 15 points for backwardation and 30 for steep backwardation, as these constellations signal elevated risk. Simon and Wiggins (2001) analyzed the VIX futures curve and showed that backwardation is associated with market declines.
6.4 Safe-Haven Flows
During crisis times, investors flee from risky assets into safe havens: gold, US dollar, and Japanese yen. This "flight to quality" is a sentiment signal. The model calculates the performance of these assets relative to stocks over the last 20 trading days. When gold or the dollar strongly rise while stocks fall, this indicates elevated risk aversion.
The safe-haven component is calculated as the difference between safe-haven performance and stock performance. Positive values (safe havens outperform) subtract up to 20 points from the sentiment score, negative values (stocks outperform) add up to 10 points. The asymmetric treatment (larger deduction for risk-off than bonus for risk-on) reflects that risk-off movements are typically sharper and more informative than risk-on phases.
Baur and Lucey (2010) examined safe-haven properties of gold and showed that gold indeed exhibits negative correlation with stocks during extreme market movements, confirming its role as crisis protection.
7. Component 5: Macroeconomic Analysis
7.1 The Yield Curve as Economic Indicator
The yield curve, represented as yields of government bonds of various maturities, contains aggregated expectations about future interest rates, inflation, and economic growth. The slope of the yield curve has remarkable predictive power for recessions. Estrella and Mishkin (1998) showed that an inverted yield curve (short-term rates higher than long-term) predicts recessions with high reliability. This is because inverted curves reflect restrictive monetary policy: the central bank raises short-term rates to combat inflation, dampening economic activity.
DEAM calculates two spread measures: the 2-year-minus-10-year spread and the 3-month-minus-10-year spread. A steep, positive curve (spreads above 1.5% and 2% respectively) signals healthy growth expectations and generates the maximum yield curve score of 40 points. A flat curve (spreads near zero) reduces the score to 20 points. An inverted curve (negative spreads) is particularly alarming and results in only 10 points.
The choice of two different spreads increases analysis robustness. The 2-10 spread is most established in academic literature, while the 3M-10Y spread is often considered more sensitive, as the 3-month rate directly reflects current monetary policy (Ang, Piazzesi, and Wei, 2006).
7.2 Credit Conditions and Spreads
Credit spreads—the yield difference between risky corporate bonds and safe government bonds—reflect risk perception in the credit market. Gilchrist and Zakrajšek (2012) constructed an "Excess Bond Premium" that measures the component of credit spreads not explained by fundamentals and showed this is a predictor of future economic activity and stock returns.
The model approximates credit spread by comparing the yield of high-yield bond ETFs (HYG) with investment-grade bond ETFs (LQD). A narrow spread below 200 basis points signals healthy credit conditions and risk appetite, contributing 30 points to the macro score. Very wide spreads above 1000 basis points (as during the 2008 financial crisis) signal credit crunch and generate zero points.
Additionally, the model evaluates whether "flight to quality" is occurring, identified through strong performance of Treasury bonds (TLT) with simultaneous weakness in high-yield bonds. This constellation indicates elevated risk aversion and reduces the credit conditions score.
7.3 Financial Stability at Corporate Level
While the yield curve and credit spreads reflect macroeconomic conditions, financial stability evaluates the health of companies themselves. The model uses the aggregated debt-to-equity ratio and return on equity of the S&P 500 as proxies for corporate health.
A low leverage level below 0.5 combined with high ROE above 15% signals robust corporate balance sheets and generates 20 points. This combination is particularly valuable as it represents both defensive strength (low debt means crisis resistance) and offensive strength (high ROE means earnings power). High leverage above 1.5 generates only 5 points, as it implies vulnerability to interest rate increases and recessions.
Korteweg (2010) showed in "The Net Benefits to Leverage" that optimal debt maximizes firm value, but excessive debt increases distress costs. At the aggregated market level, high debt indicates fragilities that can become problematic during stress phases.
8. Component 6: Crisis Detection
8.1 The Need for Systematic Crisis Detection
Financial crises are rare but extremely impactful events that suspend normal statistical relationships. During normal market volatility, diversified portfolios and traditional risk management approaches function, but during systemic crises, seemingly independent assets suddenly correlate strongly, and losses exceed historical expectations (Longin and Solnik, 2001). This justifies a separate crisis detection mechanism that operates independently of regular allocation components.
Reinhart and Rogoff (2009) documented in "This Time Is Different: Eight Centuries of Financial Folly" recurring patterns in financial crises: extreme volatility, massive drawdowns, credit market dysfunction, and asset price collapse. DEAM operationalizes these patterns into quantifiable crisis indicators.
8.2 Multi-Signal Crisis Identification
The model uses a counter-based approach where various stress signals are identified and aggregated. This methodology is more robust than relying on a single indicator, as true crises typically occur simultaneously across multiple dimensions. A single signal may be a false alarm, but the simultaneous presence of multiple signals increases confidence.
The first indicator is a VIX above the crisis threshold (default 40), adding one point. A VIX above 60 (as in 2008 and March 2020) adds two additional points, as such extreme values are historically very rare. This tiered approach captures the intensity of volatility.
The second indicator is market drawdown. A drawdown above 15% adds one point, as corrections of this magnitude can be potential harbingers of larger crises. A drawdown above 25% adds another point, as historical bear markets typically encompass 25-40% drawdowns.
The third indicator is credit market spreads above 500 basis points, adding one point. Such wide spreads occur only during significant credit market disruptions, as in 2008 during the Lehman crisis.
The fourth indicator identifies simultaneous losses in stocks and bonds. Normally, Treasury bonds act as a hedge against equity risk (negative correlation), but when both fall simultaneously, this indicates systemic liquidity problems or inflation/stagflation fears. The model checks whether both SPY and TLT have fallen more than 10% and 5% respectively over 5 trading days, adding two points.
The fifth indicator is a volume spike combined with negative returns. Extreme trading volumes (above twice the 20-day average) with falling prices signal panic selling. This adds one point.
A crisis situation is diagnosed when at least 3 indicators trigger, a severe crisis at 5 or more indicators. These thresholds were calibrated through historical backtesting to identify true crises (2008, 2020) without generating excessive false alarms.
8.3 Crisis-Based Allocation Override
When a crisis is detected, the system overrides the normal allocation recommendation and caps equity allocation at maximum 25%. In a severe crisis, the cap is set at 10%. This drastic defensive posture follows the empirical observation that crises typically require time to develop and that early reduction can avoid substantial losses (Faber, 2007).
This override logic implements a "safety first" principle: in situations of existential danger to the portfolio, capital preservation becomes the top priority. Roy (1952) formalized this approach in "Safety First and the Holding of Assets," arguing that investors should primarily minimize ruin probability.
9. Integration and Final Allocation Calculation
9.1 Component Weighting
The final allocation recommendation emerges through weighted aggregation of the five components. The standard weighting is: Market Regime 35%, Risk Management 25%, Valuation 20%, Sentiment 15%, Macro 5%. These weights reflect both theoretical considerations and empirical backtesting results.
The highest weighting of market regime is based on evidence that trend-following and momentum strategies have delivered robust results across various asset classes and time periods (Moskowitz, Ooi, and Pedersen, 2012). Current market momentum is highly informative for the near future, although it provides no information about long-term expectations.
The substantial weighting of risk management (25%) follows from the central importance of risk control. Wealth preservation is the foundation of long-term wealth creation, and systematic risk management is demonstrably value-creating (Moreira and Muir, 2017).
The valuation component receives 20% weight, based on the long-term mean reversion of valuation metrics. While valuation has limited short-term predictive power (bull and bear markets can begin at any valuation), the long-term relationship between valuation and returns is robustly documented (Campbell and Shiller, 1988).
Sentiment (15%) and Macro (5%) receive lower weights, as these factors are subtler and harder to measure. Sentiment is valuable as a contrarian indicator at extremes but less informative in normal ranges. Macro variables such as the yield curve have strong predictive power for recessions, but the transmission from recessions to stock market performance is complex and temporally variable.
9.2 Model Type Adjustments
DEAM allows users to choose between four model types: Conservative, Balanced, Aggressive, and Adaptive. This choice modifies the final allocation through additive adjustments.
Conservative mode subtracts 10 percentage points from allocation, resulting in consistently more cautious positioning. This is suitable for risk-averse investors or those with limited investment horizons. Aggressive mode adds 10 percentage points, suitable for risk-tolerant investors with long horizons.
Adaptive mode implements procyclical adjustment based on short-term momentum: if the market has risen more than 5% in the last 20 days, 5 percentage points are added; if it has declined more than 5%, 5 points are subtracted. This logic follows the observation that short-term momentum persists (Jegadeesh and Titman, 1993), but the moderate size of adjustment avoids excessive timing bets.
Balanced mode makes no adjustment and uses raw model output. This neutral setting is suitable for investors who wish to trust model recommendations unchanged.
9.3 Smoothing and Stability
The allocation resulting from aggregation undergoes final smoothing through a simple moving average over 3 periods. This smoothing is crucial for model practicality, as it reduces frequent trading and thus transaction costs. Without smoothing, the model could fluctuate between adjacent allocations with every small input change.
The choice of 3 periods as smoothing window is a compromise between responsiveness and stability. Longer smoothing would excessively delay signals and impede response to true regime changes. Shorter or no smoothing would allow too much noise. Empirical tests showed that 3-period smoothing offers an optimal ratio between these goals.
10. Visualization and Interpretation
10.1 Main Output: Equity Allocation
DEAM's primary output is a time series from 0 to 100 representing the recommended percentage allocation to equities. This representation is intuitive: 100% means full investment in stocks (specifically: an S&P 500 ETF), 0% means complete cash position, and intermediate values correspond to mixed portfolios. A value of 60% means, for example: invest 60% of wealth in SPY, hold 40% in money market instruments or cash.
The time series is color-coded to enable quick visual interpretation. Green shades represent high allocations (above 80%, bullish), red shades low allocations (below 20%, bearish), and neutral colors middle allocations. The chart background is dynamically colored based on the signal, enhancing readability in different market phases.
10.2 Dashboard Metrics
A tabular dashboard presents key metrics compactly. This includes current allocation, cash allocation (complement), an aggregated signal (BULLISH/NEUTRAL/BEARISH), current market regime, VIX level, market drawdown, and crisis status.
Additionally, fundamental metrics are displayed: P/E Ratio, Equity Risk Premium, Return on Equity, Debt-to-Equity Ratio, and Total Shareholder Yield. This transparency allows users to understand model decisions and form their own assessments.
Component scores (Regime, Risk, Valuation, Sentiment, Macro) are also displayed, each normalized on a 0-100 scale. This shows which factors primarily drive the current recommendation. If, for example, the Risk score is very low (20) while other scores are moderate (50-60), this indicates that risk management considerations are pulling allocation down.
10.3 Component Breakdown (Optional)
Advanced users can display individual components as separate lines in the chart. This enables analysis of component dynamics: do all components move synchronously, or are there divergences? Divergences can be particularly informative. If, for example, the market regime is bullish (high score) but the valuation component is very negative, this signals an overbought market not fundamentally supported—a classic "bubble warning."
This feature is disabled by default to keep the chart clean but can be activated for deeper analysis.
10.4 Confidence Bands
The model optionally displays uncertainty bands around the main allocation line. These are calculated as ±1 standard deviation of allocation over a rolling 20-period window. Wide bands indicate high volatility of model recommendations, suggesting uncertain market conditions. Narrow bands indicate stable recommendations.
This visualization implements a concept of epistemic uncertainty—uncertainty about the model estimate itself, not just market volatility. In phases where various indicators send conflicting signals, the allocation recommendation becomes more volatile, manifesting in wider bands. Users can understand this as a warning to act more cautiously or consult alternative information sources.
11. Alert System
11.1 Allocation Alerts
DEAM implements an alert system that notifies users of significant events. Allocation alerts trigger when smoothed allocation crosses certain thresholds. An alert is generated when allocation reaches 80% (from below), signaling strong bullish conditions. Another alert triggers when allocation falls to 20%, indicating defensive positioning.
These thresholds are not arbitrary but correspond with boundaries between model regimes. An allocation of 80% roughly corresponds to a clear bull market regime, while 20% corresponds to a bear market regime. Alerts at these points are therefore informative about fundamental regime shifts.
11.2 Crisis Alerts
Separate alerts trigger upon detection of crisis and severe crisis. These alerts have highest priority as they signal large risks. A crisis alert should prompt investors to review their portfolio and potentially take defensive measures beyond the automatic model recommendation (e.g., hedging through put options, rebalancing to more defensive sectors).
11.3 Regime Change Alerts
An alert triggers upon change of market regime (e.g., from Neutral to Correction, or from Bull Market to Strong Bull). Regime changes are highly informative events that typically entail substantial allocation changes. These alerts enable investors to proactively respond to changes in market dynamics.
11.4 Risk Breach Alerts
A specialized alert triggers when actual portfolio risk utilization exceeds target parameters by 20%. This is a warning signal that the risk management system is reaching its limits, possibly because market volatility is rising faster than allocation can be reduced. In such situations, investors should consider manual interventions.
12. Practical Application and Limitations
12.1 Portfolio Implementation
DEAM generates a recommendation for allocation between equities (S&P 500) and cash. Implementation by an investor can take various forms. The most direct method is using an S&P 500 ETF (e.g., SPY, VOO) for equity allocation and a money market fund or savings account for cash allocation.
A rebalancing strategy is required to synchronize actual allocation with model recommendation. Two approaches are possible: (1) rule-based rebalancing at every 10% deviation between actual and target, or (2) time-based monthly rebalancing. Both have trade-offs between responsiveness and transaction costs. Empirical evidence (Jaconetti, Kinniry, and Zilbering, 2010) suggests rebalancing frequency has moderate impact on performance, and investors should optimize based on their transaction costs.
12.2 Adaptation to Individual Preferences
The model offers numerous adjustment parameters. Component weights can be modified if investors place more or less belief in certain factors. A fundamentally-oriented investor might increase valuation weight, while a technical trader might increase regime weight.
Risk target parameters (target volatility, max drawdown) should be adapted to individual risk tolerance. Younger investors with long investment horizons can choose higher target volatility (15-18%), while retirees may prefer lower volatility (8-10%). This adjustment systematically shifts average equity allocation.
Crisis thresholds can be adjusted based on preference for sensitivity versus specificity of crisis detection. Lower thresholds (e.g., VIX > 35 instead of 40) increase sensitivity (more crises are detected) but reduce specificity (more false alarms). Higher thresholds have the reverse effect.
12.3 Limitations and Disclaimers
DEAM is based on historical relationships between indicators and market performance. There is no guarantee these relationships will persist in the future. Structural changes in markets (e.g., through regulation, technology, or central bank policy) can break established patterns. This is the fundamental problem of induction in financial science (Taleb, 2007).
The model is optimized for US equities (S&P 500). Application to other markets (international stocks, bonds, commodities) would require recalibration. The indicators and thresholds are specific to the statistical properties of the US equity market.
The model cannot eliminate losses. Even with perfect crisis prediction, an investor following the model would lose money in bear markets—just less than a buy-and-hold investor. The goal is risk-adjusted performance improvement, not risk elimination.
Transaction costs are not modeled. In practice, spreads, commissions, and taxes reduce net returns. Frequent trading can cause substantial costs. Model smoothing helps minimize this, but users should consider their specific cost situation.
The model reacts to information; it does not anticipate it. During sudden shocks (e.g., 9/11, COVID-19 lockdowns), the model can only react after price movements, not before. This limitation is inherent to all reactive systems.
12.4 Relationship to Other Strategies
DEAM is a tactical asset allocation approach and should be viewed as a complement, not replacement, for strategic asset allocation. Brinson, Hood, and Beebower (1986) showed in their influential study "Determinants of Portfolio Performance" that strategic asset allocation (long-term policy allocation) explains the majority of portfolio performance, but this leaves room for tactical adjustments based on market timing.
The model can be combined with value and momentum strategies at the individual stock level. While DEAM controls overall market exposure, within-equity decisions can be optimized through stock-picking models. This separation between strategic (market exposure) and tactical (stock selection) levels follows classical portfolio theory.
The model does not replace diversification across asset classes. A complete portfolio should also include bonds, international stocks, real estate, and alternative investments. DEAM addresses only the US equity allocation decision within a broader portfolio.
13. Scientific Foundation and Evaluation
13.1 Theoretical Consistency
DEAM's components are based on established financial theory and empirical evidence. The market regime component follows from regime-switching models (Hamilton, 1989) and trend-following literature. The risk management component implements volatility targeting (Moreira and Muir, 2017) and modern portfolio theory (Markowitz, 1952). The valuation component is based on discounted cash flow theory and empirical value research (Campbell and Shiller, 1988; Fama and French, 1992). The sentiment component integrates behavioral finance (Baker and Wurgler, 2006). The macro component uses established business cycle indicators (Estrella and Mishkin, 1998).
This theoretical grounding distinguishes DEAM from purely data-mining-based approaches that identify patterns without causal theory. Theory-guided models have greater probability of functioning out-of-sample, as they are based on fundamental mechanisms, not random correlations (Lo and MacKinlay, 1990).
13.2 Empirical Validation
While this document does not present detailed backtest analysis, it should be noted that rigorous validation of a tactical asset allocation model should include several elements:
In-sample testing establishes whether the model functions at all in the data on which it was calibrated. Out-of-sample testing is crucial: the model should be tested in time periods not used for development. Walk-forward analysis, where the model is successively trained on rolling windows and tested in the next window, approximates real implementation.
Performance metrics should be risk-adjusted. Pure return consideration is misleading, as higher returns often only compensate for higher risk. Sharpe Ratio, Sortino Ratio, Calmar Ratio, and Maximum Drawdown are relevant metrics. Comparison with benchmarks (Buy-and-Hold S&P 500, 60/40 Stock/Bond portfolio) contextualizes performance.
Robustness checks test sensitivity to parameter variation. If the model only functions at specific parameter settings, this indicates overfitting. Robust models show consistent performance over a range of plausible parameters.
13.3 Comparison with Existing Literature
DEAM fits into the broader literature on tactical asset allocation. Faber (2007) presented a simple momentum-based timing system that goes long when the market is above its 10-month average, otherwise cash. This simple system avoided large drawdowns in bear markets. DEAM can be understood as a sophistication of this approach that integrates multiple information sources.
Ilmanen (2011) discusses various timing factors in "Expected Returns" and argues for multi-factor approaches. DEAM operationalizes this philosophy. Asness, Moskowitz, and Pedersen (2013) showed that value and momentum effects work across asset classes, justifying cross-asset application of regime and valuation signals.
Ang (2014) emphasizes in "Asset Management: A Systematic Approach to Factor Investing" the importance of systematic, rule-based approaches over discretionary decisions. DEAM is fully systematic and eliminates emotional biases that plague individual investors (overconfidence, hindsight bias, loss aversion).
References
Ang, A. (2014) *Asset Management: A Systematic Approach to Factor Investing*. Oxford: Oxford University Press.
Ang, A., Piazzesi, M. and Wei, M. (2006) 'What does the yield curve tell us about GDP growth?', *Journal of Econometrics*, 131(1-2), pp. 359-403.
Asness, C.S. (2003) 'Fight the Fed Model', *The Journal of Portfolio Management*, 30(1), pp. 11-24.
Asness, C.S., Moskowitz, T.J. and Pedersen, L.H. (2013) 'Value and Momentum Everywhere', *The Journal of Finance*, 68(3), pp. 929-985.
Baker, M. and Wurgler, J. (2006) 'Investor Sentiment and the Cross-Section of Stock Returns', *The Journal of Finance*, 61(4), pp. 1645-1680.
Baker, M. and Wurgler, J. (2007) 'Investor Sentiment in the Stock Market', *Journal of Economic Perspectives*, 21(2), pp. 129-152.
Baur, D.G. and Lucey, B.M. (2010) 'Is Gold a Hedge or a Safe Haven? An Analysis of Stocks, Bonds and Gold', *Financial Review*, 45(2), pp. 217-229.
Bollerslev, T. (1986) 'Generalized Autoregressive Conditional Heteroskedasticity', *Journal of Econometrics*, 31(3), pp. 307-327.
Boudoukh, J., Michaely, R., Richardson, M. and Roberts, M.R. (2007) 'On the Importance of Measuring Payout Yield: Implications for Empirical Asset Pricing', *The Journal of Finance*, 62(2), pp. 877-915.
Brinson, G.P., Hood, L.R. and Beebower, G.L. (1986) 'Determinants of Portfolio Performance', *Financial Analysts Journal*, 42(4), pp. 39-44.
Brock, W., Lakonishok, J. and LeBaron, B. (1992) 'Simple Technical Trading Rules and the Stochastic Properties of Stock Returns', *The Journal of Finance*, 47(5), pp. 1731-1764.
Calmar, T.W. (1991) 'The Calmar Ratio', *Futures*, October issue.
Campbell, J.Y. and Shiller, R.J. (1988) 'The Dividend-Price Ratio and Expectations of Future Dividends and Discount Factors', *Review of Financial Studies*, 1(3), pp. 195-228.
Cochrane, J.H. (2011) 'Presidential Address: Discount Rates', *The Journal of Finance*, 66(4), pp. 1047-1108.
Damodaran, A. (2012) *Equity Risk Premiums: Determinants, Estimation and Implications*. Working Paper, Stern School of Business.
Engle, R.F. (1982) 'Autoregressive Conditional Heteroskedasticity with Estimates of the Variance of United Kingdom Inflation', *Econometrica*, 50(4), pp. 987-1007.
Estrella, A. and Hardouvelis, G.A. (1991) 'The Term Structure as a Predictor of Real Economic Activity', *The Journal of Finance*, 46(2), pp. 555-576.
Estrella, A. and Mishkin, F.S. (1998) 'Predicting U.S. Recessions: Financial Variables as Leading Indicators', *Review of Economics and Statistics*, 80(1), pp. 45-61.
Faber, M.T. (2007) 'A Quantitative Approach to Tactical Asset Allocation', *The Journal of Wealth Management*, 9(4), pp. 69-79.
Fama, E.F. and French, K.R. (1989) 'Business Conditions and Expected Returns on Stocks and Bonds', *Journal of Financial Economics*, 25(1), pp. 23-49.
Fama, E.F. and French, K.R. (1992) 'The Cross-Section of Expected Stock Returns', *The Journal of Finance*, 47(2), pp. 427-465.
Garman, M.B. and Klass, M.J. (1980) 'On the Estimation of Security Price Volatilities from Historical Data', *Journal of Business*, 53(1), pp. 67-78.
Gilchrist, S. and Zakrajšek, E. (2012) 'Credit Spreads and Business Cycle Fluctuations', *American Economic Review*, 102(4), pp. 1692-1720.
Gordon, M.J. (1962) *The Investment, Financing, and Valuation of the Corporation*. Homewood: Irwin.
Graham, B. and Dodd, D.L. (1934) *Security Analysis*. New York: McGraw-Hill.
Hamilton, J.D. (1989) 'A New Approach to the Economic Analysis of Nonstationary Time Series and the Business Cycle', *Econometrica*, 57(2), pp. 357-384.
Ilmanen, A. (2011) *Expected Returns: An Investor's Guide to Harvesting Market Rewards*. Chichester: Wiley.
Jaconetti, C.M., Kinniry, F.M. and Zilbering, Y. (2010) 'Best Practices for Portfolio Rebalancing', *Vanguard Research Paper*.
Jegadeesh, N. and Titman, S. (1993) 'Returns to Buying Winners and Selling Losers: Implications for Stock Market Efficiency', *The Journal of Finance*, 48(1), pp. 65-91.
Kahneman, D. and Tversky, A. (1979) 'Prospect Theory: An Analysis of Decision under Risk', *Econometrica*, 47(2), pp. 263-292.
Korteweg, A. (2010) 'The Net Benefits to Leverage', *The Journal of Finance*, 65(6), pp. 2137-2170.
Lo, A.W. and MacKinlay, A.C. (1990) 'Data-Snooping Biases in Tests of Financial Asset Pricing Models', *Review of Financial Studies*, 3(3), pp. 431-467.
Longin, F. and Solnik, B. (2001) 'Extreme Correlation of International Equity Markets', *The Journal of Finance*, 56(2), pp. 649-676.
Mandelbrot, B. (1963) 'The Variation of Certain Speculative Prices', *The Journal of Business*, 36(4), pp. 394-419.
Markowitz, H. (1952) 'Portfolio Selection', *The Journal of Finance*, 7(1), pp. 77-91.
Modigliani, F. and Miller, M.H. (1961) 'Dividend Policy, Growth, and the Valuation of Shares', *The Journal of Business*, 34(4), pp. 411-433.
Moreira, A. and Muir, T. (2017) 'Volatility-Managed Portfolios', *The Journal of Finance*, 72(4), pp. 1611-1644.
Moskowitz, T.J., Ooi, Y.H. and Pedersen, L.H. (2012) 'Time Series Momentum', *Journal of Financial Economics*, 104(2), pp. 228-250.
Parkinson, M. (1980) 'The Extreme Value Method for Estimating the Variance of the Rate of Return', *Journal of Business*, 53(1), pp. 61-65.
Piotroski, J.D. (2000) 'Value Investing: The Use of Historical Financial Statement Information to Separate Winners from Losers', *Journal of Accounting Research*, 38, pp. 1-41.
Reinhart, C.M. and Rogoff, K.S. (2009) *This Time Is Different: Eight Centuries of Financial Folly*. Princeton: Princeton University Press.
Ross, S.A. (1976) 'The Arbitrage Theory of Capital Asset Pricing', *Journal of Economic Theory*, 13(3), pp. 341-360.
Roy, A.D. (1952) 'Safety First and the Holding of Assets', *Econometrica*, 20(3), pp. 431-449.
Schwert, G.W. (1989) 'Why Does Stock Market Volatility Change Over Time?', *The Journal of Finance*, 44(5), pp. 1115-1153.
Sharpe, W.F. (1966) 'Mutual Fund Performance', *The Journal of Business*, 39(1), pp. 119-138.
Sharpe, W.F. (1994) 'The Sharpe Ratio', *The Journal of Portfolio Management*, 21(1), pp. 49-58.
Simon, D.P. and Wiggins, R.A. (2001) 'S&P Futures Returns and Contrary Sentiment Indicators', *Journal of Futures Markets*, 21(5), pp. 447-462.
Taleb, N.N. (2007) *The Black Swan: The Impact of the Highly Improbable*. New York: Random House.
Whaley, R.E. (2000) 'The Investor Fear Gauge', *The Journal of Portfolio Management*, 26(3), pp. 12-17.
Whaley, R.E. (2009) 'Understanding the VIX', *The Journal of Portfolio Management*, 35(3), pp. 98-105.
Yardeni, E. (2003) 'Stock Valuation Models', *Topical Study*, 51, Yardeni Research.
Zweig, M.E. (1973) 'An Investor Expectations Stock Price Predictive Model Using Closed-End Fund Premiums', *The Journal of Finance*, 28(1), pp. 67-78.
Adaptive Heikin Ashi [CHE]Adaptive Heikin Ashi — volatility-aware HA with fewer fake flips
Summary
Adaptive Heikin Ashi is a volatility-aware reinterpretation of classic Heikin Ashi that continuously adjusts its internal smoothing based on the current ATR regime, which means that in quiet markets the indicator reacts more quickly to genuine directional changes, while in turbulent phases it deliberately increases its smoothing to suppress jitter and color whipsaws, thereby reducing “noise” and cutting down on fake flips without resorting to heavy fixed smoothing that would lag everywhere.
Motivation: why adapt at all?
Classic Heikin Ashi replaces raw OHLC candles with a smoothed construction that averages price and blends each new candle with the previous HA state, which typically cleans up trends and improves visual coherence, yet its fixed smoothing amount treats calm and violent markets the same, leading to the usual dilemma where a setting that looks crisp in a narrow range becomes too nervous in a spike, and a setting that tames high volatility feels unnecessarily sluggish as soon as conditions normalize; by allowing the smoothing weight to expand and contract with volatility, Adaptive HA aims to keep candles readable across shifting regimes without constant manual retuning.
What is different from normal Heikin Ashi?
Fixed vs. adaptive blend:
Classic HA implicitly uses a fixed 50/50 blend for the open update (`HA_open_t = 0.5 HA_open_{t-1} + 0.5 HA_close_{t-1}`), while this script replaces the constant 0.5 with a dynamic weight `w_t` that oscillates around 0.5 as a function of observed volatility, which turns the open update into an EMA-like filter whose “alpha” automatically changes with market conditions.
Volatility as the steering signal:
The script measures volatility via ATR and compares it to a rolling baseline (SMA of ATR over the same length), producing a normalized deviation that is scaled by sensitivity, clamped to ±1 for stability, and then mapped to a bounded weight interval ` `, so the adaptation is strong enough to matter but never runs away.
Outcome that matters to traders:
In high volatility, the weight shifts upward toward the prior HA open, which strengthens smoothing exactly where classic HA tends to “chatter,” while in low volatility the weight shifts downward toward the most recent HA close, which speeds up reaction so quiet trends do not feel artificially delayed; this is the practical mechanism by which noise and fake signals are reduced without accepting blanket lag.
How it works
1. HA close matches classic HA:
`HA_close_t = (Open_t + High_t + Low_t + Close_t) / 4`
2. Volatility normalization:
`ATR_t` is computed over `atr_length`, its baseline is `ATR_SMA_t = SMA(ATR, atr_length)`, and the raw deviation is `(ATR_t / ATR_SMA_t − 1)`, which is then scaled by `adapt_sensitivity` and clamped to ` ` to obtain `v_t`, ensuring that pathological spikes cannot destabilize the weighting.
3. Adaptive weight around 0.5:
`w_t = 0.5 + oscillation_range v_t`, giving `w_t ∈ `, so with a default `range = 0.20` the weight stays between 0.30 and 0.70, which is wide enough to matter but narrow enough to preserve HA identity.
4. EMA-like open update:
On the very first bar the open is seeded from a stable combination of the raw open and close, and thereafter the update is
`HA_open_t = w_t HA_open_{t−1} + (1 − w_t) HA_close_{t−1}`,
which is equivalent to an EMA where higher `w_t` means heavier inertia (more smoothing) and lower `w_t` means stronger pull to the latest price information (more responsiveness).
5. High and low follow classic HA composition:
`HA_high_t = max(High_t, max(HA_open_t, HA_close_t))`,
`HA_low_t = min(Low_t, min(HA_open_t, HA_close_t))`,
thereby keeping visual semantics consistent with standard HA so that your existing reading of bodies, wicks, and transitions still applies.
Why this reduces noise and fake signals in practice
Fake flips in HA typically occur when a fixed blending rule is forced to process candles during a volatility surge, producing rapid alternations around pivots or within wide intrabar ranges; by increasing smoothing exactly when ATR jumps relative to its baseline, the adaptive open stabilizes the candle body progression and suppresses transient color changes, while in the opposite scenario of compressed ranges, the reduced smoothing allows small but persistent directional pressure to reflect in candle color earlier, which reduces the tendency to enter late after multiple slow transitions.
Parameter guide (what each input really does)
ATR Length (default 14): controls both the ATR and its baseline window, where longer values dampen the adaptation by making the baseline slower and the deviation smaller, which is helpful for noisy lower timeframes, while shorter values make the regime detector more reactive.
Oscillation Range (default 0.20): sets the maximum distance from 0.5 that the weight may travel, so increasing it towards 0.25–0.30 yields stronger smoothing in turbulence and faster response in calm periods, whereas decreasing it to 0.10–0.15 keeps the behavior closer to classical HA and is useful if your strategy already includes heavy downstream smoothing.
Adapt Sensitivity (default 6.0): multiplies the normalized ATR deviation before clamping, such that higher sensitivity accelerates adaptation to regime shifts, while lower sensitivity produces gradual transitions; negative values intentionally invert the mapping (higher vol → less smoothing) and are generally not recommended unless you are testing a counter-intuitive hypothesis.
Reading the candles and the optional diagnostic
You interpret colors and bodies just like with normal HA, but you can additionally enable the Adaptive Weight diagnostic plot to see the regime in real time, where values drifting up toward the upper bound indicate a turbulent context that is being deliberately smoothed, and values gliding down toward the lower bound indicate a calm environment in which the indicator chooses to move faster, which can be valuable for discretionary confirmation when deciding whether a fresh color shift is likely to stick.
Practical workflows and combinations
Trend-following entries: use color continuity and body expansion as usual, but expect fewer spurious alternations around news spikes or into liquidity gaps; pairing with structure (swing highs/lows, breaks of internal ranges) keeps entries disciplined.
Exit management: when the diagnostic weight remains elevated for an extended period, you can be stricter with exit triggers because flips are less likely to be accidental noise; conversely, when the weight is depressed, consider earlier partials since the indicator is intentionally more nimble.
Multi-asset, multi-TF: the adaptation is especially helpful if you rotate instruments with very different vol profiles or hop across timeframes, since you will not need to retune a fixed smoothing parameter every time conditions change.
Behavior, constraints, and performance
The script does not repaint historical bars and uses only past information on closed candles, yet just like any candle-based visualization the current live bar will update until it closes, so you should avoid acting on mid-bar flips without a rule that accounts for bar close; there are no `security()` calls or higher-timeframe lookups, which keeps performance light and execution deterministic, and the clamping of the volatility signal ensures numerical stability even during extreme ATR spikes.
Sensible defaults and quick tuning
Start with the defaults (`ATR 14`, `Range 0.20`, `Sensitivity 6.0`) and observe the weight plot across a few volatile events; if you still see too many flips in turbulence, either raise `Range` to 0.25 or trim `Sensitivity` to 4–5 so that the weight can move high but does not overreact, and if the indicator feels too slow in quiet markets, lower `Range` toward 0.15 or raise `Sensitivity` to 7–8 to bias the weight a bit more aggressively downward when conditions compress.
What this indicator is—and is not
Adaptive Heikin Ashi is a context-aware visualization layer that improves the signal-to-noise ratio and reduces fake flips by modulating smoothing with volatility, but it is not a complete trading system, it does not predict the future, and it should be combined with structure, risk controls, and position management that fit your market and timeframe; always forward-test on your instruments, and remember that even adaptive smoothing can delay recognition at sharp turning points when volatility remains elevated.
Disclaimer
The content provided, including all code and materials, is strictly for educational and informational purposes only. It is not intended as, and should not be interpreted as, financial advice, a recommendation to buy or sell any financial instrument, or an offer of any financial product or service. All strategies, tools, and examples discussed are provided for illustrative purposes to demonstrate coding techniques and the functionality of Pine Script within a trading context.
Any results from strategies or tools provided are hypothetical, and past performance is not indicative of future results. Trading and investing involve high risk, including the potential loss of principal, and may not be suitable for all individuals. Before making any trading decisions, please consult with a qualified financial professional to understand the risks involved.
By using this script, you acknowledge and agree that any trading decisions are made solely at your discretion and risk.
Best regards and happy trading
Chervolino

ATAI Volume analysis with price action V 1.00ATAI Volume Analysis with Price Action
1. Introduction
1.1 Overview
ATAI Volume Analysis with Price Action is a composite indicator designed for TradingView. It combines per‑side volume data —that is, how much buying and selling occurs during each bar—with standard price‑structure elements such as swings, trend lines and support/resistance. By blending these elements the script aims to help a trader understand which side is in control, whether a breakout is genuine, when markets are potentially exhausted and where liquidity providers might be active.
The indicator is built around TradingView’s up/down volume feed accessed via the TradingView/ta/10 library. The following excerpt from the script illustrates how this feed is configured:
import TradingView/ta/10 as tvta
// Determine lower timeframe string based on user choice and chart resolution
string lower_tf_breakout = use_custom_tf_input ? custom_tf_input :
timeframe.isseconds ? "1S" :
timeframe.isintraday ? "1" :
timeframe.isdaily ? "5" : "60"
// Request up/down volume (both positive)
= tvta.requestUpAndDownVolume(lower_tf_breakout)
Lower‑timeframe selection. If you do not specify a custom lower timeframe, the script chooses a default based on your chart resolution: 1 second for second charts, 1 minute for intraday charts, 5 minutes for daily charts and 60 minutes for anything longer. Smaller intervals provide a more precise view of buyer and seller flow but cover fewer bars. Larger intervals cover more history at the cost of granularity.
Tick vs. time bars. Many trading platforms offer a tick / intrabar calculation mode that updates an indicator on every trade rather than only on bar close. Turning on one‑tick calculation will give the most accurate split between buy and sell volume on the current bar, but it typically reduces the amount of historical data available. For the highest fidelity in live trading you can enable this mode; for studying longer histories you might prefer to disable it. When volume data is completely unavailable (some instruments and crypto pairs), all modules that rely on it will remain silent and only the price‑structure backbone will operate.
Figure caption, Each panel shows the indicator’s info table for a different volume sampling interval. In the left chart, the parentheses “(5)” beside the buy‑volume figure denote that the script is aggregating volume over five‑minute bars; the center chart uses “(1)” for one‑minute bars; and the right chart uses “(1T)” for a one‑tick interval. These notations tell you which lower timeframe is driving the volume calculations. Shorter intervals such as 1 minute or 1 tick provide finer detail on buyer and seller flow, but they cover fewer bars; longer intervals like five‑minute bars smooth the data and give more history.
Figure caption, The values in parentheses inside the info table come directly from the Breakout — Settings. The first row shows the custom lower-timeframe used for volume calculations (e.g., “(1)”, “(5)”, or “(1T)”)
2. Price‑Structure Backbone
Even without volume, the indicator draws structural features that underpin all other modules. These features are always on and serve as the reference levels for subsequent calculations.
2.1 What it draws
• Pivots: Swing highs and lows are detected using the pivot_left_input and pivot_right_input settings. A pivot high is identified when the high recorded pivot_right_input bars ago exceeds the highs of the preceding pivot_left_input bars and is also higher than (or equal to) the highs of the subsequent pivot_right_input bars; pivot lows follow the inverse logic. The indicator retains only a fixed number of such pivot points per side, as defined by point_count_input, discarding the oldest ones when the limit is exceeded.
• Trend lines: For each side, the indicator connects the earliest stored pivot and the most recent pivot (oldest high to newest high, and oldest low to newest low). When a new pivot is added or an old one drops out of the lookback window, the line’s endpoints—and therefore its slope—are recalculated accordingly.
• Horizontal support/resistance: The highest high and lowest low within the lookback window defined by length_input are plotted as horizontal dashed lines. These serve as short‑term support and resistance levels.
• Ranked labels: If showPivotLabels is enabled the indicator prints labels such as “HH1”, “HH2”, “LL1” and “LL2” near each pivot. The ranking is determined by comparing the price of each stored pivot: HH1 is the highest high, HH2 is the second highest, and so on; LL1 is the lowest low, LL2 is the second lowest. In the case of equal prices the newer pivot gets the better rank. Labels are offset from price using ½ × ATR × label_atr_multiplier, with the ATR length defined by label_atr_len_input. A dotted connector links each label to the candle’s wick.
2.2 Key settings
• length_input: Window length for finding the highest and lowest values and for determining trend line endpoints. A larger value considers more history and will generate longer trend lines and S/R levels.
• pivot_left_input, pivot_right_input: Strictness of swing confirmation. Higher values require more bars on either side to form a pivot; lower values create more pivots but may include minor swings.
• point_count_input: How many pivots are kept in memory on each side. When new pivots exceed this number the oldest ones are discarded.
• label_atr_len_input and label_atr_multiplier: Determine how far pivot labels are offset from the bar using ATR. Increasing the multiplier moves labels further away from price.
• Styling inputs for trend lines, horizontal lines and labels (color, width and line style).
Figure caption, The chart illustrates how the indicator’s price‑structure backbone operates. In this daily example, the script scans for bars where the high (or low) pivot_right_input bars back is higher (or lower) than the preceding pivot_left_input bars and higher or lower than the subsequent pivot_right_input bars; only those bars are marked as pivots.
These pivot points are stored and ranked: the highest high is labelled “HH1”, the second‑highest “HH2”, and so on, while lows are marked “LL1”, “LL2”, etc. Each label is offset from the price by half of an ATR‑based distance to keep the chart clear, and a dotted connector links the label to the actual candle.
The red diagonal line connects the earliest and latest stored high pivots, and the green line does the same for low pivots; when a new pivot is added or an old one drops out of the lookback window, the end‑points and slopes adjust accordingly. Dashed horizontal lines mark the highest high and lowest low within the current lookback window, providing visual support and resistance levels. Together, these elements form the structural backbone that other modules reference, even when volume data is unavailable.
3. Breakout Module
3.1 Concept
This module confirms that a price break beyond a recent high or low is supported by a genuine shift in buying or selling pressure. It requires price to clear the highest high (“HH1”) or lowest low (“LL1”) and, simultaneously, that the winning side shows a significant volume spike, dominance and ranking. Only when all volume and price conditions pass is a breakout labelled.
3.2 Inputs
• lookback_break_input : This controls the number of bars used to compute moving averages and percentiles for volume. A larger value smooths the averages and percentiles but makes the indicator respond more slowly.
• vol_mult_input : The “spike” multiplier; the current buy or sell volume must be at least this multiple of its moving average over the lookback window to qualify as a breakout.
• rank_threshold_input (0–100) : Defines a volume percentile cutoff: the current buyer/seller volume must be in the top (100−threshold)%(100−threshold)% of all volumes within the lookback window. For example, if set to 80, the current volume must be in the top 20 % of the lookback distribution.
• ratio_threshold_input (0–1) : Specifies the minimum share of total volume that the buyer (for a bullish breakout) or seller (for bearish) must hold on the current bar; the code also requires that the cumulative buyer volume over the lookback window exceeds the seller volume (and vice versa for bearish cases).
• use_custom_tf_input / custom_tf_input : When enabled, these inputs override the automatic choice of lower timeframe for up/down volume; otherwise the script selects a sensible default based on the chart’s timeframe.
• Label appearance settings : Separate options control the ATR-based offset length, offset multiplier, label size and colors for bullish and bearish breakout labels, as well as the connector style and width.
3.3 Detection logic
1. Data preparation : Retrieve per‑side volume from the lower timeframe and take absolute values. Build rolling arrays of the last lookback_break_input values to compute simple moving averages (SMAs), cumulative sums and percentile ranks for buy and sell volume.
2. Volume spike: A spike is flagged when the current buy (or, in the bearish case, sell) volume is at least vol_mult_input times its SMA over the lookback window.
3. Dominance test: The buyer’s (or seller’s) share of total volume on the current bar must meet or exceed ratio_threshold_input. In addition, the cumulative sum of buyer volume over the window must exceed the cumulative sum of seller volume for a bullish breakout (and vice versa for bearish). A separate requirement checks the sign of delta: for bullish breakouts delta_breakout must be non‑negative; for bearish breakouts it must be non‑positive.
4. Percentile rank: The current volume must fall within the top (100 – rank_threshold_input) percent of the lookback distribution—ensuring that the spike is unusually large relative to recent history.
5. Price test: For a bullish signal, the closing price must close above the highest pivot (HH1); for a bearish signal, the close must be below the lowest pivot (LL1).
6. Labeling: When all conditions above are satisfied, the indicator prints “Breakout ↑” above the bar (bullish) or “Breakout ↓” below the bar (bearish). Labels are offset using half of an ATR‑based distance and linked to the candle with a dotted connector.
Figure caption, (Breakout ↑ example) , On this daily chart, price pushes above the red trendline and the highest prior pivot (HH1). The indicator recognizes this as a valid breakout because the buyer‑side volume on the lower timeframe spikes above its recent moving average and buyers dominate the volume statistics over the lookback period; when combined with a close above HH1, this satisfies the breakout conditions. The “Breakout ↑” label appears above the candle, and the info table highlights that up‑volume is elevated relative to its 11‑bar average, buyer share exceeds the dominance threshold and money‑flow metrics support the move.
Figure caption, In this daily example, price breaks below the lowest pivot (LL1) and the lower green trendline. The indicator identifies this as a bearish breakout because sell‑side volume is sharply elevated—about twice its 11‑bar average—and sellers dominate both the bar and the lookback window. With the close falling below LL1, the script triggers a Breakout ↓ label and marks the corresponding row in the info table, which shows strong down volume, negative delta and a seller share comfortably above the dominance threshold.
4. Market Phase Module (Volume Only)
4.1 Concept
Not all markets trend; many cycle between periods of accumulation (buying pressure building up), distribution (selling pressure dominating) and neutral behavior. This module classifies the current bar into one of these phases without using ATR , relying solely on buyer and seller volume statistics. It looks at net flows, ratio changes and an OBV‑like cumulative line with dual‑reference (1‑ and 2‑bar) trends. The result is displayed both as on‑chart labels and in a dedicated row of the info table.
4.2 Inputs
• phase_period_len: Number of bars over which to compute sums and ratios for phase detection.
• phase_ratio_thresh : Minimum buyer share (for accumulation) or minimum seller share (for distribution, derived as 1 − phase_ratio_thresh) of the total volume.
• strict_mode: When enabled, both the 1‑bar and 2‑bar changes in each statistic must agree on the direction (strict confirmation); when disabled, only one of the two references needs to agree (looser confirmation).
• Color customisation for info table cells and label styling for accumulation and distribution phases, including ATR length, multiplier, label size, colors and connector styles.
• show_phase_module: Toggles the entire phase detection subsystem.
• show_phase_labels: Controls whether on‑chart labels are drawn when accumulation or distribution is detected.
4.3 Detection logic
The module computes three families of statistics over the volume window defined by phase_period_len:
1. Net sum (buyers minus sellers): net_sum_phase = Σ(buy) − Σ(sell). A positive value indicates a predominance of buyers. The code also computes the differences between the current value and the values 1 and 2 bars ago (d_net_1, d_net_2) to derive up/down trends.
2. Buyer ratio: The instantaneous ratio TF_buy_breakout / TF_tot_breakout and the window ratio Σ(buy) / Σ(total). The current ratio must exceed phase_ratio_thresh for accumulation or fall below 1 − phase_ratio_thresh for distribution. The first and second differences of the window ratio (d_ratio_1, d_ratio_2) determine trend direction.
3. OBV‑like cumulative net flow: An on‑balance volume analogue obv_net_phase increments by TF_buy_breakout − TF_sell_breakout each bar. Its differences over the last 1 and 2 bars (d_obv_1, d_obv_2) provide trend clues.
The algorithm then combines these signals:
• For strict mode , accumulation requires: (a) current ratio ≥ threshold, (b) cumulative ratio ≥ threshold, (c) both ratio differences ≥ 0, (d) net sum differences ≥ 0, and (e) OBV differences ≥ 0. Distribution is the mirror case.
• For loose mode , it relaxes the directional tests: either the 1‑ or the 2‑bar difference needs to agree in each category.
If all conditions for accumulation are satisfied, the phase is labelled “Accumulation” ; if all conditions for distribution are satisfied, it’s labelled “Distribution” ; otherwise the phase is “Neutral” .
4.4 Outputs
• Info table row : Row 8 displays “Market Phase (Vol)” on the left and the detected phase (Accumulation, Distribution or Neutral) on the right. The text colour of both cells matches a user‑selectable palette (typically green for accumulation, red for distribution and grey for neutral).
• On‑chart labels : When show_phase_labels is enabled and a phase persists for at least one bar, the module prints a label above the bar ( “Accum” ) or below the bar ( “Dist” ) with a dashed or dotted connector. The label is offset using ATR based on phase_label_atr_len_input and phase_label_multiplier and is styled according to user preferences.
Figure caption, The chart displays a red “Dist” label above a particular bar, indicating that the accumulation/distribution module identified a distribution phase at that point. The detection is based on seller dominance: during that bar, the net buyer-minus-seller flow and the OBV‑style cumulative flow were trending down, and the buyer ratio had dropped below the preset threshold. These conditions satisfy the distribution criteria in strict mode. The label is placed above the bar using an ATR‑based offset and a dashed connector. By the time of the current bar in the screenshot, the phase indicator shows “Neutral” in the info table—signaling that neither accumulation nor distribution conditions are currently met—yet the historical “Dist” label remains to mark where the prior distribution phase began.
Figure caption, In this example the market phase module has signaled an Accumulation phase. Three bars before the current candle, the algorithm detected a shift toward buyers: up‑volume exceeded its moving average, down‑volume was below average, and the buyer share of total volume climbed above the threshold while the on‑balance net flow and cumulative ratios were trending upwards. The blue “Accum” label anchored below that bar marks the start of the phase; it remains on the chart because successive bars continue to satisfy the accumulation conditions. The info table confirms this: the “Market Phase (Vol)” row still reads Accumulation, and the ratio and sum rows show buyers dominating both on the current bar and across the lookback window.
5. OB/OS Spike Module
5.1 What overbought/oversold means here
In many markets, a rapid extension up or down is often followed by a period of consolidation or reversal. The indicator interprets overbought (OB) conditions as abnormally strong selling risk at or after a price rally and oversold (OS) conditions as unusually strong buying risk after a decline. Importantly, these are not direct trade signals; rather they flag areas where caution or contrarian setups may be appropriate.
5.2 Inputs
• minHits_obos (1–7): Minimum number of oscillators that must agree on an overbought or oversold condition for a label to print.
• syncWin_obos: Length of a small sliding window over which oscillator votes are smoothed by taking the maximum count observed. This helps filter out choppy signals.
• Volume spike criteria: kVolRatio_obos (ratio of current volume to its SMA) and zVolThr_obos (Z‑score threshold) across volLen_obos. Either threshold can trigger a spike.
• Oscillator toggles and periods: Each of RSI, Stochastic (K and D), Williams %R, CCI, MFI, DeMarker and Stochastic RSI can be independently enabled; their periods are adjustable.
• Label appearance: ATR‑based offset, size, colors for OB and OS labels, plus connector style and width.
5.3 Detection logic
1. Directional volume spikes: Volume spikes are computed separately for buyer and seller volumes. A sell volume spike (sellVolSpike) flags a potential OverBought bar, while a buy volume spike (buyVolSpike) flags a potential OverSold bar. A spike occurs when the respective volume exceeds kVolRatio_obos times its simple moving average over the window or when its Z‑score exceeds zVolThr_obos.
2. Oscillator votes: For each enabled oscillator, calculate its overbought and oversold state using standard thresholds (e.g., RSI ≥ 70 for OB and ≤ 30 for OS; Stochastic %K/%D ≥ 80 for OB and ≤ 20 for OS; etc.). Count how many oscillators vote for OB and how many vote for OS.
3. Minimum hits: Apply the smoothing window syncWin_obos to the vote counts using a maximum‑of‑last‑N approach. A candidate bar is only considered if the smoothed OB hit count ≥ minHits_obos (for OverBought) or the smoothed OS hit count ≥ minHits_obos (for OverSold).
4. Tie‑breaking: If both OverBought and OverSold spike conditions are present on the same bar, compare the smoothed hit counts: the side with the higher count is selected; ties default to OverBought.
5. Label printing: When conditions are met, the bar is labelled as “OverBought X/7” above the candle or “OverSold X/7” below it. “X” is the number of oscillators confirming, and the bracket lists the abbreviations of contributing oscillators. Labels are offset from price using half of an ATR‑scaled distance and can optionally include a dotted or dashed connector line.
Figure caption, In this chart the overbought/oversold module has flagged an OverSold signal. A sell‑off from the prior highs brought price down to the lower trend‑line, where the bar marked “OverSold 3/7 DeM” appears. This label indicates that on that bar the module detected a buy‑side volume spike and that at least three of the seven enabled oscillators—in this case including the DeMarker—were in oversold territory. The label is printed below the candle with a dotted connector, signaling that the market may be temporarily exhausted on the downside. After this oversold print, price begins to rebound towards the upper red trend‑line and higher pivot levels.
Figure caption, This example shows the overbought/oversold module in action. In the left‑hand panel you can see the OB/OS settings where each oscillator (RSI, Stochastic, Williams %R, CCI, MFI, DeMarker and Stochastic RSI) can be enabled or disabled, and the ATR length and label offset multiplier adjusted. On the chart itself, price has pushed up to the descending red trendline and triggered an “OverBought 3/7” label. That means the sell‑side volume spiked relative to its average and three out of the seven enabled oscillators were in overbought territory. The label is offset above the candle by half of an ATR and connected with a dashed line, signaling that upside momentum may be overextended and a pause or pullback could follow.
6. Buyer/Seller Trap Module
6.1 Concept
A bull trap occurs when price appears to break above resistance, attracting buyers, but fails to sustain the move and quickly reverses, leaving a long upper wick and trapping late entrants. A bear trap is the opposite: price breaks below support, lures in sellers, then snaps back, leaving a long lower wick and trapping shorts. This module detects such traps by looking for price structure sweeps, order‑flow mismatches and dominance reversals. It uses a scoring system to differentiate risk from confirmed traps.
6.2 Inputs
• trap_lookback_len: Window length used to rank extremes and detect sweeps.
• trap_wick_threshold: Minimum proportion of a bar’s range that must be wick (upper for bull traps, lower for bear traps) to qualify as a sweep.
• trap_score_risk: Minimum aggregated score required to flag a trap risk. (The code defines a trap_score_confirm input, but confirmation is actually based on price reversal rather than a separate score threshold.)
• trap_confirm_bars: Maximum number of bars allowed for price to reverse and confirm the trap. If price does not reverse in this window, the risk label will expire or remain unconfirmed.
• Label settings: ATR length and multiplier for offsetting, size, colours for risk and confirmed labels, and connector style and width. Separate settings exist for bull and bear traps.
• Toggle inputs: show_trap_module and show_trap_labels enable the module and control whether labels are drawn on the chart.
6.3 Scoring logic
The module assigns points to several conditions and sums them to determine whether a trap risk is present. For bull traps, the score is built from the following (bear traps mirror the logic with highs and lows swapped):
1. Sweep (2 points): Price trades above the high pivot (HH1) but fails to close above it and leaves a long upper wick at least trap_wick_threshold × range. For bear traps, price dips below the low pivot (LL1), fails to close below and leaves a long lower wick.
2. Close break (1 point): Price closes beyond HH1 or LL1 without leaving a long wick.
3. Candle/delta mismatch (2 points): The candle closes bullish yet the order flow delta is negative or the seller ratio exceeds 50%, indicating hidden supply. Conversely, a bearish close with positive delta or buyer dominance suggests hidden demand.
4. Dominance inversion (2 points): The current bar’s buyer volume has the highest rank in the lookback window while cumulative sums favor sellers, or vice versa.
5. Low‑volume break (1 point): Price crosses the pivot but total volume is below its moving average.
The total score for each side is compared to trap_score_risk. If the score is high enough, a “Bull Trap Risk” or “Bear Trap Risk” label is drawn, offset from the candle by half of an ATR‑scaled distance using a dashed outline. If, within trap_confirm_bars, price reverses beyond the opposite level—drops back below the high pivot for bull traps or rises above the low pivot for bear traps—the label is upgraded to a solid “Bull Trap” or “Bear Trap” . In this version of the code, there is no separate score threshold for confirmation: the variable trap_score_confirm is unused; confirmation depends solely on a successful price reversal within the specified number of bars.
Figure caption, In this example the trap module has flagged a Bear Trap Risk. Price initially breaks below the most recent low pivot (LL1), but the bar closes back above that level and leaves a long lower wick, suggesting a failed push lower. Combined with a mismatch between the candle direction and the order flow (buyers regain control) and a reversal in volume dominance, the aggregate score exceeds the risk threshold, so a dashed “Bear Trap Risk” label prints beneath the bar. The green and red trend lines mark the current low and high pivot trajectories, while the horizontal dashed lines show the highest and lowest values in the lookback window. If, within the next few bars, price closes decisively above the support, the risk label would upgrade to a solid “Bear Trap” label.
Figure caption, In this example the trap module has identified both ends of a price range. Near the highs, price briefly pushes above the descending red trendline and the recent pivot high, but fails to close there and leaves a noticeable upper wick. That combination of a sweep above resistance and order‑flow mismatch generates a Bull Trap Risk label with a dashed outline, warning that the upside break may not hold. At the opposite extreme, price later dips below the green trendline and the labelled low pivot, then quickly snaps back and closes higher. The long lower wick and subsequent price reversal upgrade the previous bear‑trap risk into a confirmed Bear Trap (solid label), indicating that sellers were caught on a false breakdown. Horizontal dashed lines mark the highest high and lowest low of the lookback window, while the red and green diagonals connect the earliest and latest pivot highs and lows to visualize the range.
7. Sharp Move Module
7.1 Concept
Markets sometimes display absorption or climax behavior—periods when one side steadily gains the upper hand before price breaks out with a sharp move. This module evaluates several order‑flow and volume conditions to anticipate such moves. Users can choose how many conditions must be met to flag a risk and how many (plus a price break) are required for confirmation.
7.2 Inputs
• sharp Lookback: Number of bars in the window used to compute moving averages, sums, percentile ranks and reference levels.
• sharpPercentile: Minimum percentile rank for the current side’s volume; the current buy (or sell) volume must be greater than or equal to this percentile of historical volumes over the lookback window.
• sharpVolMult: Multiplier used in the volume climax check. The current side’s volume must exceed this multiple of its average to count as a climax.
• sharpRatioThr: Minimum dominance ratio (current side’s volume relative to the opposite side) used in both the instant and cumulative dominance checks.
• sharpChurnThr: Maximum ratio of a bar’s range to its ATR for absorption/churn detection; lower values indicate more absorption (large volume in a small range).
• sharpScoreRisk: Minimum number of conditions that must be true to print a risk label.
• sharpScoreConfirm: Minimum number of conditions plus a price break required for confirmation.
• sharpCvdThr: Threshold for cumulative delta divergence versus price change (positive for bullish accumulation, negative for bearish distribution).
• Label settings: ATR length (sharpATRlen) and multiplier (sharpLabelMult) for positioning labels, label size, colors and connector styles for bullish and bearish sharp moves.
• Toggles: enableSharp activates the module; show_sharp_labels controls whether labels are drawn.
7.3 Conditions (six per side)
For each side, the indicator computes six boolean conditions and sums them to form a score:
1. Dominance (instant and cumulative):
– Instant dominance: current buy volume ≥ sharpRatioThr × current sell volume.
– Cumulative dominance: sum of buy volumes over the window ≥ sharpRatioThr × sum of sell volumes (and vice versa for bearish checks).
2. Accumulation/Distribution divergence: Over the lookback window, cumulative delta rises by at least sharpCvdThr while price fails to rise (bullish), or cumulative delta falls by at least sharpCvdThr while price fails to fall (bearish).
3. Volume climax: The current side’s volume is ≥ sharpVolMult × its average and the product of volume and bar range is the highest in the lookback window.
4. Absorption/Churn: The current side’s volume divided by the bar’s range equals the highest value in the window and the bar’s range divided by ATR ≤ sharpChurnThr (indicating large volume within a small range).
5. Percentile rank: The current side’s volume percentile rank is ≥ sharp Percentile.
6. Mirror logic for sellers: The above checks are repeated with buyer and seller roles swapped and the price break levels reversed.
Each condition that passes contributes one point to the corresponding side’s score (0 or 1). Risk and confirmation thresholds are then applied to these scores.
7.4 Scoring and labels
• Risk: If scoreBull ≥ sharpScoreRisk, a “Sharp ↑ Risk” label is drawn above the bar. If scoreBear ≥ sharpScoreRisk, a “Sharp ↓ Risk” label is drawn below the bar.
• Confirmation: A risk label is upgraded to “Sharp ↑” when scoreBull ≥ sharpScoreConfirm and the bar closes above the highest recent pivot (HH1); for bearish cases, confirmation requires scoreBear ≥ sharpScoreConfirm and a close below the lowest pivot (LL1).
• Label positioning: Labels are offset from the candle by ATR × sharpLabelMult (full ATR times multiplier), not half, and may include a dashed or dotted connector line if enabled.
Figure caption, In this chart both bullish and bearish sharp‑move setups have been flagged. Earlier in the range, a “Sharp ↓ Risk” label appears beneath a candle: the sell‑side score met the risk threshold, signaling that the combination of strong sell volume, dominance and absorption within a narrow range suggested a potential sharp decline. The price did not close below the lower pivot, so this label remains a “risk” and no confirmation occurred. Later, as the market recovered and volume shifted back to the buy side, a “Sharp ↑ Risk” label prints above a candle near the top of the channel. Here, buy‑side dominance, cumulative delta divergence and a volume climax aligned, but price has not yet closed above the upper pivot (HH1), so the alert is still a risk rather than a confirmed sharp‑up move.
Figure caption, In this chart a Sharp ↑ label is displayed above a candle, indicating that the sharp move module has confirmed a bullish breakout. Prior bars satisfied the risk threshold — showing buy‑side dominance, positive cumulative delta divergence, a volume climax and strong absorption in a narrow range — and this candle closes above the highest recent pivot, upgrading the earlier “Sharp ↑ Risk” alert to a full Sharp ↑ signal. The green label is offset from the candle with a dashed connector, while the red and green trend lines trace the high and low pivot trajectories and the dashed horizontals mark the highest and lowest values of the lookback window.
8. Market‑Maker / Spread‑Capture Module
8.1 Concept
Liquidity providers often “capture the spread” by buying and selling in almost equal amounts within a very narrow price range. These bars can signal temporary congestion before a move or reflect algorithmic activity. This module flags bars where both buyer and seller volumes are high, the price range is only a few ticks and the buy/sell split remains close to 50%. It helps traders spot potential liquidity pockets.
8.2 Inputs
• scalpLookback: Window length used to compute volume averages.
• scalpVolMult: Multiplier applied to each side’s average volume; both buy and sell volumes must exceed this multiple.
• scalpTickCount: Maximum allowed number of ticks in a bar’s range (calculated as (high − low) / minTick). A value of 1 or 2 captures ultra‑small bars; increasing it relaxes the range requirement.
• scalpDeltaRatio: Maximum deviation from a perfect 50/50 split. For example, 0.05 means the buyer share must be between 45% and 55%.
• Label settings: ATR length, multiplier, size, colors, connector style and width.
• Toggles : show_scalp_module and show_scalp_labels to enable the module and its labels.
8.3 Signal
When, on the current bar, both TF_buy_breakout and TF_sell_breakout exceed scalpVolMult times their respective averages and (high − low)/minTick ≤ scalpTickCount and the buyer share is within scalpDeltaRatio of 50%, the module prints a “Spread ↔” label above the bar. The label uses the same ATR offset logic as other modules and draws a connector if enabled.
Figure caption, In this chart the spread‑capture module has identified a potential liquidity pocket. Buyer and seller volumes both spiked above their recent averages, yet the candle’s range measured only a couple of ticks and the buy/sell split stayed close to 50 %. This combination met the module’s criteria, so it printed a grey “Spread ↔” label above the bar. The red and green trend lines link the earliest and latest high and low pivots, and the dashed horizontals mark the highest high and lowest low within the current lookback window.
9. Money Flow Module
9.1 Concept
To translate volume into a monetary measure, this module multiplies each side’s volume by the closing price. It tracks buying and selling system money default currency on a per-bar basis and sums them over a chosen period. The difference between buy and sell currencies (Δ$) shows net inflow or outflow.
9.2 Inputs
• mf_period_len_mf: Number of bars used for summing buy and sell dollars.
• Label appearance settings: ATR length, multiplier, size, colors for up/down labels, and connector style and width.
• Toggles: Use enableMoneyFlowLabel_mf and showMFLabels to control whether the module and its labels are displayed.
9.3 Calculations
• Per-bar money: Buy $ = TF_buy_breakout × close; Sell $ = TF_sell_breakout × close. Their difference is Δ$ = Buy $ − Sell $.
• Summations: Over mf_period_len_mf bars, compute Σ Buy $, Σ Sell $ and ΣΔ$ using math.sum().
• Info table entries: Rows 9–13 display these values as texts like “↑ USD 1234 (1M)” or “ΣΔ USD −5678 (14)”, with colors reflecting whether buyers or sellers dominate.
• Money flow status: If Δ$ is positive the bar is marked “Money flow in” ; if negative, “Money flow out” ; if zero, “Neutral”. The cumulative status is similarly derived from ΣΔ.Labels print at the bar that changes the sign of ΣΔ, offset using ATR × label multiplier and styled per user preferences.
Figure caption, The chart illustrates a steady rise toward the highest recent pivot (HH1) with price riding between a rising green trend‑line and a red trend‑line drawn through earlier pivot highs. A green Money flow in label appears above the bar near the top of the channel, signaling that net dollar flow turned positive on this bar: buy‑side dollar volume exceeded sell‑side dollar volume, pushing the cumulative sum ΣΔ$ above zero. In the info table, the “Money flow (bar)” and “Money flow Σ” rows both read In, confirming that the indicator’s money‑flow module has detected an inflow at both bar and aggregate levels, while other modules (pivots, trend lines and support/resistance) remain active to provide structural context.
In this example the Money Flow module signals a net outflow. Price has been trending downward: successive high pivots form a falling red trend‑line and the low pivots form a descending green support line. When the latest bar broke below the previous low pivot (LL1), both the bar‑level and cumulative net dollar flow turned negative—selling volume at the close exceeded buying volume and pushed the cumulative Δ$ below zero. The module reacts by printing a red “Money flow out” label beneath the candle; the info table confirms that the “Money flow (bar)” and “Money flow Σ” rows both show Out, indicating sustained dominance of sellers in this period.
10. Info Table
10.1 Purpose
When enabled, the Info Table appears in the lower right of your chart. It summarises key values computed by the indicator—such as buy and sell volume, delta, total volume, breakout status, market phase, and money flow—so you can see at a glance which side is dominant and which signals are active.
10.2 Symbols
• ↑ / ↓ — Up (↑) denotes buy volume or money; down (↓) denotes sell volume or money.
• MA — Moving average. In the table it shows the average value of a series over the lookback period.
• Σ (Sigma) — Cumulative sum over the chosen lookback period.
• Δ (Delta) — Difference between buy and sell values.
• B / S — Buyer and seller share of total volume, expressed as percentages.
• Ref. Price — Reference price for breakout calculations, based on the latest pivot.
• Status — Indicates whether a breakout condition is currently active (True) or has failed.
10.3 Row definitions
1. Up volume / MA up volume – Displays current buy volume on the lower timeframe and its moving average over the lookback period.
2. Down volume / MA down volume – Shows current sell volume and its moving average; sell values are formatted in red for clarity.
3. Δ / ΣΔ – Lists the difference between buy and sell volume for the current bar and the cumulative delta volume over the lookback period.
4. Σ / MA Σ (Vol/MA) – Total volume (buy + sell) for the bar, with the ratio of this volume to its moving average; the right cell shows the average total volume.
5. B/S ratio – Buy and sell share of the total volume: current bar percentages and the average percentages across the lookback period.
6. Buyer Rank / Seller Rank – Ranks the bar’s buy and sell volumes among the last (n) bars; lower rank numbers indicate higher relative volume.
7. Σ Buy / Σ Sell – Sum of buy and sell volumes over the lookback window, indicating which side has traded more.
8. Breakout UP / DOWN – Shows the breakout thresholds (Ref. Price) and whether the breakout condition is active (True) or has failed.
9. Market Phase (Vol) – Reports the current volume‑only phase: Accumulation, Distribution or Neutral.
10. Money Flow – The final rows display dollar amounts and status:
– ↑ USD / Σ↑ USD – Buy dollars for the current bar and the cumulative sum over the money‑flow period.
– ↓ USD / Σ↓ USD – Sell dollars and their cumulative sum.
– Δ USD / ΣΔ USD – Net dollar difference (buy minus sell) for the bar and cumulatively.
– Money flow (bar) – Indicates whether the bar’s net dollar flow is positive (In), negative (Out) or neutral.
– Money flow Σ – Shows whether the cumulative net dollar flow across the chosen period is positive, negative or neutral.
The chart above shows a sequence of different signals from the indicator. A Bull Trap Risk appears after price briefly pushes above resistance but fails to hold, then a green Accum label identifies an accumulation phase. An upward breakout follows, confirmed by a Money flow in print. Later, a Sharp ↓ Risk warns of a possible sharp downturn; after price dips below support but quickly recovers, a Bear Trap label marks a false breakdown. The highlighted info table in the center summarizes key metrics at that moment, including current and average buy/sell volumes, net delta, total volume versus its moving average, breakout status (up and down), market phase (volume), and bar‑level and cumulative money flow (In/Out).
11. Conclusion & Final Remarks
This indicator was developed as a holistic study of market structure and order flow. It brings together several well‑known concepts from technical analysis—breakouts, accumulation and distribution phases, overbought and oversold extremes, bull and bear traps, sharp directional moves, market‑maker spread bars and money flow—into a single Pine Script tool. Each module is based on widely recognized trading ideas and was implemented after consulting reference materials and example strategies, so you can see in real time how these concepts interact on your chart.
A distinctive feature of this indicator is its reliance on per‑side volume: instead of tallying only total volume, it separately measures buy and sell transactions on a lower time frame. This approach gives a clearer view of who is in control—buyers or sellers—and helps filter breakouts, detect phases of accumulation or distribution, recognize potential traps, anticipate sharp moves and gauge whether liquidity providers are active. The money‑flow module extends this analysis by converting volume into currency values and tracking net inflow or outflow across a chosen window.
Although comprehensive, this indicator is intended solely as a guide. It highlights conditions and statistics that many traders find useful, but it does not generate trading signals or guarantee results. Ultimately, you remain responsible for your positions. Use the information presented here to inform your analysis, combine it with other tools and risk‑management techniques, and always make your own decisions when trading.

light_logLight Log - A Defensive Programming Library for Pine Script
Overview
The Light Log library transforms Pine Script development by introducing structured logging and defensive programming patterns typically found in enterprise languages like C#. This library addresses a fundamental challenge in Pine Script: the lack of sophisticated error handling and debugging tools that developers expect when building complex trading systems.
At its core, Light Log provides three transformative capabilities that work together to create more reliable and maintainable code. First, it wraps all native Pine Script types in error-aware containers, allowing values to carry validation state alongside their data. Second, it offers a comprehensive logging system with severity levels and conditional rendering. Third, it includes defensive programming utilities that catch errors early and make code self-documenting.
The Philosophy of Errors as Values
Traditional Pine Script error handling relies on runtime errors that halt execution, making it difficult to build resilient systems that can gracefully handle edge cases. Light Log introduces a paradigm shift by treating errors as first-class values that flow through your program alongside regular data.
When you wrap a value using Light Log's type system, you're not just storing data – you're creating a container that can carry both the value and its validation state. For example, when you call myNumber.INT() , you receive an INT object that contains both the integer value and a Log object that can describe any issues with that value. This approach, inspired by functional programming languages, allows errors to propagate through calculations without causing immediate failures.
Consider how this changes error handling in practice. Instead of a calculation failing catastrophically when it encounters invalid input, it can produce a result object that contains both the computed value (which might be na) and a detailed log explaining what went wrong. Subsequent operations can check has_error() to decide whether to proceed or handle the error condition gracefully.
The Typed Wrapper System
Light Log provides typed wrappers for every native Pine Script type: INT, FLOAT, BOOL, STRING, COLOR, LINE, LABEL, BOX, TABLE, CHART_POINT, POLYLINE, and LINEFILL. These wrappers serve multiple purposes beyond simple value storage.
Each wrapper type contains two fields: the value field v holds the actual data, while the error field e contains a Log object that tracks the value's validation state. This dual nature enables powerful programming patterns. You can perform operations on wrapped values and accumulate error information along the way, creating an audit trail of how values were processed.
The wrapper system includes convenient methods for converting between wrapped and unwrapped values. The extension methods like INT() , FLOAT() , etc., make it easy to wrap existing values, while the from_INT() , from_FLOAT() methods extract the underlying values when needed. The has_error() method provides a consistent interface for checking whether any wrapped value has encountered issues during processing.
The Log Object: Your Debugging Companion
The Log object represents the heart of Light Log's debugging capabilities. Unlike simple string concatenation for error messages, the Log object provides a structured approach to building, modifying, and rendering diagnostic information.
Each Log object carries three essential pieces of information: an error type (info, warning, error, or runtime_error), a message string that can be built incrementally, and an active flag that controls conditional rendering. This structure enables sophisticated logging patterns where you can build up detailed diagnostic information throughout your script's execution and decide later whether and how to display it.
The Log object's methods support fluent chaining, allowing you to build complex messages in a readable way. The write() and write_line() methods append text to the log, while new_line() adds formatting. The clear() method resets the log for reuse, and the rendering methods ( render_now() , render_condition() , and the general render() ) control when and how messages appear.
Defensive Programming Made Easy
Light Log's argument validation functions transform how you write defensive code. Instead of cluttering your functions with verbose validation logic, you can use concise, self-documenting calls that make your intentions clear.
The argument_error() function provides strict validation that halts execution when conditions aren't met – perfect for catching programming errors early. For less critical issues, argument_log_warning() and argument_log_error() record problems without stopping execution, while argument_log_info() provides debug visibility into your function's behavior.
These functions follow a consistent pattern: they take a condition to check, the function name, the argument name, and a descriptive message. This consistency makes error messages predictable and helpful, automatically formatting them to show exactly where problems occurred.
Building Modular, Reusable Code
Light Log encourages a modular approach to Pine Script development by providing tools that make functions more self-contained and reliable. When functions validate their inputs and return wrapped values with error information, they become true black boxes that can be safely composed into larger systems.
The void_return() function addresses Pine Script's requirement that all code paths return a value, even in error handling branches. This utility function provides a clean way to satisfy the compiler while making it clear that a particular code path should never execute.
The static log pattern, initialized with init_static_log() , enables module-wide error tracking. You can create a persistent Log object that accumulates information across multiple function calls, building a comprehensive diagnostic report that helps you understand complex behaviors in your indicators and strategies.
Real-World Applications
In practice, Light Log shines when building sophisticated trading systems. Imagine developing a complex indicator that processes multiple data streams, performs statistical calculations, and generates trading signals. With Light Log, each processing stage can validate its inputs, perform calculations, and pass along both results and diagnostic information.
For example, a moving average calculation might check that the period is positive, that sufficient data exists, and that the input series contains valid values. Instead of failing silently or throwing runtime errors, it can return a FLOAT object that contains either the calculated average or a detailed explanation of why the calculation couldn't be performed.
Strategy developers benefit even more from Light Log's capabilities. Complex entry and exit logic often involves multiple conditions that must all be satisfied. With Light Log, each condition check can contribute to a comprehensive log that explains exactly why a trade was or wasn't taken, making strategy debugging and optimization much more straightforward.
Performance Considerations
While Light Log adds a layer of abstraction over raw Pine Script values, its design minimizes performance impact. The wrapper objects are lightweight, containing only two fields. The logging operations only consume resources when actually rendered, and the conditional rendering system ensures that production code can run with logging disabled for maximum performance.
The library follows Pine Script best practices for performance, using appropriate data structures and avoiding unnecessary operations. The var keyword in init_static_log() ensures that persistent logs don't create new objects on every bar, maintaining efficiency even in real-time calculations.
Getting Started
Adopting Light Log in your Pine Script projects is straightforward. Import the library, wrap your critical values, add validation to your functions, and use Log objects to track important events. Start small by adding logging to a single function, then expand as you see the benefits of better error visibility and code organization.
Remember that Light Log is designed to grow with your needs. You can use as much or as little of its functionality as makes sense for your project. Even simple uses, like adding argument validation to key functions, can significantly improve code reliability and debugging ease.
Transform your Pine Script development experience with Light Log – because professional trading systems deserve professional development tools.
Light Log Technical Deep Dive: Advanced Patterns and Architecture
Understanding Errors as Values
The concept of "errors as values" represents a fundamental shift in how we think about error handling in Pine Script. In traditional Pine Script development, errors are events – they happen at a specific moment in time and immediately interrupt program flow. Light Log transforms errors into data – they become information that flows through your program just like any other value.
This transformation has profound implications. When errors are values, they can be stored, passed between functions, accumulated, transformed, and inspected. They become part of your program's data flow rather than exceptions to it. This approach, popularized by languages like Rust with its Result type and Haskell with its Either monad, brings functional programming's elegance to Pine Script.
Consider a practical example. Traditional Pine Script might calculate a momentum indicator like this:
momentum = close - close
If period is invalid or if there isn't enough historical data, this calculation might produce na or cause subtle bugs. With Light Log's approach:
calculate_momentum(src, period)=>
result = src.FLOAT()
if period <= 0
result.e.write("Invalid period: must be positive", true, ErrorType.error)
result.v := na
else if bar_index < period
result.e.write("Insufficient data: need " + str.tostring(period) + " bars", true, ErrorType.warning)
result.v := na
else
result.v := src - src
result.e.write("Momentum calculated successfully", false, ErrorType.info)
result
Now the function returns not just a value but a complete computational result that includes diagnostic information. Calling code can make intelligent decisions based on both the value and its associated metadata.
The Monad Pattern in Pine Script
While Pine Script lacks the type system features to implement true monads, Light Log brings monadic thinking to Pine Script development. The wrapped types (INT, FLOAT, etc.) act as computational contexts that carry both values and metadata through a series of transformations.
The key insight of monadic programming is that you can chain operations while automatically propagating context. In Light Log, this context is the error state. When you have a FLOAT that contains an error, operations on that FLOAT can check the error state and decide whether to proceed or propagate the error.
This pattern enables what functional programmers call "railway-oriented programming" – your code follows a success track when all is well but can switch to an error track when problems occur. Both tracks lead to the same destination (a result with error information), but they take different paths based on the validity of intermediate values.
Composable Error Handling
Light Log's design encourages composition – building complex functionality from simpler, well-tested components. Each component can validate its inputs, perform its calculation, and return a result with appropriate error information. Higher-level functions can then combine these results intelligently.
Consider building a complex trading signal from multiple indicators:
generate_signal(src, fast_period, slow_period, signal_period) =>
log = init_static_log(ErrorType.info)
// Calculate components with error tracking
fast_ma = calculate_ma(src, fast_period)
slow_ma = calculate_ma(src, slow_period)
// Check for errors in components
if fast_ma.has_error()
log.write_line("Fast MA error: " + fast_ma.e.message, true)
if slow_ma.has_error()
log.write_line("Slow MA error: " + slow_ma.e.message, true)
// Proceed with calculation if no errors
signal = 0.0.FLOAT()
if not (fast_ma.has_error() or slow_ma.has_error())
macd_line = fast_ma.v - slow_ma.v
signal_line = calculate_ma(macd_line, signal_period)
if signal_line.has_error()
log.write_line("Signal line error: " + signal_line.e.message, true)
signal.e := log
else
signal.v := macd_line - signal_line.v
log.write("Signal generated successfully")
else
signal.e := log
signal.v := na
signal
This composable approach makes complex calculations more reliable and easier to debug. Each component is responsible for its own validation and error reporting, and the composite function orchestrates these components while maintaining comprehensive error tracking.
The Static Log Pattern
The init_static_log() function introduces a powerful pattern for maintaining state across function calls. In Pine Script, the var keyword creates variables that persist across bars but are initialized only once. Light Log leverages this to create logging objects that can accumulate information throughout a script's execution.
This pattern is particularly valuable for debugging complex strategies where you need to understand behavior across multiple bars. You can create module-level logs that track important events:
// Module-level diagnostic log
diagnostics = init_static_log(ErrorType.info)
// Track strategy decisions across bars
check_entry_conditions() =>
diagnostics.clear() // Start fresh each bar
diagnostics.write_line("Bar " + str.tostring(bar_index) + " analysis:")
if close > sma(close, 20)
diagnostics.write_line("Price above SMA20", false)
else
diagnostics.write_line("Price below SMA20 - no entry", true, ErrorType.warning)
if volume > sma(volume, 20) * 1.5
diagnostics.write_line("Volume surge detected", false)
else
diagnostics.write_line("Normal volume", false)
// Render diagnostics based on verbosity setting
if debug_mode
diagnostics.render_now()
Advanced Validation Patterns
Light Log's argument validation functions enable sophisticated precondition checking that goes beyond simple null checks. You can implement complex validation logic while keeping your code readable:
validate_price_data(open_val, high_val, low_val, close_val) =>
argument_error(na(open_val) or na(high_val) or na(low_val) or na(close_val),
"validate_price_data", "OHLC values", "contain na values")
argument_error(high_val < low_val,
"validate_price_data", "high/low", "high is less than low")
argument_error(close_val > high_val or close_val < low_val,
"validate_price_data", "close", "is outside high/low range")
argument_log_warning(high_val == low_val,
"validate_price_data", "high/low", "are equal (no range)")
This validation function documents its requirements clearly and fails fast with helpful error messages when assumptions are violated. The mix of errors (which halt execution) and warnings (which allow continuation) provides fine-grained control over how strict your validation should be.
Performance Optimization Strategies
While Light Log adds abstraction, careful design minimizes overhead. Understanding Pine Script's execution model helps you use Light Log efficiently.
Pine Script executes once per bar, so operations that seem expensive in traditional programming might have negligible impact. However, when building real-time systems, every optimization matters. Light Log provides several patterns for efficient use:
Lazy Evaluation: Log messages are only built when they'll be rendered. Use conditional logging to avoid string concatenation in production:
if debug_mode
log.write_line("Calculated value: " + str.tostring(complex_calculation))
Selective Wrapping: Not every value needs error tracking. Wrap values at API boundaries and critical calculation points, but use raw values for simple operations:
// Wrap at boundaries
input_price = close.FLOAT()
validated_period = validate_period(input_period).INT()
// Use raw values internally
sum = 0.0
for i = 0 to validated_period.v - 1
sum += close
Error Propagation: When errors occur early, avoid expensive calculations:
process_data(input) =>
validated = validate_input(input)
if validated.has_error()
validated // Return early with error
else
// Expensive processing only if valid
perform_complex_calculation(validated)
Integration Patterns
Light Log integrates smoothly with existing Pine Script code. You can adopt it incrementally, starting with critical functions and expanding coverage as needed.
Boundary Validation: Add Light Log at the boundaries of your system – where user input enters and where final outputs are produced. This catches most errors while minimizing changes to existing code.
Progressive Enhancement: Start by adding argument validation to existing functions. Then wrap return values. Finally, add comprehensive logging. Each step improves reliability without requiring a complete rewrite.
Testing and Debugging: Use Light Log's conditional rendering to create debug modes for your scripts. Production users see clean output while developers get detailed diagnostics:
// User input for debug mode
debug = input.bool(false, "Enable debug logging")
// Conditional diagnostic output
if debug
diagnostics.render_now()
else
diagnostics.render_condition() // Only shows errors/warnings
Future-Proofing Your Code
Light Log's patterns prepare your code for Pine Script's evolution. As Pine Script adds more sophisticated features, code that uses structured error handling and defensive programming will adapt more easily than code that relies on implicit assumptions.
The type wrapper system, in particular, positions your code to take advantage of potential future features or more sophisticated type inference. By thinking in terms of wrapped values and error propagation today, you're building code that will remain maintainable and extensible tomorrow.
Light Log doesn't just make your Pine Script better today – it prepares it for the trading systems you'll need to build tomorrow.
Library "light_log"
A lightweight logging and defensive programming library for Pine Script.
Designed for modular and extensible scripts, this utility provides structured runtime validation,
conditional logging, and reusable `Log` objects for centralized error propagation.
It also introduces a typed wrapping system for all native Pine values (e.g., `INT`, `FLOAT`, `LABEL`),
allowing values to carry errors alongside data. This enables functional-style flows with built-in
validation tracking, error detection (`has_error()`), and fluent chaining.
Inspired by structured logging patterns found in systems like C#, it reduces boilerplate,
enforces argument safety, and encourages clean, maintainable code architecture.
method INT(self, error_type)
Wraps an `int` value into an `INT` struct with an optional log severity.
Namespace types: series int, simple int, input int, const int
Parameters:
self (int) : The raw `int` value to wrap.
error_type (series ErrorType) : Optional severity level to associate with the log. Default is `ErrorType.error`.
Returns: An `INT` object containing the value and a default Log instance.
method FLOAT(self, error_type)
Wraps a `float` value into a `FLOAT` struct with an optional log severity.
Namespace types: series float, simple float, input float, const float
Parameters:
self (float) : The raw `float` value to wrap.
error_type (series ErrorType) : Optional severity level to associate with the log. Default is `ErrorType.error`.
Returns: A `FLOAT` object containing the value and a default Log instance.
method BOOL(self, error_type)
Wraps a `bool` value into a `BOOL` struct with an optional log severity.
Namespace types: series bool, simple bool, input bool, const bool
Parameters:
self (bool) : The raw `bool` value to wrap.
error_type (series ErrorType) : Optional severity level to associate with the log. Default is `ErrorType.error`.
Returns: A `BOOL` object containing the value and a default Log instance.
method STRING(self, error_type)
Wraps a `string` value into a `STRING` struct with an optional log severity.
Namespace types: series string, simple string, input string, const string
Parameters:
self (string) : The raw `string` value to wrap.
error_type (series ErrorType) : Optional severity level to associate with the log. Default is `ErrorType.error`.
Returns: A `STRING` object containing the value and a default Log instance.
method COLOR(self, error_type)
Wraps a `color` value into a `COLOR` struct with an optional log severity.
Namespace types: series color, simple color, input color, const color
Parameters:
self (color) : The raw `color` value to wrap.
error_type (series ErrorType) : Optional severity level to associate with the log. Default is `ErrorType.error`.
Returns: A `COLOR` object containing the value and a default Log instance.
method LINE(self, error_type)
Wraps a `line` object into a `LINE` struct with an optional log severity.
Namespace types: series line
Parameters:
self (line) : The raw `line` object to wrap.
error_type (series ErrorType) : Optional severity level to associate with the log. Default is `ErrorType.error`.
Returns: A `LINE` object containing the value and a default Log instance.
method LABEL(self, error_type)
Wraps a `label` object into a `LABEL` struct with an optional log severity.
Namespace types: series label
Parameters:
self (label) : The raw `label` object to wrap.
error_type (series ErrorType) : Optional severity level to associate with the log. Default is `ErrorType.error`.
Returns: A `LABEL` object containing the value and a default Log instance.
method BOX(self, error_type)
Wraps a `box` object into a `BOX` struct with an optional log severity.
Namespace types: series box
Parameters:
self (box) : The raw `box` object to wrap.
error_type (series ErrorType) : Optional severity level to associate with the log. Default is `ErrorType.error`.
Returns: A `BOX` object containing the value and a default Log instance.
method TABLE(self, error_type)
Wraps a `table` object into a `TABLE` struct with an optional log severity.
Namespace types: series table
Parameters:
self (table) : The raw `table` object to wrap.
error_type (series ErrorType) : Optional severity level to associate with the log. Default is `ErrorType.error`.
Returns: A `TABLE` object containing the value and a default Log instance.
method CHART_POINT(self, error_type)
Wraps a `chart.point` value into a `CHART_POINT` struct with an optional log severity.
Namespace types: chart.point
Parameters:
self (chart.point) : The raw `chart.point` value to wrap.
error_type (series ErrorType) : Optional severity level to associate with the log. Default is `ErrorType.error`.
Returns: A `CHART_POINT` object containing the value and a default Log instance.
method POLYLINE(self, error_type)
Wraps a `polyline` object into a `POLYLINE` struct with an optional log severity.
Namespace types: series polyline, series polyline, series polyline, series polyline
Parameters:
self (polyline) : The raw `polyline` object to wrap.
error_type (series ErrorType) : Optional severity level to associate with the log. Default is `ErrorType.error`.
Returns: A `POLYLINE` object containing the value and a default Log instance.
method LINEFILL(self, error_type)
Wraps a `linefill` object into a `LINEFILL` struct with an optional log severity.
Namespace types: series linefill
Parameters:
self (linefill) : The raw `linefill` object to wrap.
error_type (series ErrorType) : Optional severity level to associate with the log. Default is `ErrorType.error`.
Returns: A `LINEFILL` object containing the value and a default Log instance.
method from_INT(self)
Extracts the integer value from an INT wrapper.
Namespace types: INT
Parameters:
self (INT) : The wrapped INT instance.
Returns: The underlying `int` value.
method from_FLOAT(self)
Extracts the float value from a FLOAT wrapper.
Namespace types: FLOAT
Parameters:
self (FLOAT) : The wrapped FLOAT instance.
Returns: The underlying `float` value.
method from_BOOL(self)
Extracts the boolean value from a BOOL wrapper.
Namespace types: BOOL
Parameters:
self (BOOL) : The wrapped BOOL instance.
Returns: The underlying `bool` value.
method from_STRING(self)
Extracts the string value from a STRING wrapper.
Namespace types: STRING
Parameters:
self (STRING) : The wrapped STRING instance.
Returns: The underlying `string` value.
method from_COLOR(self)
Extracts the color value from a COLOR wrapper.
Namespace types: COLOR
Parameters:
self (COLOR) : The wrapped COLOR instance.
Returns: The underlying `color` value.
method from_LINE(self)
Extracts the line object from a LINE wrapper.
Namespace types: LINE
Parameters:
self (LINE) : The wrapped LINE instance.
Returns: The underlying `line` object.
method from_LABEL(self)
Extracts the label object from a LABEL wrapper.
Namespace types: LABEL
Parameters:
self (LABEL) : The wrapped LABEL instance.
Returns: The underlying `label` object.
method from_BOX(self)
Extracts the box object from a BOX wrapper.
Namespace types: BOX
Parameters:
self (BOX) : The wrapped BOX instance.
Returns: The underlying `box` object.
method from_TABLE(self)
Extracts the table object from a TABLE wrapper.
Namespace types: TABLE
Parameters:
self (TABLE) : The wrapped TABLE instance.
Returns: The underlying `table` object.
method from_CHART_POINT(self)
Extracts the chart.point from a CHART_POINT wrapper.
Namespace types: CHART_POINT
Parameters:
self (CHART_POINT) : The wrapped CHART_POINT instance.
Returns: The underlying `chart.point` value.
method from_POLYLINE(self)
Extracts the polyline object from a POLYLINE wrapper.
Namespace types: POLYLINE
Parameters:
self (POLYLINE) : The wrapped POLYLINE instance.
Returns: The underlying `polyline` object.
method from_LINEFILL(self)
Extracts the linefill object from a LINEFILL wrapper.
Namespace types: LINEFILL
Parameters:
self (LINEFILL) : The wrapped LINEFILL instance.
Returns: The underlying `linefill` object.
method has_error(self)
Returns true if the INT wrapper has an active log entry.
Namespace types: INT
Parameters:
self (INT) : The INT instance to check.
Returns: True if an error or message is active in the log.
method has_error(self)
Returns true if the FLOAT wrapper has an active log entry.
Namespace types: FLOAT
Parameters:
self (FLOAT) : The FLOAT instance to check.
Returns: True if an error or message is active in the log.
method has_error(self)
Returns true if the BOOL wrapper has an active log entry.
Namespace types: BOOL
Parameters:
self (BOOL) : The BOOL instance to check.
Returns: True if an error or message is active in the log.
method has_error(self)
Returns true if the STRING wrapper has an active log entry.
Namespace types: STRING
Parameters:
self (STRING) : The STRING instance to check.
Returns: True if an error or message is active in the log.
method has_error(self)
Returns true if the COLOR wrapper has an active log entry.
Namespace types: COLOR
Parameters:
self (COLOR) : The COLOR instance to check.
Returns: True if an error or message is active in the log.
method has_error(self)
Returns true if the LINE wrapper has an active log entry.
Namespace types: LINE
Parameters:
self (LINE) : The LINE instance to check.
Returns: True if an error or message is active in the log.
method has_error(self)
Returns true if the LABEL wrapper has an active log entry.
Namespace types: LABEL
Parameters:
self (LABEL) : The LABEL instance to check.
Returns: True if an error or message is active in the log.
method has_error(self)
Returns true if the BOX wrapper has an active log entry.
Namespace types: BOX
Parameters:
self (BOX) : The BOX instance to check.
Returns: True if an error or message is active in the log.
method has_error(self)
Returns true if the TABLE wrapper has an active log entry.
Namespace types: TABLE
Parameters:
self (TABLE) : The TABLE instance to check.
Returns: True if an error or message is active in the log.
method has_error(self)
Returns true if the CHART_POINT wrapper has an active log entry.
Namespace types: CHART_POINT
Parameters:
self (CHART_POINT) : The CHART_POINT instance to check.
Returns: True if an error or message is active in the log.
method has_error(self)
Returns true if the POLYLINE wrapper has an active log entry.
Namespace types: POLYLINE
Parameters:
self (POLYLINE) : The POLYLINE instance to check.
Returns: True if an error or message is active in the log.
method has_error(self)
Returns true if the LINEFILL wrapper has an active log entry.
Namespace types: LINEFILL
Parameters:
self (LINEFILL) : The LINEFILL instance to check.
Returns: True if an error or message is active in the log.
void_return()
Utility function used when a return is syntactically required but functionally unnecessary.
Returns: Nothing. Function never executes its body.
argument_error(condition, function, argument, message)
Throws a runtime error when a condition is met. Used for strict argument validation.
Parameters:
condition (bool) : Boolean expression that triggers the runtime error.
function (string) : Name of the calling function (for formatting).
argument (string) : Name of the problematic argument.
message (string) : Description of the error cause.
Returns: Never returns. Halts execution if the condition is true.
argument_log_info(condition, function, argument, message)
Logs an informational message when a condition is met. Used for optional debug visibility.
Parameters:
condition (bool) : Boolean expression that triggers the log.
function (string) : Name of the calling function.
argument (string) : Argument name being referenced.
message (string) : Informational message to log.
Returns: Nothing. Logs if the condition is true.
argument_log_warning(condition, function, argument, message)
Logs a warning when a condition is met. Non-fatal but highlights potential issues.
Parameters:
condition (bool) : Boolean expression that triggers the warning.
function (string) : Name of the calling function.
argument (string) : Argument name being referenced.
message (string) : Warning message to log.
Returns: Nothing. Logs if the condition is true.
argument_log_error(condition, function, argument, message)
Logs an error message when a condition is met. Does not halt execution.
Parameters:
condition (bool) : Boolean expression that triggers the error log.
function (string) : Name of the calling function.
argument (string) : Argument name being referenced.
message (string) : Error message to log.
Returns: Nothing. Logs if the condition is true.
init_static_log(error_type, message, active)
Initializes a persistent (var) Log object. Ideal for global logging in scripts or modules.
Parameters:
error_type (series ErrorType) : Initial severity level (required).
message (string) : Optional starting message string. Default value of ("").
active (bool) : Whether the log should be flagged active on initialization. Default value of (false).
Returns: A static Log object with the given parameters.
method new_line(self)
Appends a newline character to the Log message. Useful for separating entries during chained writes.
Namespace types: Log
Parameters:
self (Log) : The Log instance to modify.
Returns: The updated Log object with a newline appended.
method write(self, message, flag_active, error_type)
Appends a message to a Log object without a newline. Updates severity and active state if specified.
Namespace types: Log
Parameters:
self (Log) : The Log instance being modified.
message (string) : The text to append to the log.
flag_active (bool) : Whether to activate the log for conditional rendering. Default value of (false).
error_type (series ErrorType) : Optional override for the severity level. Default value of (na).
Returns: The updated Log object.
method write_line(self, message, flag_active, error_type)
Appends a message to a Log object, prefixed with a newline for clarity.
Namespace types: Log
Parameters:
self (Log) : The Log instance being modified.
message (string) : The text to append to the log.
flag_active (bool) : Whether to activate the log for conditional rendering. Default value of (false).
error_type (series ErrorType) : Optional override for the severity level. Default value of (na).
Returns: The updated Log object.
method clear(self, flag_active, error_type)
Clears a Log object’s message and optionally reactivates it. Can also update the error type.
Namespace types: Log
Parameters:
self (Log) : The Log instance being cleared.
flag_active (bool) : Whether to activate the log after clearing. Default value of (false).
error_type (series ErrorType) : Optional new error type to assign. If not provided, the previous type is retained. Default value of (na).
Returns: The cleared Log object.
method render_condition(self, flag_active, error_type)
Conditionally renders the log if it is active. Allows overriding error type and controlling active state afterward.
Namespace types: Log
Parameters:
self (Log) : The Log instance to evaluate and render.
flag_active (bool) : Whether to activate the log after rendering. Default value of (false).
error_type (series ErrorType) : Optional error type override. Useful for contextual formatting just before rendering. Default value of (na).
Returns: The updated Log object.
method render_now(self, flag_active, error_type)
Immediately renders the log regardless of `active` state. Allows overriding error type and active flag.
Namespace types: Log
Parameters:
self (Log) : The Log instance to render.
flag_active (bool) : Whether to activate the log after rendering. Default value of (false).
error_type (series ErrorType) : Optional error type override. Allows dynamic severity adjustment at render time. Default value of (na).
Returns: The updated Log object.
render(self, condition, flag_active, error_type)
Renders the log conditionally or unconditionally. Allows full control over render behavior.
Parameters:
self (Log) : The Log instance to render.
condition (bool) : If true, renders only if the log is active. If false, always renders. Default value of (false).
flag_active (bool) : Whether to activate the log after rendering. Default value of (false).
error_type (series ErrorType) : Optional error type override passed to the render methods. Default value of (na).
Returns: The updated Log object.
Log
A structured object used to store and render logging messages.
Fields:
error_type (series ErrorType) : The severity level of the message (from the ErrorType enum).
message (series string) : The text of the log message.
active (series bool) : Whether the log should trigger rendering when conditionally evaluated.
INT
A wrapped integer type with attached logging for validation or tracing.
Fields:
v (series int) : The underlying `int` value.
e (Log) : Optional log object describing validation status or error context.
FLOAT
A wrapped float type with attached logging for validation or tracing.
Fields:
v (series float) : The underlying `float` value.
e (Log) : Optional log object describing validation status or error context.
BOOL
A wrapped boolean type with attached logging for validation or tracing.
Fields:
v (series bool) : The underlying `bool` value.
e (Log) : Optional log object describing validation status or error context.
STRING
A wrapped string type with attached logging for validation or tracing.
Fields:
v (series string) : The underlying `string` value.
e (Log) : Optional log object describing validation status or error context.
COLOR
A wrapped color type with attached logging for validation or tracing.
Fields:
v (series color) : The underlying `color` value.
e (Log) : Optional log object describing validation status or error context.
LINE
A wrapped line object with attached logging for validation or tracing.
Fields:
v (series line) : The underlying `line` value.
e (Log) : Optional log object describing validation status or error context.
LABEL
A wrapped label object with attached logging for validation or tracing.
Fields:
v (series label) : The underlying `label` value.
e (Log) : Optional log object describing validation status or error context.
BOX
A wrapped box object with attached logging for validation or tracing.
Fields:
v (series box) : The underlying `box` value.
e (Log) : Optional log object describing validation status or error context.
TABLE
A wrapped table object with attached logging for validation or tracing.
Fields:
v (series table) : The underlying `table` value.
e (Log) : Optional log object describing validation status or error context.
CHART_POINT
A wrapped chart point with attached logging for validation or tracing.
Fields:
v (chart.point) : The underlying `chart.point` value.
e (Log) : Optional log object describing validation status or error context.
POLYLINE
A wrapped polyline object with attached logging for validation or tracing.
Fields:
v (series polyline) : The underlying `polyline` value.
e (Log) : Optional log object describing validation status or error context.
LINEFILL
A wrapped linefill object with attached logging for validation or tracing.
Fields:
v (series linefill) : The underlying `linefill` value.
e (Log) : Optional log object describing validation status or error context.
Hikkake Hunter 2.0This script serves as a successor to a previous script I wrote for identifying Hikkakes nearly two years ago.
The old version has been preserved here:
█ OVERVIEW
This script is a rework of an old script that identified the Hikkake candlestick pattern. While this pattern is not usually considered a part of the standard candlestick patterns set, I found a lot of value when finding a solution to identifying it. A Hikkake pattern is a 3-candle pattern where a middle candle is nested in between the range of the prior candle, and a candle that follows has a higher high and a higher low (bearish setup) or a lower high and a lower low (bullish setup). What makes this pattern unique is the "confirmation" status of the pattern; within 3 candles of this pattern's appearance, there must be a candle that closes above the high (bullish setup) or below the low (bearish setup) of the second candle. Additional flexibility has been added which allows the user to specify the number of candles (up to 5) that the pattern may have to confirm after its appearance.
█ CONCEPTS
This script will cover concepts mainly focusing on candlestick analysis, price analysis (with higher timeframes), and statistical analysis. I believe there is also educational value presented with the use of user-defined-types (UDTs) in accomplishing these concepts that I hope others will find useful.
Candlestick Analysis - Identification and confirmation of the patterns in the deprecated script were clunky and inefficient. While the previous script required the use of 6 candles to perform the confirmations of patterns (restricted solely to identifying patterns that confirmed in 3 candles or less), this script only requires 3 candles to identify and process patterns by utilizing a UDT representing a 'pattern object'. An object representing a pattern will be created when it has been identified, and fields within that object will be set for processing by the functions it is passed to. Pattern objects are held by a var array (values within the array persist between bars) and will be removed from this array once they have been confirmed or non-confirmed.
This is a significant deviation from the previous script's methods, as it prevents unnecessary re-evaluations of the confirmation status of patterns (i.e. Hikkakes confirmed on the first candle will no longer need to be checked for confirmations on the second or third; a pitfall of the deprecated version which required multiple booleans tracking prior confirmation statuses). This deviation is also what provides the flexibility in changing the number of candles that can pass before a pattern is deemed non-confirmed.
As multiple patterns can be confirmed simultaneously, this script uses another UDT representing a linked-list reduction of the pattern object used to process it. This liked-list object will then be used for Price Analysis.
Price Analysis - This script employs the use of a UDT which contains all the returns of confirmed patterns. The user specifies how many candles ahead of the confirmed pattern to calculate its return, as well as where this calculation begins. There are two settings: FROM APPEARANCE and FROM CONFIRMATION (default). Price differences are calculated from the open of the candle immediately following the candle which had confirmed the pattern to the close of the candle X candles ahead (default 10). ( SEE FEATURES )
Because of how Pine functions, this calculation necessitates a lookback on prior candles to identify when a pattern had been confirmed. This is accomplished with the following pseudo-code:
if not na(confirmed linked-list )
for all confirmed in list
GET MATRIX PLACEMENT
offset = FROM CONFIRMATION ? 0 : # of candles to confirm
openAtFind = open
percent return = ((close - openAtFind) / openAtFind) * 100
ADD percent return TO UDT IN MATRIX
All return UDTs are held in a matrix which breaks up these patterns into specific groups covered in the next section.
Higher Timeframes - This script makes a request.security call to a higher timeframe in order to identify a price range which breaks up these patterns into groups based on the 'partition' they had appeared in. The default values for this partitioning will break up the chart into three sections: upper, middle, and lower. The upper section represents the highest 20% of the yearly trading range that an asset has experienced. The lower section represents the trading range within a third (33%) of the yearly low. And the middle section represents the yearly high-low range between these two partitions.
The matrix containing all return UDTs will have these returns split up based on the number of candles required to confirm the pattern as well as the partition the pattern had appeared in. The underlying rationale is that patterns may perform better or worse at different parts of an asset's trading range.
Statistical Analysis - Once a pattern has been confirmed, the matrix containing all return UDTs will be queried to check if a 'returnArray' object has been created for that specific pattern. If not, one will be initialized and a confirmed linked-list object will be created that contains information pertinent to the matrix position of this object.
This matrix contains the returns of both the Bullish and Bearish Hikkake patterns, separated by the number of candles needed to confirm them, and by the partitions they had appeared in. For the standard 3 candles to confirm, this means the matrix will contain 18 elements (dependent on the number of candles allowed for confirmations; its size will range from 12 to 30).
When the required number of candles for Price Analysis passes, a percent return is calculated and added to the returnArray contained in the matrix at the location derived from the confirmed linked-list object's values. The return is added, and all values in the returnArray are updated using Pine's built in array.___ functions. This returnArray object contains the array of all returns, its size, its average, the median, the standard deviation of returns, and a separate 3-integer array which holds values that correspond to the types of returns experienced by this pattern (negative, neutral, and positive)*.
After a pattern has been confirmed, this script will place the partition and all of the aforementioned stats values (plus a 95% confidence interval of expected returns) related to that pattern onto the tooltip of the label that identifies it. This allows users to scroll over the label of a confirmed pattern to gauge its prior performance under specific conditions. The percent return of the specific pattern identified will later be placed onto the label tooltip as well. ( SEE LIMITATIONS )
The stats portion of this script also plays a significant role in how patterns are presented when using the Adaptive Coloring mode described in FEATURES .
*These values are incremented based on user-input related to what constitutes a 'negative' or 'positive' return. Default values would place any return by a pattern between -3% and 3% in the 'neutral' category, and values exceeding either end will be placed in the 'negative' or 'positive' categories.
█ FEATURES
This script contains numerous inputs for modifying its behavior and how patterns are presented/processed, separated into 5 groups.
Confirmation Setting - The most important input for this script's functioning. This input is a 'confirm=true' input and must be set by the user before the script is applied to the chart. It sets the number of candles that a pattern has to confirm once it has been identified.
Alert Settings - This group of booleans sets which types of alerts will fire during the scripts execution on the chart. If enabled, the four alerts will trigger when: a pattern has been identified, a pattern has been confirmed, a pattern has been non-confirmed, and show the return for that confirmed pattern in an alert. Because this script uses the 'alert' function and not 'alertcondition', these must be enabled before 'any alert() function call' is set in TradingView's 'alerts' settings.
Partition Settings - This group of inputs are responsible for creating (and viewing) the partitions that breaks the returns of the patterns identified up into their respective groups. The user may set the resolution to grab the range from, the length back of this resolution the partitions get their values from, the thresholds which breaks the partitions up into their groups, and modify the visibility (if they're shown, the colors, opacity) of these partitions.
Stats Settings - These inputs will drastically alter how patterns are presented and the resulting information derived from them after their appearance. Because of this section's importance, some of these inputs will be described in more detail.
P/L Sample Length - Defines the number of candles after the starting point to grab values from in the % return calculation for that pattern.
P/L Starting Point - Defines the starting point where the P/L calculation will take place. 'FROM APPEARANCE' will set the starting point at the candle immediately following the pattern's appearance. 'FROM CONFIRMATION' will place the starting point immediately following the candle which had confirmed the pattern. ( SEE LIMITATIONS )
Min Returns Needed - Sets how many times a specific pattern must appear (both by number of candles needed to confirm and by partition) before the statistics for that pattern are displayed onto the tooltip (and for gradient coloration in Adaptive Coloring mode).
Enable Adaptive Coloring - Changes the coloration of the patterns based on the bullish/bearishness of the specified Gradient Reference value of that pattern compared to the Return Tolerance values OR the minimum and maximum values of that specified Gradient Reference value contained in the matrix of all returns. This creates a color from a gradient using the user-specified colors and alters how many of the patterns may appear if prior performance is taken into account.
Gradient Reference - Defines which stats measure of returns will be used in the gradient color generation. The two settings are 'AVG' and 'MEDIAN'.
Hard Limit - This boolean sets whether the Return Tolerance values will not be replaced by values that exceed them from the matrix of returns in color gradient generation. This changes the scale of the gradient where any Gradient Reference values of patterns that exceed these tolerances will be colored the full bullish or bearish gradient colors, and anything in between them will be given a color from the gradient.
Visibility Settings - This last section includes all settings associated with the overall visibility of patterns found with this script. This includes the position of the labels and their colors (+ pattern colors without Adaptive Coloring being enabled), and showing patterns that were non-confirmed.
Most of these inputs in the script have these kinds of descriptions to what they do provided by their tooltips.
█ HOW TO USE
I attempted to make this script much easier to use in terms of analyzing the patterns and displaying the information to the user. The previous script would have the user go to the 'data window' side bar on TradingView to view the returns of a pattern after they had specified which pattern to analyze through the settings, needlessly convoluted. This aim at simplicity was achieved through the use of UDTs and specific code-design.
To use, simply apply the indicator to a chart, set the number of candles (between 2 and 5) for confirming this specific pattern and adjust the many settings described above at your leisure.
█ LIMITATIONS
Disclaimer - This is a tool created with the hopes of helping identify a specific pattern and provide an informative view about the performance of that pattern. Previous performance is not indicative of future results. None of this constitutes any form of financial advice, *use at your own risk*.
Statistical Analysis - This script assumes that all patterns will yield a NORMAL DISTRIBUTION regarding their returns which may not be reflective of reality. I personally have limited experience within the field of statistics apart from a few high school/college courses and make no guarantees that the calculation of the 95% confidence interval is correct. Please review the source code to verify for yourself that this interval calculation is correct (Function Name: f_DisplayStatsOnLabel).
P/L Starting Point - Because of when the object related to the confirmation status of a pattern is created (specifically the linked-list object) setting the 'P/L Starting Point' to 'FROM APPEARANCE' will yield the results of that P/L calculation at the same time as 'FROM CONFIRMATION'.
█ EXAMPLES
Default Settings:
Partition Background (default):
Partition Background (Resolution D : Length 30):
Adaptive Coloration:
Show Non-Confirmed:

T3 Striped [Loxx]Theory:
Although T3 is widely used, some of the details on how it is calculated are less known. T3 has, internally, 6 "levels" or "steps" that it uses for its calculation.
This version:
Instead of showing the final T3 value, this indicator shows those intermediate steps. This shows the "building steps" of T3 and can be used for trend assessment as well as for possible support / resistance values.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
Included
Alerts
Signals
Bar coloring
Loxx's Expanded Source Types
CFB-Adaptive CCI w/ T3 Smoothing [Loxx]CFB-Adaptive CCI w/ T3 Smoothing is a CCI indicator with adaptive period inputs and T3 smoothing. Jurik's Composite Fractal Behavior is used to created dynamic period input.
What is Composite Fractal Behavior ( CFB )?
All around you mechanisms adjust themselves to their environment. From simple thermostats that react to air temperature to computer chips in modern cars that respond to changes in engine temperature, r.p.m.'s, torque, and throttle position. It was only a matter of time before fast desktop computers applied the mathematics of self-adjustment to systems that trade the financial markets.
Unlike basic systems with fixed formulas, an adaptive system adjusts its own equations. For example, start with a basic channel breakout system that uses the highest closing price of the last N bars as a threshold for detecting breakouts on the up side. An adaptive and improved version of this system would adjust N according to market conditions, such as momentum, price volatility or acceleration.
Since many systems are based directly or indirectly on cycles, another useful measure of market condition is the periodic length of a price chart's dominant cycle, (DC), that cycle with the greatest influence on price action.
The utility of this new DC measure was noted by author Murray Ruggiero in the January '96 issue of Futures Magazine. In it. Mr. Ruggiero used it to adaptive adjust the value of N in a channel breakout system. He then simulated trading 15 years of D-Mark futures in order to compare its performance to a similar system that had a fixed optimal value of N. The adaptive version produced 20% more profit!
This DC index utilized the popular MESA algorithm (a formulation by John Ehlers adapted from Burg's maximum entropy algorithm, MEM). Unfortunately, the DC approach is problematic when the market has no real dominant cycle momentum, because the mathematics will produce a value whether or not one actually exists! Therefore, we developed a proprietary indicator that does not presuppose the presence of market cycles. It's called CFB (Composite Fractal Behavior) and it works well whether or not the market is cyclic.
CFB examines price action for a particular fractal pattern, categorizes them by size, and then outputs a composite fractal size index. This index is smooth, timely and accurate
Essentially, CFB reveals the length of the market's trending action time frame. Long trending activity produces a large CFB index and short choppy action produces a small index value. Investors have found many applications for CFB which involve scaling other existing technical indicators adaptively, on a bar-to-bar basis.
What is Jurik Volty used in the Juirk Filter?
One of the lesser known qualities of Juirk smoothing is that the Jurik smoothing process is adaptive. "Jurik Volty" (a sort of market volatility ) is what makes Jurik smoothing adaptive. The Jurik Volty calculation can be used as both a standalone indicator and to smooth other indicators that you wish to make adaptive.
What is the Jurik Moving Average?
Have you noticed how moving averages add some lag (delay) to your signals? ... especially when price gaps up or down in a big move, and you are waiting for your moving average to catch up? Wait no more! JMA eliminates this problem forever and gives you the best of both worlds: low lag and smooth lines.
Ideally, you would like a filtered signal to be both smooth and lag-free. Lag causes delays in your trades, and increasing lag in your indicators typically result in lower profits. In other words, late comers get what's left on the table after the feast has already begun.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
Included:
Bar coloring
Signals
Alerts

STD-Filterd, R-squared Adaptive T3 w/ Dynamic Zones [Loxx]STD-Filterd, R-squared Adaptive T3 w/ Dynamic Zones is a standard deviation filtered R-squared Adaptive T3 moving average with dynamic zones.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
What is R-squared Adaptive?
One tool available in forecasting the trendiness of the breakout is the coefficient of determination ( R-squared ), a statistical measurement.
The R-squared indicates linear strength between the security's price (the Y - axis) and time (the X - axis). The R-squared is the percentage of squared error that the linear regression can eliminate if it were used as the predictor instead of the mean value. If the R-squared were 0.99, then the linear regression would eliminate 99% of the error for prediction versus predicting closing prices using a simple moving average .
R-squared is used here to derive a T3 factor used to modify price before passing price through a six-pole non-linear Kalman filter.
What are Dynamic Zones?
As explained in "Stocks & Commodities V15:7 (306-310): Dynamic Zones by Leo Zamansky, Ph .D., and David Stendahl"
Most indicators use a fixed zone for buy and sell signals. Here’ s a concept based on zones that are responsive to past levels of the indicator.
One approach to active investing employs the use of oscillators to exploit tradable market trends. This investing style follows a very simple form of logic: Enter the market only when an oscillator has moved far above or below traditional trading lev- els. However, these oscillator- driven systems lack the ability to evolve with the market because they use fixed buy and sell zones. Traders typically use one set of buy and sell zones for a bull market and substantially different zones for a bear market. And therein lies the problem.
Once traders begin introducing their market opinions into trading equations, by changing the zones, they negate the system’s mechanical nature. The objective is to have a system automatically define its own buy and sell zones and thereby profitably trade in any market — bull or bear. Dynamic zones offer a solution to the problem of fixed buy and sell zones for any oscillator-driven system.
An indicator’s extreme levels can be quantified using statistical methods. These extreme levels are calculated for a certain period and serve as the buy and sell zones for a trading system. The repetition of this statistical process for every value of the indicator creates values that become the dynamic zones. The zones are calculated in such a way that the probability of the indicator value rising above, or falling below, the dynamic zones is equal to a given probability input set by the trader.
To better understand dynamic zones, let's first describe them mathematically and then explain their use. The dynamic zones definition:
Find V such that:
For dynamic zone buy: P{X <= V}=P1
For dynamic zone sell: P{X >= V}=P2
where P1 and P2 are the probabilities set by the trader, X is the value of the indicator for the selected period and V represents the value of the dynamic zone.
The probability input P1 and P2 can be adjusted by the trader to encompass as much or as little data as the trader would like. The smaller the probability, the fewer data values above and below the dynamic zones. This translates into a wider range between the buy and sell zones. If a 10% probability is used for P1 and P2, only those data values that make up the top 10% and bottom 10% for an indicator are used in the construction of the zones. Of the values, 80% will fall between the two extreme levels. Because dynamic zone levels are penetrated so infrequently, when this happens, traders know that the market has truly moved into overbought or oversold territory.
Calculating the Dynamic Zones
The algorithm for the dynamic zones is a series of steps. First, decide the value of the lookback period t. Next, decide the value of the probability Pbuy for buy zone and value of the probability Psell for the sell zone.
For i=1, to the last lookback period, build the distribution f(x) of the price during the lookback period i. Then find the value Vi1 such that the probability of the price less than or equal to Vi1 during the lookback period i is equal to Pbuy. Find the value Vi2 such that the probability of the price greater or equal to Vi2 during the lookback period i is equal to Psell. The sequence of Vi1 for all periods gives the buy zone. The sequence of Vi2 for all periods gives the sell zone.
In the algorithm description, we have: Build the distribution f(x) of the price during the lookback period i. The distribution here is empirical namely, how many times a given value of x appeared during the lookback period. The problem is to find such x that the probability of a price being greater or equal to x will be equal to a probability selected by the user. Probability is the area under the distribution curve. The task is to find such value of x that the area under the distribution curve to the right of x will be equal to the probability selected by the user. That x is the dynamic zone.
Included:
Bar coloring
Signals
Alerts
Loxx's Expanded Source Types

Real Woodies CCIAs always, this is not financial advice and use at your own risk. Trading is risky and can cost you significant sums of money if you are not careful. Make sure you always have a proper entry and exit plan that includes defining your risk before you enter a trade.
Ken Wood is a semi-famous trader that grew in popularity in the 1990s and early 2000s due to the establishment of one of the earliest trading forums online. This forum grew into "Woodie's CCI Club" due to Wood's love of his modified Commodity Channel Index (CCI) that he used extensively. From what I can tell, the website is still active and still follows the same core principles it did in the early days, the CCI is used for entries, range bars are used to help trader's cut down on the noise, and the optional addition of Woodie's Pivot Points can be used as further confirmation of support and resistance. This is my take on his famous "Woodie's CCI" that has become standard on many charting packages through the years, including a TradingView sponsored version as one of the many stock indicators provided by TradingView. Woodie has updated his CCI through the years to include several very cool additions outside of the standard CCI. I will have to say, I am a bit biased, but I think this is hands down one of the best indicators I have ever used, and I am far too young to have been part of the original CCI Club. Being a daytrader primarily, this fits right in my timeframe wheel house. Woodie designed this indicator to work on a day-trading time scale and he frequently uses this to trade futures and commodity contracts on the 30 minute, often even down to the one minute timeframe. This makes it unique in that it is probably one of the only daytrading-designed indicators out there that I am aware of that was not a popular indicator, like the MACD or RSI, that was just adopted by daytraders.
The CCI was originally created by Donald Lambert in 1980. Over time, it has become an extremely popular house-hold indicator, like the Stochastics, RSI, or MACD. However, like the RSI and Stochastics, there are extensive debates on how the CCI is actually meant to be used. Some trade it like a reversal indicator, where values greater than 100 or less than -100 are considered overbought or oversold, respectively. Others trade it like a typical zero-line cross indicator, where once the value goes above or below the zero-line, a trade should be considered in that direction. Lastly, some treat it as strictly a momentum indicator, where values greater than 100 or less than -100 are seen as strong momentum moves and when these values are reached, a new strong trend is establishing in the direction of the move. The CCI itself is nothing fancy, it just visualizes the distance of the closing price away from a user-defined SMA value and plots it as a line. However, Woodie's CCI takes this simple concept and adds to it with an indicator with 5 pieces to it designed to help the trader enter into the highest probability setups. Bear with me, it initially looks super complicated, but I promise it is pretty straight-forward and a fun indicator to use.
1) The CCI Histogram. This is your standard CCI value that you would find on the normal CCI. Woodie's CCI uses a value of 14 for most trades and a value of 20 when the timeframe is equal to or greater than 30minutes. I personally use this as a 20-period CCI on all time frames, simply for the fact that the 20 SMA is a very popular moving average and I want to know what the crowd is doing. This is your coloured histogram with 4 colours. A gray colouring is for any bars above or below the zero line for 1-4 bars. A yellow bar is a "trend bar", where the long period CCI has been above/below the zero line for 5 consecutive bars, indicating that a trend in the current direction has been established. Blue bars above and red bars below are simply 6+n number of bars above or below the zero line confirming trend. These are used for the Zero-Line Reject Trade (explained below). The CCI Histogram has a matching long-period CCI line that is painted the same colour as the histogram, it is the same thing but is used just to outline the Histogram a bit better.
2) The CCI Turbo line. This is a sped-up 6 period CCI. This is to be used for the Zero-Line Reject trades, trendline breaks, and to identify shorter term overbought/oversold conditions against the main trend. This is coloured as the white line.
3) The Least Squares Moving Average Baseline (LSMA) Zero Line. You will notice that the Zero Line of the indicator is either green or red. This is based on when price is above or below the 25-period LSMA on the chart. The LSMA is a 25 period linear regression moving average and is one of the best moving averages out there because it is more immune to noise than a typical MA. Statistically, an LSMA is designed to find the line of best fit across the lookback periods and identify whether price is advancing, declining, or flat, without the whipsaw that other MAs can be privy to. The zero line of the indicator will turn green when the close candle is over the LSMA or red when it is below the LSMA. This is meant to be a confirmation tool only and the CCI Histogram and Turbo Histogram can cross this zero line without any corresponding change in the colour of the zero line on that immediate candle.
4) The +100 and -100 lines are used in two ways. First, they can be used by the CCI Histogram and CCI Turbo as a sort of minor price resistance and if the CCI values cannot get through these, it is considered weakness in that trade direction until they do so. You will notice that both of these lines are multi-coloured. They have been plotted with the ChopZone Indicator, another TradingView built-in indicator. The ChopZone is a trend identification tool that uses the slope and the direction of a 34-period EMA to identify when price is trending or range bound. While there are ~10 different colours, the main two a trader needs to pay attention to are the turquoise/cyan blue, which indicates price is in an uptrend, and dark red, which indicates price is in a downtrend based on the slope and direction of the 34 EMA. All other colours indicate "chop". These colours are used solely for the Zero-Line Reject and pattern trades discussed below. They are plotted both above and below so you can easily see the colouring no matter what side of the zero line the CCI is on.
5) The +200 and -200 lines are also used in two ways. First, they are considered overbought/oversold levels where if price exceeds these lines then it has moved an extreme amount away from the average and is likely to experience a pullback shortly. This is more useful for the CCI Histogram than the Turbo CCI, in all honesty. You will also notice that these are coloured either red, green, or yellow. This is the Sidewinder indicator portion. The documentation on this is extremely sparse, only pointing to a "relationship between the LSMA and the 34 EMA" (see here: tlc.thinkorswim.com). Since I am not a member of Woodie's CCI Club and never intend to be I took some liberty here and decided that the most likely relationship here was the slope of both moving averages. Therefore, the Sidewinder will be green when both the LSMA and the 34 EMA are rising, red when both are falling, and yellow when they are not in agreement with one another (i.e. one rising/flat while the other is flat/falling). I am a big fan of Dr. Alexander Elder as those who follow me know, so consider this like Woodie's version of the Elder Impulse System. I will fully admit that this version of the Sidewinder is a guess and may not represent the real Sidewinder indicator, but it is next to impossible to find any information on this, so I apologize, but my version does do something useful anyways. This is also to be used only with the Zero-Line Reject trades. They are plotted both above and below so you can easily see the colouring no matter what side of the zero line the CCI is on.
How to Trade It According to Woodie's CCI Club:
Now that I have all of my components and history out of the way, this is what you all care about. I will only provide a brief overview of the trades in this system, but there are quite a few more detailed descriptions listed in the Woodie's CCI Club pamphlet. I have had little success trading the "patterns" but they do exist and do work on occasion. I just prefer to trade with the flow of the markets rather than getting overly scalpy. If you are interested in these patterns, see the pamphlet here (www.trading-attitude.com), hop into the forums and see for yourself, or check out a couple of the YouTube videos.
1) Zero line cross. As simple as any other momentum oscillator out there. When the long period CCI crosses above or below the zero line open a trade in that direction. Extra confirmation can be had when the CCI Turbo has already broken the +100/-100 line "resistance or support". Trend traders may wish to wait until the yellow "trend confirmation bar" has been printed.
2) Zero Line Reject. This is when the CCI Turbo heads back down to the zero line and then bounces back in the same direction of the prevailing trend. These are fantastic continuation trades if you missed the initial entry either on the zero line cross or on the trend bar establishment. ZLR trades are only viable when you have the ChopZone indicator showing a trend (turquoise/cyan for uptrend, dark red for downtrend), the LSMA line is green for an uptrend or red for a downtrend, and the SideWinder is either green confirming the uptrend or red confirming the downtrend.
3) Hook From Extreme. This is the exact same as the Zero Line Reject trade, however, the CCI Turbo now goes to the +100/-100 line (whichever is opposite the currently established trend) and then hooks back into the established trend direction. Ideally the HFE trade needs to have the Long CCI Histogram above/below the corresponding 100 level and the CCI Turbo both breaks the 100 level on the trend side and when it does break it has increased ~20 points from the previous value (i.e. CCI Histogram = +150 with LSMA, CZ, and SW all matching up and trend bars printed on CCI Histogram, CCI Turbo went to -120 and bounced to +80 on last 2 bars, current bar closes with CCI Turbo closing at +110).
4) Trend Line Break. Either the CCI Turbo or CCI Histogram, whichever you prefer (I find the Turbo a bit more accurate since its a faster value) creates a series of higher highs/lows you can draw a trend line linking them. When the line breaks the trendline that is your signal to take a counter trade position. For example, if the CCI Turbo is making consistently higher lows and then breaks the trendline through the zero line, you can then go short. This is a good continuation trade.
5) The Tony Trade. Consider this like a combination zero line reject, trend line break, and weak zero line cross all in one. The idea is that the SW, CZ, and LSMA values are all established in one direction. The CCI Histogram should be in an established trend and then cross the zero line but never break the 100 level on the new side as long as it has not printed more than 9 bars on the new side. If the CCI Histogram prints 9 or less bars on the new side and then breaks the trendline and crosses back to the original trend side, that is your signal to take a reversal trade. This is best used in the Elder Triple Screen method (discussed in final section) as a failed dip or rip.
6) The GB100 Trade. This is a similar trade as the Tony Trade, however, the CCI Histogram can break the 100 level on the new side but has to have made less than 6 bars on the new side. A trendline break is not necessary here either, it is more of a "pop and drop" or "momentum failure" trade trying in the new direction.
7) The Famir Trade. This is a failed CCI Long Histogram ZLR trade and is quite complicated. I have never traded this but it is in the pamphlet. Essentially you have a typical ZLR reject (i.e. all components saying it is likely a long/short continuation trade), but the ZLR only stays around the 50 level, goes back to the trend side, fails there as well immediately after 1 bar and then rebreaks to the new side. This is important to be considered with the LSMA value matching the side of the trade, so if the Famir says to go long, you need the LSMA indicator to also say to go long.
8) The Vegas Trade. This is essentially a trend-reversal trade that takes into account the LSMA and a cup and handle formation on the CCI Long Histogram after it has reached an extreme value (+200/-200). You will see the CCI Histogram hit the extreme value, head towards the zero line, and then sort of round out back in the direction of the extreme price. The low point where it reversed back in the direction of the extreme can be considered support or resistance on the CCI and once the CCI Long Histogram breaks this level again, with LSMA confirmation, you can take a counter trend trade with a stop under/over the highest/lowest point of the last 2 bars as you want to be out quickly if you are wrong without much damage but can get a huge win if you are right and add later to the position once a new trade has formed.
9) The Ghost Trade. This is nothing more than a(n) (inverse) head and shoulders pattern created on the CCI. Draw a trend line connecting the head and shoulders and trade a reversal trade once the CCI Long Histogram breaks the trend line. Same deal as the Vegas Trade, stop over/under the most recent 2 bar high/low and add later if it is a winner but cut quickly if it is a loser.
Like I said, this is a complicated system and could quite literally take years to master if you wanted to go into the patterns and master them. I prefer to trade it in a much simpler format, using the Elder Triple Screen System. First, since I am a day trader, I look to use the 20 period Woodie's on the hourly and look at the CZ, SW, and LSMA values to make sure they all match the direction of the CCI Long Histogram (a trend establishment is not necessary here). It shows you the hourly trend as your "tide". I then drill down to the 15 minute time frame and use the Turbo CCI break in the opposite direction of the trend as my "wave" and to indicate when there is a dip or rip against the main trend. Lastly, I drill down to a 3 minute time frame and enter when the CCI Long Histogram turns back to match the main trend ("ripple") as long as the CCI Turbo has broken the 100 level in the matched direction.
Enjoy, and please read the pamphlet if you have any questions about the patterns as they are not how I use these and will not be able to answer those questions.

{Gunzo} Heiken Ashi RibbonsHeiken Ashi Ribbons is a trend-following indicator which gives entry and exit points for short-term, medium-term and long term trading (using Exponential Moving Averages and Heiken Ashi formulas).
OVERVIEW :
The Heiken Ashi Ribbons indicator is composed of 3 moving average ribbons (slow, normal and fast) that are computed using the Heiken Ashi formulas. The 3 ribbons give a clear vision of the current trend as they use moving averages that smooth out the price and filter noise from short term fluctuations. In a simplified way, you can consider each ribbon as a moving average with a larger body size.
If the price is above the slow ribbon, we consider the asset as trending up in the short term (trending down otherwise). If the price is above the fast ribbon, we consider the asset as trending up in the long term (trending down otherwise).
CALCULATION :
First of all, to compute a ribbon for this indicator we calculate a moving average (EMA by default) for common sources (OHLC) :
EMA (open), EMA (high), EMA (low), EMA (close)
We then apply the Heiken Ashi formulas to the moving averages calculated previously.
HA (open) = HA (open) previous + HA (close) previous
HA (close) = ( EMA (open) + EMA (high) + EMA (low) + EMA (close) ) / 4
HA (high) = max( EMA (open), EMA (close), EMA (high) )
HA (low) = min ( EMA (open), EMA (close), EMA (low) )
The ribbon displayed (by default) on the chart is the area between HA (open) and HA (close).
SETTINGS :
1st Moving average length : Length of the slow moving average
2nd Moving average length : Length of the normal moving average
3rd Moving average length : Length of the fast moving average
Moving average method : Moving average calculation method (EMA : Exponential Moving Average, SMA : Simple Moving Average, WMA : Weighted Moving Average)
Ribbon type : standard ribbon uses the area between HA (open) and HA (close). Large ribbon uses the area between HA (low) and HA (high)
Display ribbon as candles : change the type of visualization between area and candles
Display short term buy/sell signals : Display short term buy/sell signals (crosses) when the fast moving average and normal moving average are crossing
Display long term buy/sell signals : Display long buy/sell signals (circles) when the fast moving average and slow moving average are crossing
Display ribbon trending up signals : Display ribbon direction change (triangle up) when the trend of the ribbon changes to trending up
Display ribbon trending down signals : Display ribbon direction change (triangle down) when the trend of the ribbon changes to trending down
VISUALIZATIONS :
This indicator has 2 possible visualizations :
Ribbons : the ribbons can be considered as enhanced moving averages for trading purposes. They represent the area between the Heiken Ashi of the moving average of the open and closing price. The color of the moving average line is green when the ribbon is trending up and red when the ribbon is trending down.
Signals : Various signals can be displayed at the bottom of the chart (Buy/Sell signals, Ribbon direction changes signals).
USAGE :
This indicator can be used in many strategies, just like when you are using multiple moving averages. You should test these strategies and use the one that best fits your trading style.
Strategy based on crossovers :
When the fast ribbon crosses above the normal ribbon, it is a short term buy signal (it is recommended to wait for a confirmation)
When the fast ribbon crosses under the normal ribbon, it is a short term sell signal (it is recommended to wait for a confirmation)
When the fast ribbon crosses above the slow ribbon, it is a long term buy signal
When the fast ribbon crosses over the slow ribbon, it is a long term buy signal
Strategy based on price position :
When the prices closes above the ribbon, it is a buy signal (long term if above slow ribbon, short term if above fast ribbon)
When the prices closes below the ribbon, it is a sell signal (long term if below slow ribbon, short term if below fast ribbon)
Strategy based on price bouncing :
When the price decreases and reaches the green long term ribbon, the price candles may not be able to cross the ribbon. If the price increases, we consider that move as a bounce on the ribbon, which is a buy signal
When the price increases and reaches a red long term ribbon, the price candles may not be able to cross the ribbon. If the price decreases, we consider that move as a bounce on the ribbon, which is a sell signal
Strategy based on ribbon direction :
When the direction of the ribbon changes, the trend of the asset is changing which may lead to a crossover to the next candles if the trend is continuing in that direction (it is recommended to validate the entry points with a second indicator as this strategy may have some false signals).