Log Regression Channel [UAlgo]The "Log Regression Channel " channel is useful for analyzing price trends and volatility in a financial instrument over a specified period. By using logarithmic scaling, this indicator can more effectively handle the wide range of price movements seen in many financial markets, making it particularly valuable for assets with exponential growth characteristics.
The indicator plots the central regression line along with upper and lower deviation bands, providing a visual representation of potential support and resistance levels.
🔶 Key Features
Logarithmic Regression Line: The central line represents the logarithmic regression, which fits the price data over the specified length using a logarithmic scale. This helps in identifying the overall trend direction.
Deviation Bands: The upper and lower bands are plotted at a specified multiple of the standard deviation from the regression line, highlighting areas of potential overbought and oversold conditions.
Customizable Parameters: Users can adjust the length of the regression, the deviation multiplier, the color of the labels, and the size of the text labels to suit their preferences.
R-Squared Display: The R-squared value, which measures the goodness of fit of the regression model, is displayed on the chart. This helps traders assess the reliability of the regression line.
🔶 Calculations
The indicator performs several key calculations to plot the logarithmic regression channel:
Logarithmic Transformation: The prices and time indices are transformed using the natural logarithm to handle exponential growth in price data.
Regression Coefficients: The slope and intercept of the regression line are calculated using the least squares method on the transformed data.
Predicted Values: The regression equation is used to calculate predicted values for each data point.
Standard Deviation: The standard deviation of the residuals (differences between actual and predicted values) is computed to determine the width of the deviation bands.
Deviation Bands: Upper and lower bands are plotted at a specified multiple of the standard deviation above and below the regression line.
R-Squared Value: The R-squared value is calculated to measure how well the regression line fits the data. This value is displayed on the chart to inform the user of the model's reliability.
🔶 Disclaimer
The "Log Regression Channel " indicator is provided for educational and informational purposes only.
It is not intended as investment advice or a recommendation to buy or sell any financial instrument. Trading financial instruments involves substantial risk and may not be suitable for all investors.
Past performance is not indicative of future results. Users should conduct their own research.
Phương pháp Hệ số R bình phương

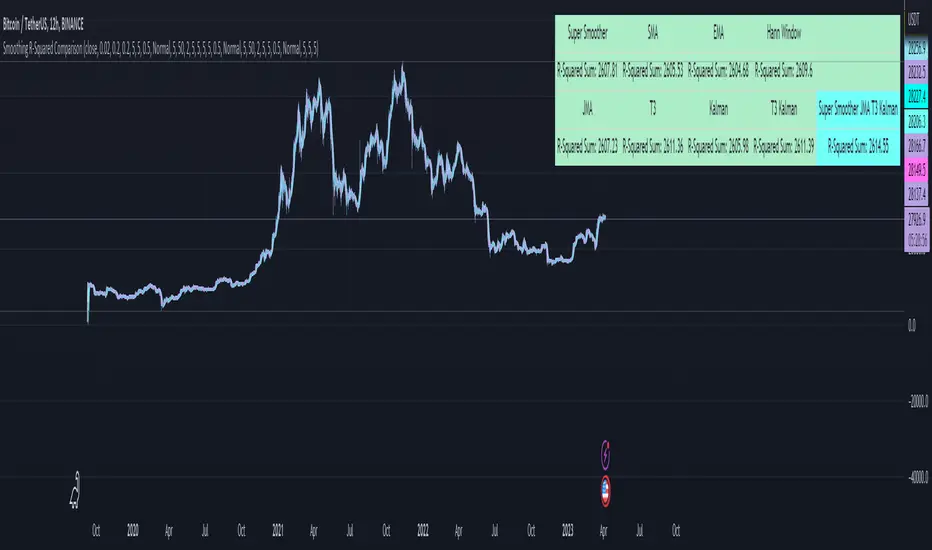
Smoothing R-Squared ComparisonIntroduction
Heyo guys, here I made a comparison between my favorised smoothing algorithms.
I chose the R-Squared value as rating factor to accomplish the comparison.
The indicator is non-repainting.
Description
In technical analysis, traders often use moving averages to smooth out the noise in price data and identify trends. While moving averages are a useful tool, they can also obscure important information about the underlying relationship between the price and the smoothed price.
One way to evaluate this relationship is by calculating the R-squared value, which represents the proportion of the variance in the price that can be explained by the smoothed price in a linear regression model.
This PineScript code implements a smoothing R-squared comparison indicator.
It provides a comparison of different smoothing techniques such as Kalman filter, T3, JMA, EMA, SMA, Super Smoother and some special combinations of them.
The Kalman filter is a mathematical algorithm that uses a series of measurements observed over time, containing statistical noise and other inaccuracies, and produces estimates of unknown variables that tend to be more accurate than those based on a single measurement.
The input parameters for the Kalman filter include the process noise covariance and the measurement noise covariance, which help to adjust the sensitivity of the filter to changes in the input data.
The T3 smoothing technique is a popular method used in technical analysis to remove noise from a signal.
The input parameters for the T3 smoothing method include the length of the window used for smoothing, the type of smoothing used (Normal or New), and the smoothing factor used to adjust the sensitivity to changes in the input data.
The JMA smoothing technique is another popular method used in technical analysis to remove noise from a signal.
The input parameters for the JMA smoothing method include the length of the window used for smoothing, the phase used to shift the input data before applying the smoothing algorithm, and the power used to adjust the sensitivity of the JMA to changes in the input data.
The EMA and SMA techniques are also popular methods used in technical analysis to remove noise from a signal.
The input parameters for the EMA and SMA techniques include the length of the window used for smoothing.
The indicator displays a comparison of the R-squared values for each smoothing technique, which provides an indication of how well the technique is fitting the data.
Higher R-squared values indicate a better fit. By adjusting the input parameters for each smoothing technique, the user can compare the effectiveness of different techniques in removing noise from the input data.
Usage
You can use it to find the best fitting smoothing method for the timeframe you usually use.
Just apply it on your preferred timeframe and look for the highlighted table cell.
Conclusion
It seems like the T3 works best on timeframes under 4H.
There's where I am active, so I will use this one more in the future.
Thank you for checking this out. Enjoy your day and leave me a like or comment. 🧙♂️
---
Credits to:
▪@loxx – T3
▪@balipour – Super Smoother
▪ChatGPT – Wrote 80 % of this article and helped with the research
R Squared - MomentumThis little oscillator just returns the R Squared Value of current price action.
It is designed to show trend direction momentum. Great for confluence!

R-squared Adaptive T3 Ribbon Filled Simple [Loxx]R-squared Adaptive T3 Ribbon Filled Simple is a T3 ribbons indicator that uses a special implementation of T3 that is R-squared adaptive.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
What is R-squared Adaptive?
One tool available in forecasting the trendiness of the breakout is the coefficient of determination ( R-squared ), a statistical measurement.
The R-squared indicates linear strength between the security's price (the Y - axis) and time (the X - axis). The R-squared is the percentage of squared error that the linear regression can eliminate if it were used as the predictor instead of the mean value. If the R-squared were 0.99, then the linear regression would eliminate 99% of the error for prediction versus predicting closing prices using a simple moving average .
R-squared is used here to derive a T3 factor used to modify price before passing price through a six-pole non-linear Kalman filter.
Included:
Alerts
Signals
Loxx's Expanded Source Types
R-squared Adaptive T3 w/ DSL [Loxx]R-squared Adaptive T3 w/ DSL is the following T3 indicator but with Discontinued Signal Lines added to reduce noise and thereby increase signal accuracy. This adaptation makes this indicator lower TF scalp friendly.
What is R-squared Adaptive?
One tool available in forecasting the trendiness of the breakout is the coefficient of determination ( R-squared ), a statistical measurement.
The R-squared indicates linear strength between the security's price (the Y - axis) and time (the X - axis). The R-squared is the percentage of squared error that the linear regression can eliminate if it were used as the predictor instead of the mean value. If the R-squared were 0.99, then the linear regression would eliminate 99% of the error for prediction versus predicting closing prices using a simple moving average .
R-squared is used here to derive a T3 factor used to modify price before passing price through a six-pole non-linear Kalman filter.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
Included:
Bar coloring
Signals
Alerts
EMA and FEMA Signla/DSL smoothing
Loxx's Expanded Source Types
R-sqrd Adapt. Fisher Transform w/ D. Zones & Divs. [Loxx]The full name of this indicator is R-Squared Adaptive Fisher Transform w/ Dynamic Zones and Divergences. This is an R-squared adaptive Fisher transform with adjustable dynamic zones, signals, alerts, and divergences.
What is Fisher Transform?
The Fisher Transform is a technical indicator created by John F. Ehlers that converts prices into a Gaussian normal distribution.
The indicator highlights when prices have moved to an extreme, based on recent prices. This may help in spotting turning points in the price of an asset. It also helps show the trend and isolate the price waves within a trend.
What is R-squared Adaptive?
One tool available in forecasting the trendiness of the breakout is the coefficient of determination ( R-squared ), a statistical measurement.
The R-squared indicates linear strength between the security's price (the Y - axis) and time (the X - axis). The R-squared is the percentage of squared error that the linear regression can eliminate if it were used as the predictor instead of the mean value. If the R-squared were 0.99, then the linear regression would eliminate 99% of the error for prediction versus predicting closing prices using a simple moving average .
R-squared is used here to derive an r-squared value that is then modified by a user input "factor"
What are Dynamic Zones?
As explained in "Stocks & Commodities V15:7 (306-310): Dynamic Zones by Leo Zamansky, Ph .D., and David Stendahl"
Most indicators use a fixed zone for buy and sell signals. Here’ s a concept based on zones that are responsive to past levels of the indicator.
One approach to active investing employs the use of oscillators to exploit tradable market trends. This investing style follows a very simple form of logic: Enter the market only when an oscillator has moved far above or below traditional trading lev- els. However, these oscillator- driven systems lack the ability to evolve with the market because they use fixed buy and sell zones. Traders typically use one set of buy and sell zones for a bull market and substantially different zones for a bear market. And therein lies the problem.
Once traders begin introducing their market opinions into trading equations, by changing the zones, they negate the system’s mechanical nature. The objective is to have a system automatically define its own buy and sell zones and thereby profitably trade in any market — bull or bear. Dynamic zones offer a solution to the problem of fixed buy and sell zones for any oscillator-driven system.
An indicator’s extreme levels can be quantified using statistical methods. These extreme levels are calculated for a certain period and serve as the buy and sell zones for a trading system. The repetition of this statistical process for every value of the indicator creates values that become the dynamic zones. The zones are calculated in such a way that the probability of the indicator value rising above, or falling below, the dynamic zones is equal to a given probability input set by the trader.
To better understand dynamic zones, let's first describe them mathematically and then explain their use. The dynamic zones definition:
Find V such that:
For dynamic zone buy: P{X <= V}=P1
For dynamic zone sell: P{X >= V}=P2
where P1 and P2 are the probabilities set by the trader, X is the value of the indicator for the selected period and V represents the value of the dynamic zone.
The probability input P1 and P2 can be adjusted by the trader to encompass as much or as little data as the trader would like. The smaller the probability, the fewer data values above and below the dynamic zones. This translates into a wider range between the buy and sell zones. If a 10% probability is used for P1 and P2, only those data values that make up the top 10% and bottom 10% for an indicator are used in the construction of the zones. Of the values, 80% will fall between the two extreme levels. Because dynamic zone levels are penetrated so infrequently, when this happens, traders know that the market has truly moved into overbought or oversold territory.
Calculating the Dynamic Zones
The algorithm for the dynamic zones is a series of steps. First, decide the value of the lookback period t. Next, decide the value of the probability Pbuy for buy zone and value of the probability Psell for the sell zone.
For i=1, to the last lookback period, build the distribution f(x) of the price during the lookback period i. Then find the value Vi1 such that the probability of the price less than or equal to Vi1 during the lookback period i is equal to Pbuy. Find the value Vi2 such that the probability of the price greater or equal to Vi2 during the lookback period i is equal to Psell. The sequence of Vi1 for all periods gives the buy zone. The sequence of Vi2 for all periods gives the sell zone.
In the algorithm description, we have: Build the distribution f(x) of the price during the lookback period i. The distribution here is empirical namely, how many times a given value of x appeared during the lookback period. The problem is to find such x that the probability of a price being greater or equal to x will be equal to a probability selected by the user. Probability is the area under the distribution curve. The task is to find such value of x that the area under the distribution curve to the right of x will be equal to the probability selected by the user. That x is the dynamic zone.
Included:
Bar coloring
4 signal variations w/ alerts
Divergences w/ alerts
Loxx's Expanded Source Types
STD-Filterd, R-squared Adaptive T3 w/ Dynamic Zones [Loxx]STD-Filterd, R-squared Adaptive T3 w/ Dynamic Zones is a standard deviation filtered R-squared Adaptive T3 moving average with dynamic zones.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
What is R-squared Adaptive?
One tool available in forecasting the trendiness of the breakout is the coefficient of determination ( R-squared ), a statistical measurement.
The R-squared indicates linear strength between the security's price (the Y - axis) and time (the X - axis). The R-squared is the percentage of squared error that the linear regression can eliminate if it were used as the predictor instead of the mean value. If the R-squared were 0.99, then the linear regression would eliminate 99% of the error for prediction versus predicting closing prices using a simple moving average .
R-squared is used here to derive a T3 factor used to modify price before passing price through a six-pole non-linear Kalman filter.
What are Dynamic Zones?
As explained in "Stocks & Commodities V15:7 (306-310): Dynamic Zones by Leo Zamansky, Ph .D., and David Stendahl"
Most indicators use a fixed zone for buy and sell signals. Here’ s a concept based on zones that are responsive to past levels of the indicator.
One approach to active investing employs the use of oscillators to exploit tradable market trends. This investing style follows a very simple form of logic: Enter the market only when an oscillator has moved far above or below traditional trading lev- els. However, these oscillator- driven systems lack the ability to evolve with the market because they use fixed buy and sell zones. Traders typically use one set of buy and sell zones for a bull market and substantially different zones for a bear market. And therein lies the problem.
Once traders begin introducing their market opinions into trading equations, by changing the zones, they negate the system’s mechanical nature. The objective is to have a system automatically define its own buy and sell zones and thereby profitably trade in any market — bull or bear. Dynamic zones offer a solution to the problem of fixed buy and sell zones for any oscillator-driven system.
An indicator’s extreme levels can be quantified using statistical methods. These extreme levels are calculated for a certain period and serve as the buy and sell zones for a trading system. The repetition of this statistical process for every value of the indicator creates values that become the dynamic zones. The zones are calculated in such a way that the probability of the indicator value rising above, or falling below, the dynamic zones is equal to a given probability input set by the trader.
To better understand dynamic zones, let's first describe them mathematically and then explain their use. The dynamic zones definition:
Find V such that:
For dynamic zone buy: P{X <= V}=P1
For dynamic zone sell: P{X >= V}=P2
where P1 and P2 are the probabilities set by the trader, X is the value of the indicator for the selected period and V represents the value of the dynamic zone.
The probability input P1 and P2 can be adjusted by the trader to encompass as much or as little data as the trader would like. The smaller the probability, the fewer data values above and below the dynamic zones. This translates into a wider range between the buy and sell zones. If a 10% probability is used for P1 and P2, only those data values that make up the top 10% and bottom 10% for an indicator are used in the construction of the zones. Of the values, 80% will fall between the two extreme levels. Because dynamic zone levels are penetrated so infrequently, when this happens, traders know that the market has truly moved into overbought or oversold territory.
Calculating the Dynamic Zones
The algorithm for the dynamic zones is a series of steps. First, decide the value of the lookback period t. Next, decide the value of the probability Pbuy for buy zone and value of the probability Psell for the sell zone.
For i=1, to the last lookback period, build the distribution f(x) of the price during the lookback period i. Then find the value Vi1 such that the probability of the price less than or equal to Vi1 during the lookback period i is equal to Pbuy. Find the value Vi2 such that the probability of the price greater or equal to Vi2 during the lookback period i is equal to Psell. The sequence of Vi1 for all periods gives the buy zone. The sequence of Vi2 for all periods gives the sell zone.
In the algorithm description, we have: Build the distribution f(x) of the price during the lookback period i. The distribution here is empirical namely, how many times a given value of x appeared during the lookback period. The problem is to find such x that the probability of a price being greater or equal to x will be equal to a probability selected by the user. Probability is the area under the distribution curve. The task is to find such value of x that the area under the distribution curve to the right of x will be equal to the probability selected by the user. That x is the dynamic zone.
Included:
Bar coloring
Signals
Alerts
Loxx's Expanded Source Types

Pips-Stepped, R-squared Adaptive T3 [Loxx]Pips-Stepped, R-squared Adaptive T3 is a a T3 moving average with optional adaptivity, trend following, and pip-stepping. This indicator also uses optional flat coloring to determine chops zones. This indicator is R-squared adaptive. This is also an experimental indicator.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
What is R-squared Adaptive?
One tool available in forecasting the trendiness of the breakout is the coefficient of determination (R-squared), a statistical measurement.
The R-squared indicates linear strength between the security's price (the Y - axis) and time (the X - axis). The R-squared is the percentage of squared error that the linear regression can eliminate if it were used as the predictor instead of the mean value. If the R-squared were 0.99, then the linear regression would eliminate 99% of the error for prediction versus predicting closing prices using a simple moving average.
R-squared is used here to derive a T3 factor used to modify price before passing price through a six-pole non-linear Kalman filter.
Included:
Bar coloring
Signals
Alerts
Flat coloring
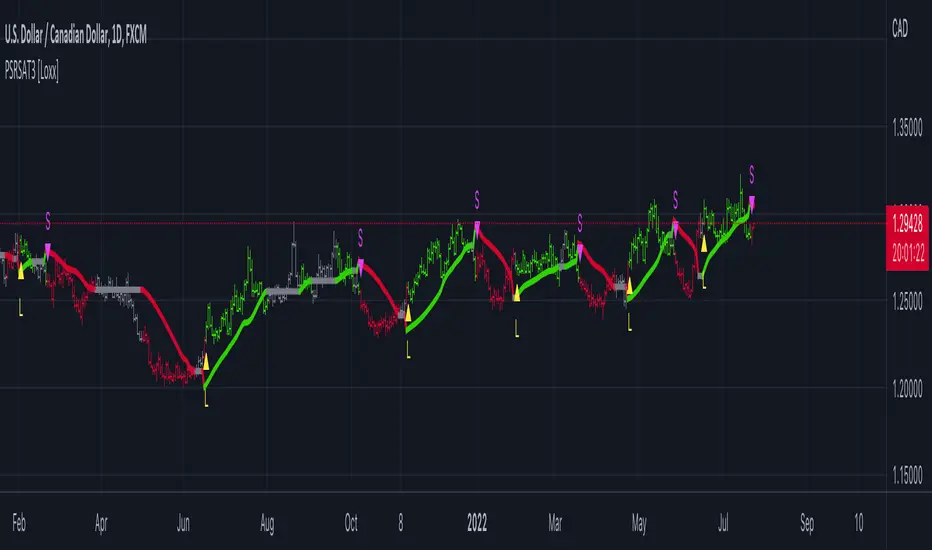
Adaptive Supertrend w/ Floating Levels [Loxx]Adaptive Supertrend w/ Floating Levels is a Supertrend indicator made adaptive by comparing the coefficient of determination / average of the least squares. The basic concept is this: use correlation with an r-squared line to adapt the period of the indicator, thereby resulting in a more versatile Supertrend. This adaptive formula makes the Supertrend more reactive to small fluctuation in the market while still doing what it's supposed to do: track trend. In addition, floating levels are drawn above or below the Supertrend which are calculated with percentage of the highest and lowest values of the Supertrend within the last “lookback” period. These floating levels act as filter to detect / prevent false trend reversals. T
What is the Supertrend?
Supertrend indicator was created by Olivier Seban to work on different time frames. It works for futures, forex, and equities. It is used in 15 minutes, hourly, weekly, and daily charts. Based on the parameters of multiplier and period, the indicator normally uses 3 for multiplier and 7 for the ATR period as default values. Average True Range is represented by the number of days while the multiplier is the value by which the range is multiplied.
Included
-Toggle on/off bar coloring
-Toggle on/off adaptivity
-Toggle on/off fill coloring
[blackcat] L2 Ehlers Adaptive Jon Andersen R-Squared IndicatorLevel: 2
Background
@pips_v1 has proposed an interesting idea that is it possible to code an "Adaptive Jon Andersen R-Squared Indicator" where the length is determined by DCPeriod as calculated in Ehlers Sine Wave Indicator? I agree with him and starting to construct this indicator. After a study, I found "(blackcat) L2 Ehlers Autocorrelation Periodogram" script could be reused for this purpose because Ehlers Autocorrelation Periodogram is an ideal candidate to calculate the dominant cycle. On the other hand, there are two inputs for R-Squared indicator:
Length - number of bars to calculate moment correlation coefficient R
AvgLen - number of bars to calculate average R-square
I used Ehlers Autocorrelation Periodogram to produced a dynamic value of "Length" of R-Squared indicator and make it adaptive.
Function
One tool available in forecasting the trendiness of the breakout is the coefficient of determination (R-squared), a statistical measurement. The R-squared indicates linear strength between the security's price (the Y - axis) and time (the X - axis). The R-squared is the percentage of squared error that the linear regression can eliminate if it were used as the predictor instead of the mean value. If the R-squared were 0.99, then the linear regression would eliminate 99% of the error for prediction versus predicting closing prices using a simple moving average.
When the R-squared is at an extreme low, indicating that the mean is a better predictor than regression, it can only increase, indicating that the regression is becoming a better predictor than the mean. The opposite is true for extreme high values of the R-squared.
To make this indicator adaptive, the dominant cycle is extracted from the spectral estimate in the next block of code using a center-of-gravity ( CG ) algorithm. The CG algorithm measures the average center of two-dimensional objects. The algorithm computes the average period at which the powers are centered. That is the dominant cycle. The dominant cycle is a value that varies with time. The spectrum values vary between 0 and 1 after being normalized. These values are converted to colors. When the spectrum is greater than 0.5, the colors combine red and yellow, with yellow being the result when spectrum = 1 and red being the result when the spectrum = 0.5. When the spectrum is less than 0.5, the red saturation is decreased, with the result the color is black when spectrum = 0.
Construction of the autocorrelation periodogram starts with the autocorrelation function using the minimum three bars of averaging. The cyclic information is extracted using a discrete Fourier transform (DFT) of the autocorrelation results. This approach has at least four distinct advantages over other spectral estimation techniques. These are:
1. Rapid response. The spectral estimates start to form within a half-cycle period of their initiation.
2. Relative cyclic power as a function of time is estimated. The autocorrelation at all cycle periods can be low if there are no cycles present, for example, during a trend. Previous works treated the maximum cycle amplitude at each time bar equally.
3. The autocorrelation is constrained to be between minus one and plus one regardless of the period of the measured cycle period. This obviates the need to compensate for Spectral Dilation of the cycle amplitude as a function of the cycle period.
4. The resolution of the cyclic measurement is inherently high and is independent of any windowing function of the price data.
Key Signal
DC --> Ehlers dominant cycle.
AvgSqrR --> R-squared output of the indicator.
Remarks
This is a Level 2 free and open source indicator.
Feedbacks are appreciated.

[blackcat] L1 Jon Andersen R-Squared IndicatorLevel: 1
Background
The R-Squared indicator created by Jon Andersen in "Standard error bands" in the September 1996 STOCKS & COMMODITIES .
Function
This script fristly creates the coeffR function which is used to produced the R-Squared indicator. The coeffR function is used to calculate the correlation coefficient R. Once I have created and verified the coeffR function, the R-Sqaured indicator can be built easily.
Key Signal
AvgSqrR --> Smoothed R-Squared Oscillator Output.
Labels and alerts are added.
Remarks
Feedbacks are appreciated.
Readme
In real life, I am a prolific inventor. I have successfully applied for more than 60 international and regional patents in the past 12 years. But in the past two years or so, I have tried to transfer my creativity to the development of trading strategies. Tradingview is the ideal platform for me. I am selecting and contributing some of the hundreds of scripts to publish in Tradingview community. Welcome everyone to interact with me to discuss these interesting pine scripts.
The scripts posted are categorized into 5 levels according to my efforts or manhours put into these works.
Level 1 : interesting script snippets or distinctive improvement from classic indicators or strategy. Level 1 scripts can usually appear in more complex indicators as a function module or element.
Level 2 : composite indicator/strategy. By selecting or combining several independent or dependent functions or sub indicators in proper way, the composite script exhibits a resonance phenomenon which can filter out noise or fake trading signal to enhance trading confidence level.
Level 3 : comprehensive indicator/strategy. They are simple trading systems based on my strategies. They are commonly containing several or all of entry signal, close signal, stop loss, take profit, re-entry, risk management, and position sizing techniques. Even some interesting fundamental and mass psychological aspects are incorporated.
Level 4 : script snippets or functions that do not disclose source code. Interesting element that can reveal market laws and work as raw material for indicators and strategies. If you find Level 1~2 scripts are helpful, Level 4 is a private version that took me far more efforts to develop.
Level 5 : indicator/strategy that do not disclose source code. private version of Level 3 script with my accumulated script processing skills or a large number of custom functions. I had a private function library built in past two years. Level 5 scripts use many of them to achieve private trading strategy.

Optimized Linear Regression ChannelReturn a linear regression channel with a window size within the range (min, max) such that the R-squared is maximized, this allows a better estimate of an underlying linear trend, a better detection of significant historical supports and resistance points, and avoid finding a good window size manually.
Settings
Min : Minimum window size value
Max : Maximum window size value
Mult : Multiplicative factor for the rmse, control the channel width.
Src : Source input of the indicator
Details
The indicator displays the specific window size that maximizes the R-squared at the bottom of the lower channel.
When optimizing we want to find parameters such that they maximize or minimize a certain function, here the r-squared. The R-squared is given by 1 minus the ratio between the sum of squares (SSE) of the linear regression and the sum of squares of the mean. We know that the mean will always produce an SSE greater or equal to the one of the linear regression, so the R-squared will always be in a (0,1) range. In the case our data has a linear trend, the linear regression will have a better fit, thus having a lower SSE than the SSE of the mean, has such the ratio between the linear regression SSE and the mean SSE will be low, 1 minus this ratio will return a greater result. A lower R-squared will tell you that your linear regression produces a fit similar to the one produced by the mean. The R-squared is also given by the square of the correlation coefficient between the dependent and independent variables.
In pinescript optimization can be done by running a function inside a loop, we run the function for each setting and keep the one that produces the maximum or minimum result, however, it is not possible to do that with most built-in functions, including the function of interest, correlation , as such we must recreate a rolling correlation function that can be used inside loops, such functions are generally loops-free, this means that they are not computed using a loop in the first place, fortunately, the rolling correlation function is simply based on moving averages and standard deviations, both can be computed without using a loop by using cumulative sums, this is what is done in the code.
Note that because the R-squared is based on the SSE of the linear regression, maximizing the R-squared also minimizes the linear regression SSE, another thing that is minimized is the horizontality of the fit.
In the example above we have a total window size of 27, the script will try to find the setting that maximizes the R-squared, we must avoid every data points before the volatile bearish candle, using any of these data points will produce a poor fit, we see that the script avoid it, thus running as expected. Another interesting thing is that the best R-squared is not always associated to the lowest window size.
Note that optimization does not fix core problems in a model, with the linear regression we assume that our data set posses a linear trend, if it's not the case, then no matter how many settings you use you will still have a model that is not adapted to your data.

r2 correlation coefficientmade a quick script to compare r2 correlation coefficient, can change source and correlation component in inputs menu
example, here we can see that btc currently has a 0.85 correlation with eth vs usd when using simple moving avg on the daily (above 0.8 is positive correlation. below -0.8 is negitive correlation, and anything in between means there is no correlation)
note: if you wanted to compare with a different source like rsi, then you would need to reduce the length in the inputs menu
not an expert, i encourage doing your own research
biffy
Function : Multiple Correlation
This script was written to calculate the correlation coefficient (Adjusted R-Squared) for one dependent and two independent variables.(3-way)
Pearson correlation method was used with exponential moving averages as the correlation calculation method.
Use your source ( i use "close" generally ) as the dependent variable.
Inspired by this article : www.real-statistics.com
The Adjusted R-Squared coefficient is used as output, but the R-Squared coefficient is also available in the code.
Adjusted R-Squared is often used for multiple correlations.
It also gives better results in large samples.
Here is the article about the difference of the two coefficients : www.investopedia.com
I wrote this function to increase the efficiency of my Dow Factor I used before.
When my research is over, I will apply the 3-factor correlation to my scripts.
I hope that I will achieve more efficient indicators and oscillators and even strategies.
In this command, I gave a few variable values and plotted them as an example.
I hope this function is useful in your work.
Finally, you can use periods as mutable variables.
The function is recovered from integer loads.
Best regards. Noldo

R2-Adaptive RegressionIntroduction
I already mentioned various problems associated with the lsma, one of them being overshoots, so here i propose to use an lsma using a developed and adaptive form of 1st order polynomial to provide several improvements to the lsma. This indicator will adapt to various coefficient of determinations while also using various recursions.
More In Depth
A 1st order polynomial is in the form : y = ax + b , our indicator however will use : y = a*x + a1*x1 + (1 - (a + a1))*y , where a is the coefficient of determination of a simple lsma and a1 the coefficient of determination of an lsma who try to best fit y to the price.
In some cases the coefficient of determination or r-squared is simply the squared correlation between the input and the lsma. The r-squared can tell you if something is trending or not because its the correlation between the rough price containing noise and an estimate of the trend (lsma) . Therefore the filter give more weight to x or x1 based on their respective r-squared, when both r-squared is low the filter give more weight to its precedent output value.
Comparison
lsma and R2 with both length = 100
The result of the R2 is rougher, faster, have less overshoot than the lsma and also adapt to market conditions.
Longer/Shorter terms period can increase the error compared to the lsma because of the R2 trying to adapt to the r-squared. The R2 can also provide good fits when there is an edge, this is due to the part where the lsma fit the filter output to the input (y2)
Conclusion
I presented a new kind of lsma that adapt itself to various coefficient of determination. The indicator can reduce the sum of squares because of its ability to reduce overshoot as well as remaining stationary when price is not trending. It can be interesting to apply exponential averaging with various smoothing constant as long as you use : (1- (alpha+alpha1)) at the end.
Thanks for reading

Chande Kroll R-Squared IndexChande Kroll R-Squared Index script.
This indicator was originally developed by Tushar S. Chande and Stanley Kroll (see their book `The New Technical Trader`, Chapter 2: `Linear Regression Analysis`).
