Powell's Brain Mk.4.4 [Scalper Edition]Title: Powell's Brain Mk.4.4
Description
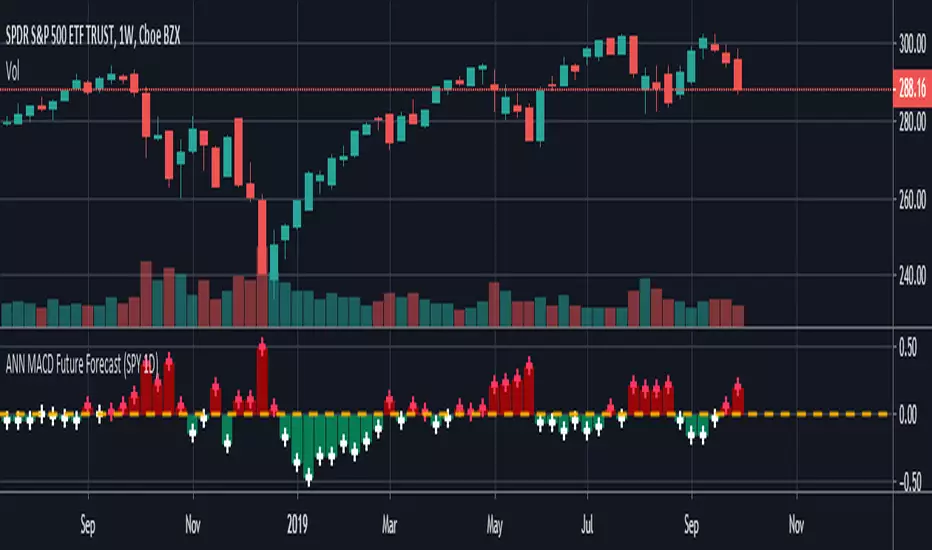
Powell's Brain is a mechanical scalping system designed for volatile assets (like SPY, QQQ, NVDA, and TSLA) on 1-minute and 5-minute timeframes.
Unlike standard indicators that spam signals at every crossover, this script uses a "Subtractive" Philosophy. It starts with a trend crossover signal and then runs it through a squad of 6 distinct filters. If any filter detects low probability (chop, low volume, weak momentum), the trade is blocked.
This is the Scalper Edition, tuned to catch V-Shape reversals while still protecting capital during sideways chop.
🧠 How It Works
The system relies on the confluence of four market forces: Momentum, Energy, Trend Strength, and AI Confirmation.
1. The Core Strategy (The Engine)
Dual EMA Crossover: Uses a Fast (9) and Slow (50) EMA to identify immediate trend changes.
Slope Detection: A trade is only considered if the EMAs are separating with sufficient velocity (0.04% slope threshold). This prevents trading when lines are flat/tangled.
2. The "No" Squad (Filters)
A signal is rejected unless it passes these checks:
Volume Gate: Volume must be at least 80% (0.8x) of the 20-period average. This filters out pre-market noise or lunch-hour apathy.
ADX Shield: The Average Directional Index must be > 20. If ADX is lower, the market is chopping, and the script forces you to sit on your hands.
Time-of-Day: By default, it targets "Prime Hours" (09:30–11:00 & 14:00–16:00 EST) to avoid the "lunchtime trap."
Cooldown: Enforces a 3-bar wait period between signals to prevent signal flickering in high-volatility zones.
3. The AI Engine (k-NN Machine Learning)
Included is a k-Nearest Neighbors (k-NN) implementation that analyzes historical RSI and Relative Volume patterns.
It compares the current market state to the last ~1,000 bars.
It calculates a "Confidence %" based on how often similar past setups resulted in a bullish or bearish move.
AI Gating: You can enable a "Strict Mode" in settings where the script will block any trade that the AI does not agree with (Confidence < 55%).
4. The Squeeze Filter (TTM Logic)
An optional filter allows you to trade only on volatility expansion (Bollinger Bands exiting Keltner Channels). This is disabled by default to allow for standard trend scalping but can be enabled for breakout hunting.
🚦 How to Use
The Signals:
Green "CALL" Label: Bullish Momentum + Volume + Trend Strength.
Red "PUT" Label: Bearish Momentum + Volume + Breakdown.
The HUD (Heads-Up Display):
Monitor the top-right panel for Market Flow, Squeeze Status, and AI Confidence.
If the AI text is Orange ("INITIALIZING"), wait for more data to load.
The Debugger:
If you see a crossover but NO signal, turn on "Show Debug Labels" in settings.
The chart will print exactly why the trade was skipped (e.g., Vol❌ means volume was too low, Slope❌ means the trend was too flat).
⚙️ Settings Guide
Strategy Core: Adjust Min EMA Separation to tune sensitivity. Higher = Fewer, safer trades. Lower = Faster entries.
Filters:
Trade with 200 EMA Trend: Keep OFF for scalping reversals. Turn ON for strict trend following.
Gate Entries with AI: Turn ON if you want the Machine Learning engine to veto low-confidence setups.
Visuals: Toggle Dark/Light themes to match your chart.
Disclaimer
This script is a tool for identifying high-probability setups based on historical data and technical analysis. It does not guarantee future performance. Always use proper risk management (Stop Losses are included in the logic visuals). In less words DON'T BE AN IDIOT.
By FallenAngel666
Machine_learning

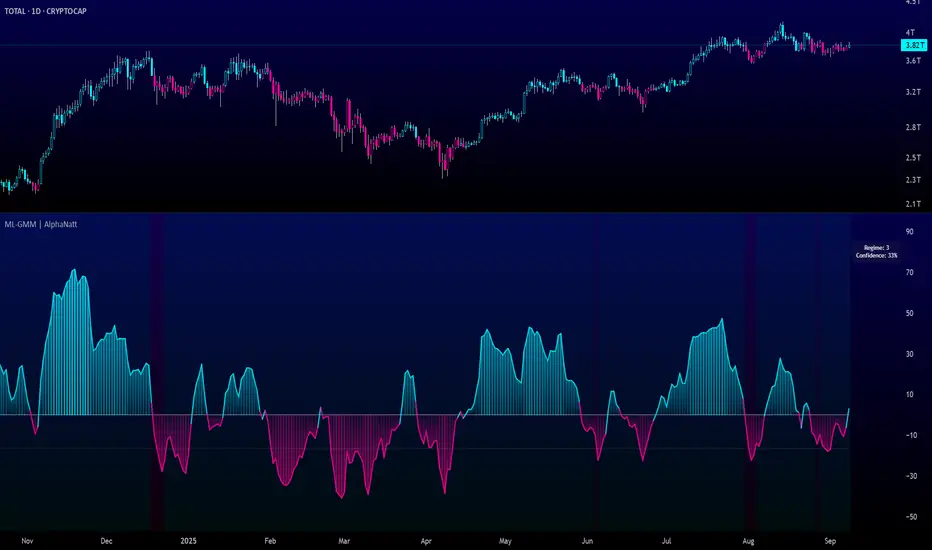
Machine Learning Gaussian Mixture Model | AlphaNattMachine Learning Gaussian Mixture Model | AlphaNatt
A revolutionary oscillator that uses Gaussian Mixture Models (GMM) with unsupervised machine learning to identify market regimes and automatically adapt momentum calculations - bringing statistical pattern recognition techniques to trading.
"Markets don't follow a single distribution - they're a mixture of different regimes. This oscillator identifies which regime we're in and adapts accordingly."
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
🤖 THE MACHINE LEARNING
Gaussian Mixture Models (GMM):
Unlike K-means clustering which assigns hard boundaries, GMM uses probabilistic clustering :
Models data as coming from multiple Gaussian distributions
Each market regime is a different Gaussian component
Provides probability of belonging to each regime
More sophisticated than simple clustering
Expectation-Maximization Algorithm:
The indicator continuously learns and adapts using the E-M algorithm:
E-step: Calculate probability of current market belonging to each regime
M-step: Update regime parameters based on new data
Continuous learning without repainting
Adapts to changing market conditions
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
🎯 THREE MARKET REGIMES
The GMM identifies three distinct market states:
Regime 1 - Low Volatility:
Quiet, ranging markets
Uses RSI-based momentum calculation
Reduces false signals in choppy conditions
Background: Pink tint
Regime 2 - Normal Market:
Standard trending conditions
Uses Rate of Change momentum
Balanced sensitivity
Background: Gray tint
Regime 3 - High Volatility:
Strong trends or volatility events
Uses Z-score based momentum
Captures extreme moves
Background: Cyan tint
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
💡 KEY INNOVATIONS
1. Probabilistic Regime Detection:
Instead of binary regime assignment, provides probabilities:
30% Regime 1, 60% Regime 2, 10% Regime 3
Smooth transitions between regimes
No sudden indicator jumps
2. Weighted Momentum Calculation:
Combines three different momentum formulas
Weights based on regime probabilities
Automatically adapts to market conditions
3. Confidence Indicator:
Shows how certain the model is (white line)
High confidence = strong regime identification
Low confidence = transitional market state
Line transparency changes with confidence
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
⚙️ PARAMETER OPTIMIZATION
Training Period (50-500):
50-100: Quick adaptation to recent conditions
100: Balanced (default)
200-500: Stable regime identification
Number of Components (2-5):
2: Simple bull/bear regimes
3: Low/Normal/High volatility (default)
4-5: More granular regime detection
Learning Rate (0.1-1.0):
0.1-0.3: Slow, stable learning
0.3: Balanced (default)
0.5-1.0: Fast adaptation
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
📊 TRADING STRATEGIES
Visual Signals:
Cyan gradient: Bullish momentum
Magenta gradient: Bearish momentum
Background color: Current regime
Confidence line: Model certainty
1. Regime-Based Trading:
Regime 1 (pink): Expect mean reversion
Regime 2 (gray): Standard trend following
Regime 3 (cyan): Strong momentum trades
2. Confidence-Filtered Signals:
Only trade when confidence > 70%
High confidence = clearer market state
Avoid transitions (low confidence)
3. Adaptive Position Sizing:
Regime 1: Smaller positions (choppy)
Regime 2: Normal positions
Regime 3: Larger positions (trending)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
🚀 ADVANTAGES OVER OTHER ML INDICATORS
vs K-Means Clustering:
Soft clustering (probabilities) vs hard boundaries
Captures uncertainty and transitions
More mathematically robust
vs KNN (K-Nearest Neighbors):
Unsupervised learning (no historical labels needed)
Continuous adaptation
Lower computational complexity
vs Neural Networks:
Interpretable (know what each regime means)
No overfitting issues
Works with limited data
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
📈 PERFORMANCE CHARACTERISTICS
Best Market Conditions:
Markets with clear regime shifts
Volatile to trending transitions
Multi-timeframe analysis
Cryptocurrency markets (high regime variation)
Key Strengths:
Automatically adapts to market changes
No manual parameter adjustment needed
Smooth transitions between regimes
Probabilistic confidence measure
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
🔬 TECHNICAL BACKGROUND
Gaussian Mixture Models are used extensively in:
Speech recognition (Google Assistant)
Computer vision (facial recognition)
Astronomy (galaxy classification)
Genomics (gene expression analysis)
Finance (risk modeling at investment banks)
The E-M algorithm was developed at Stanford in 1977 and is one of the most important algorithms in unsupervised machine learning.
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
💡 PRO TIPS
Watch regime transitions: Best opportunities often occur when regimes change
Combine with volume: High volume + regime change = strong signal
Use confidence filter: Avoid low confidence periods
Multi-timeframe: Compare regimes across timeframes
Adjust position size: Scale based on identified regime
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
⚠️ IMPORTANT NOTES
Machine learning adapts but doesn't predict the future
Best used with other confirmation indicators
Allow time for model to learn (100+ bars)
Not financial advice - educational purposes
Backtest thoroughly on your instruments
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
🏆 CONCLUSION
The GMM Momentum Oscillator brings institutional-grade machine learning to retail trading. By identifying market regimes probabilistically and adapting momentum calculations accordingly, it provides:
Automatic adaptation to market conditions
Clear regime identification with confidence levels
Smooth, professional signal generation
True unsupervised machine learning
This isn't just another indicator with "ML" in the name - it's a genuine implementation of Gaussian Mixture Models with the Expectation-Maximization algorithm, the same technology used in:
Google's speech recognition
Tesla's computer vision
NASA's data analysis
Wall Street risk models
"Let the machine learn the market regimes. Trade with statistical confidence."
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Developed by AlphaNatt | Machine Learning Trading Systems
Version: 1.0
Algorithm: Gaussian Mixture Model with E-M
Classification: Unsupervised Learning Oscillator
Not financial advice. Always DYOR.
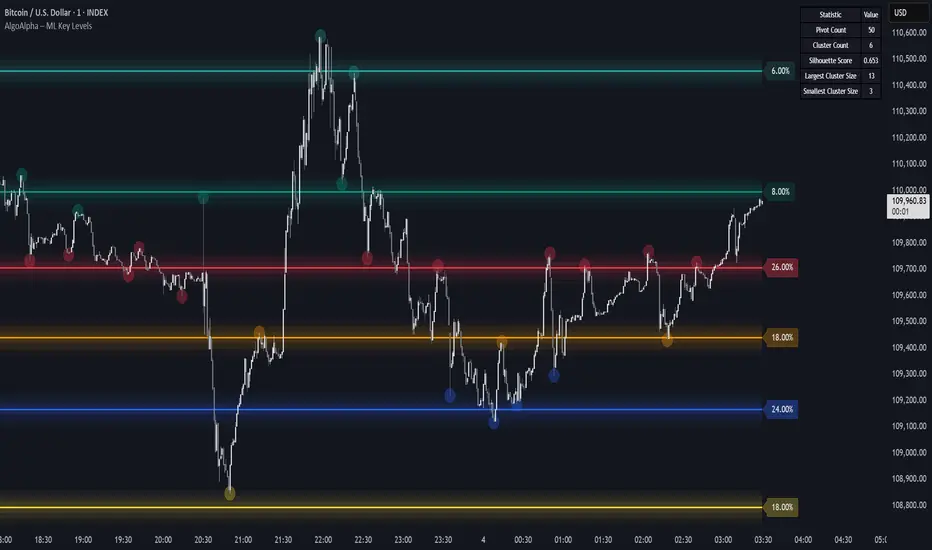
Machine Learning Key Levels [AlgoAlpha]🟠 OVERVIEW
This script plots Machine Learning Key Levels on your chart by detecting historical pivot points and grouping them using agglomerative clustering to highlight price levels with the most past reactions. It combines a pivot detection, hierarchical clustering logic, and an optional silhouette method to automatically select the optimal number of key levels, giving you an adaptive way to visualize price zones where activity concentrated over time.
🟠 CONCEPTS
Agglomerative clustering is a bottom-up method that starts by treating each pivot as its own cluster, then repeatedly merges the two closest clusters based on the average distance between their members until only the desired number of clusters remain. This process creates a hierarchy of groupings that can flexibly describe patterns in how price reacts around certain levels. This offers an advantage over K-means clustering, since the number of clusters does not need to be predefined. In this script, it uses an average linkage approach, where distance between clusters is computed as the average pairwise distance of all contained points.
The script finds pivot highs and lows over a set lookback period and saves them in a buffer controlled by the Pivot Memory setting. When there are at least two pivots, it groups them using agglomerative clustering: it starts with each pivot as its own group and keeps merging the closest pairs based on their average distance until the desired number of clusters is left. This number can be fixed or chosen automatically with the silhouette method, which checks how well each point fits in its cluster compared to others (higher scores mean cleaner separation). Once clustering finishes, the script takes the average price of each cluster to create key levels, sorts them, and draws horizontal lines with labels and colors showing their strength. A metrics table can also display details about the clusters to help you understand how the levels were calculated.
🟠 FEATURES
Agglomerative clustering engine with average linkage to merge pivots into level groups.
Dynamic lines showing each cluster’s price level for clarity.
Labels indicating level strength either as percent of all pivots or raw counts.
A metrics table displaying pivot count, cluster count, silhouette score, and cluster size data.
Optional silhouette-based auto-selection of cluster count to adaptively find the best fit.
🟠 USAGE
Add the indicator to any chart. Choose how far back to detect pivots using Pivot Length and set Pivot Memory to control how many are kept for clustering (more pivots give smoother levels but can slow performance). If you want the script to pick the number of levels automatically, enable Auto No. Levels ; otherwise, set Number of Levels . The colored horizontal lines represent the calculated key levels, and circles show where pivots occurred colored by which cluster they belong to. The labels beside each level indicate its strength, so you can see which levels are supported by more pivots. If Show Metrics Table is enabled, you will see statistics about the clustering in the corner you selected. Use this tool to spot areas where price often reacts and to plan entries or exits around levels that have been significant over time. Adjust settings to better match volatility and history depth of your instrument.
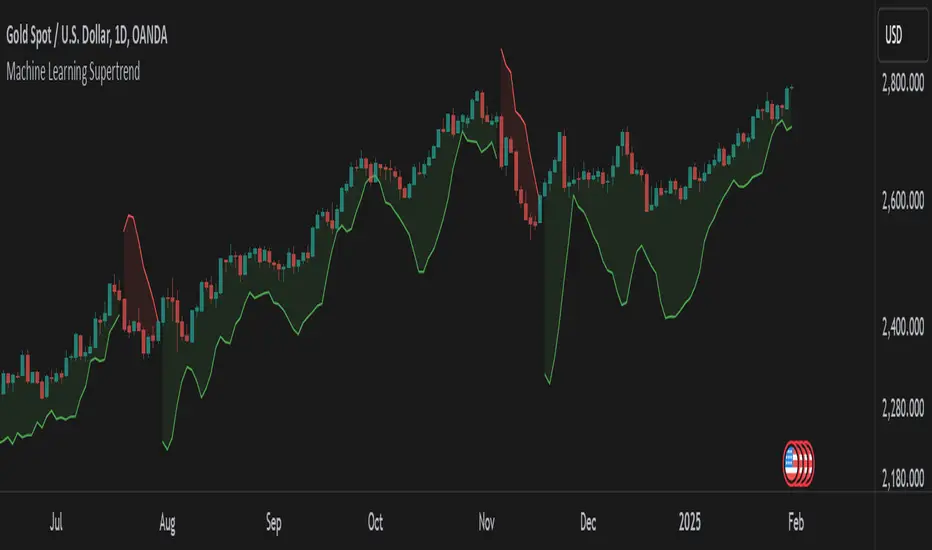
Machine Learning SupertrendThe Machine Learning Supertrend is an advanced trend-following indicator that enhances the traditional Supertrend with Gaussian Process Regression (GPR) and kernel-based learning. Unlike conventional methods that rely purely on historical ATR values, this indicator integrates machine learning techniques to dynamically estimate volatility and forecast future price movements, resulting in a more adaptive and robust trend detection system.
At the core of this indicator lies Gaussian Process Regression (GPR), which utilizes a Radial Basis Function (RBF) kernel to model price distributions and anticipate future trends. Instead of simply looking at past price action, it constructs a kernel matrix, enabling a probabilistic approach to price forecasting. This allows the indicator to not only detect current trends but also project potential trend reversals with greater accuracy.
By applying machine learning to ATR estimation, the ML Supertrend dynamically adjusts its thresholds based on predicted values rather than a fixed multiplier. This makes the trend signals more responsive to market conditions, reducing false signals and minimizing whipsaws often seen with traditional Supertrend indicators. The upper and lower bands are no longer static but evolve based on the underlying price structure, improving the reliability of trend shifts.
When the price crosses these adaptive levels, the indicator detects a trend change and plots it accordingly. Green signifies a bullish trend, while red indicates a bearish one. Alerts can also be triggered when the trend shifts, allowing traders to react quickly to potential reversals.
What makes this approach powerful is its ability to adapt to different market conditions. Traditional ATR-based methods use fixed parameters that might not always be optimal, whereas this ML-driven Supertrend continuously refines its estimations based on real-time data. The result is a more intelligent, less lagging, and highly adaptive trend-following tool.
This indicator is particularly useful for traders looking to enhance trend-following strategies with AI-driven insights. It reduces noise, improves signal reliability, and even offers a degree of trend forecasting, making it ideal for those who want a more advanced and dynamic alternative to standard Supertrend indicators.
This indicator is provided for educational and informational purposes only. It does not constitute financial advice, and past performance is not indicative of future results. Trading involves risk, and users should conduct their own research and use proper risk management before making investment decisions.
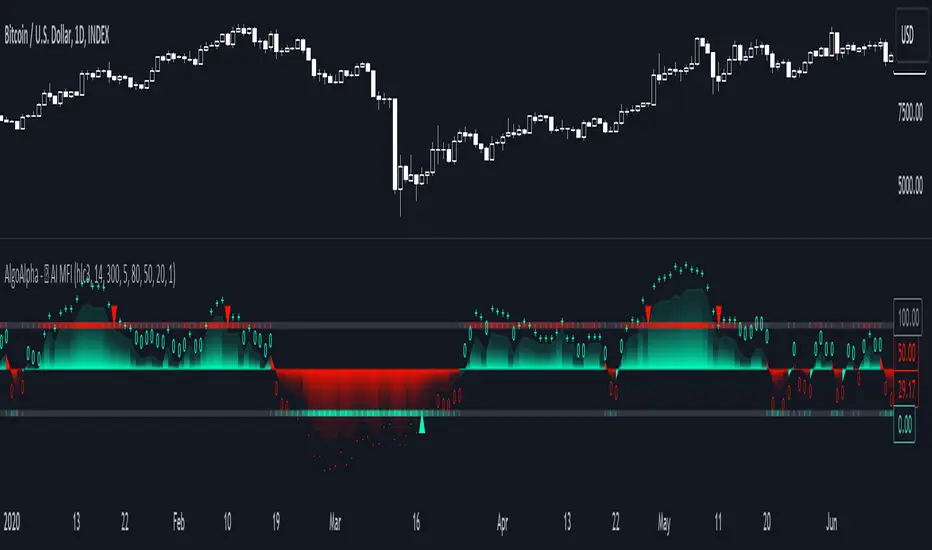
AI Adaptive Money Flow Index (Clustering) [AlgoAlpha]🌟🚀 Dive into the future of trading with our latest innovation: the AI Adaptive Money Flow Index by AlgoAlpha Indicator! 🚀🌟
Developed with the cutting-edge power of Machine Learning, this indicator is designed to revolutionize the way you view market dynamics. 🤖💹 With its unique blend of traditional Money Flow Index (MFI) analysis and advanced k-means clustering, it adapts to market conditions like never before.
Key Features:
📊 Adaptive MFI Analysis: Utilizes the classic MFI formula with a twist, adjusting its parameters based on AI-driven clustering.
🧠 AI-Driven Clustering: Applies k-means clustering to identify and adapt to market states, optimizing the MFI for current conditions.
🎨 Customizable Appearance: Offers adjustable settings for overbought, neutral, and oversold levels, as well as colors for uptrends and downtrends.
🔔 Alerts for Key Market Movements: Set alerts for trend reversals, overbought, and oversold conditions, ensuring you never miss a trading opportunity.
Quick Guide to Using the AI Adaptive MFI (Clustering):
🛠 Customize the Indicator: Customize settings like MFI source, length, and k-means clustering parameters to suit your analysis.
📈 Market Analysis: Monitor the dynamically adjusted overbought, neutral, and oversold levels for insights into market conditions. Watch for classification symbols ("+", "0", "-") for immediate understanding of the current market state. Look out for reversal signals (▲, ▼) to get potential entry points.
🔔 Set Alerts: Utilize the built-in alert conditions for trend changes, overbought, and oversold signals to stay ahead, even when you're not actively monitoring the charts.
How It Works:
The AI Adaptive Money Flow Index employs the k-means clustering machine learning algorithm to refine the traditional Money Flow Index, dynamically adjusting overbought, neutral, and oversold levels based on market conditions. This method analyzes historical MFI values, grouping them into initial clusters using the traditional MFI's overbought, oversold and neutral levels, and then finding the mean of each cluster, which represent the new market states thresholds. This adaptive approach ensures the indicator's sensitivity in real-time, offering a nuanced understanding of market trend and volume analysis.
By recalibrating MFI thresholds for each new data bar, the AI Adaptive MFI intelligently conforms to changing market dynamics. This process, assessing past periods to adjust the indicator's parameters, provides traders with insights finely tuned to recent market behavior. Such innovation enhances decision-making, leveraging the latest data to inform trading strategies. 🌐💥
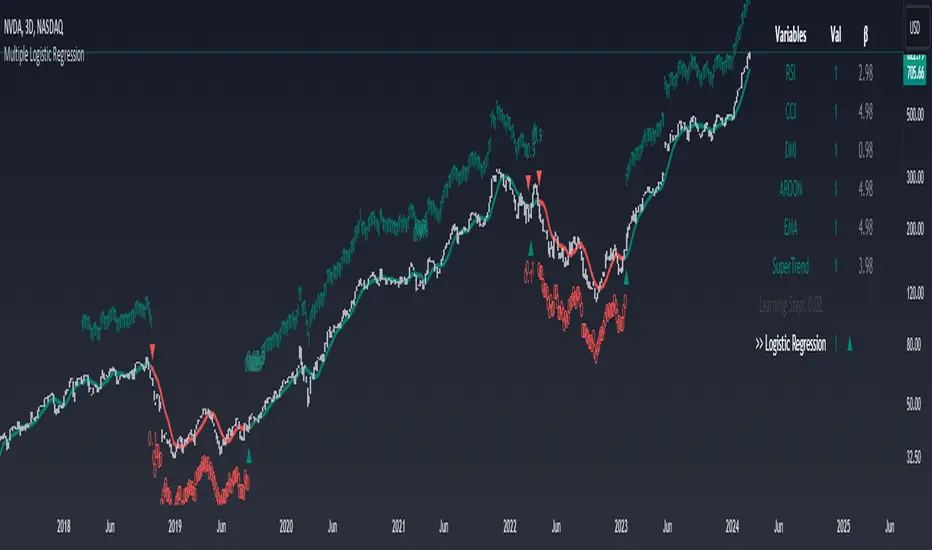
Machine Learning: Multiple Logistic Regression
Multiple Logistic Regression Indicator
The Logistic Regression Indicator for TradingView is a versatile tool that employs multiple logistic regression based on various technical indicators to generate potential buy and sell signals. By utilizing key indicators such as RSI, CCI, DMI, Aroon, EMA, and SuperTrend, the indicator aims to provide a systematic approach to decision-making in financial markets.
How It Works:
Technical Indicators:
The script uses multiple technical indicators such as RSI, CCI, DMI, Aroon, EMA, and SuperTrend as input variables for the logistic regression model.
These indicators are normalized to create categorical variables, providing a consistent scale for the model.
Logistic Regression:
The logistic regression function is applied to the normalized input variables (x1 to x6) with user-defined coefficients (b0 to b6).
The logistic regression model predicts the probability of a binary outcome, with values closer to 1 indicating a bullish signal and values closer to 0 indicating a bearish signal.
Loss Function (Cross-Entropy Loss):
The cross-entropy loss function is calculated to quantify the difference between the predicted probability and the actual outcome.
The goal is to minimize this loss, which essentially measures the model's accuracy.
// Error Function (cross-entropy loss)
loss(y, p) =>
-y * math.log(p) - (1 - y) * math.log(1 - p)
// y - depended variable
// p - multiple logistic regression
Gradient Descent:
Gradient descent is an optimization algorithm used to minimize the loss function by adjusting the weights of the logistic regression model.
The script iteratively updates the weights (b1 to b6) based on the negative gradient of the loss function with respect to each weight.
// Adjusting model weights using gradient descent
b1 -= lr * (p + loss) * x1
b2 -= lr * (p + loss) * x2
b3 -= lr * (p + loss) * x3
b4 -= lr * (p + loss) * x4
b5 -= lr * (p + loss) * x5
b6 -= lr * (p + loss) * x6
// lr - learning rate or step of learning
// p - multiple logistic regression
// x_n - variables
Learning Rate:
The learning rate (lr) determines the step size in the weight adjustment process. It prevents the algorithm from overshooting the minimum of the loss function.
Users can set the learning rate to control the speed and stability of the optimization process.
Visualization:
The script visualizes the output of the logistic regression model by coloring the SMA.
Arrows are plotted at crossover and crossunder points, indicating potential buy and sell signals.
Lables are showing logistic regression values from 1 to 0 above and below bars
Table Display:
A table is displayed on the chart, providing real-time information about the input variables, their values, and the learned coefficients.
This allows traders to monitor the model's interpretation of the technical indicators and observe how the coefficients change over time.
How to Use:
Parameter Adjustment:
Users can adjust the length of technical indicators (rsi_length, cci_length, etc.) and the Z score length based on their preference and market characteristics.
Set the initial values for the regression coefficients (b0 to b6) and the learning rate (lr) according to your trading strategy.
Signal Interpretation:
Buy signals are indicated by an upward arrow (▲), and sell signals are indicated by a downward arrow (▼).
The color-coded SMA provides a visual representation of the logistic regression output by color.
Table Information:
Monitor the table for real-time information on the input variables, their values, and the learned coefficients.
Keep an eye on the learning rate to ensure a balance between model adjustment speed and stability.
Backtesting and Validation:
Before using the script in live trading, conduct thorough backtesting to evaluate its performance under different market conditions.
Validate the model against historical data to ensure its reliability.
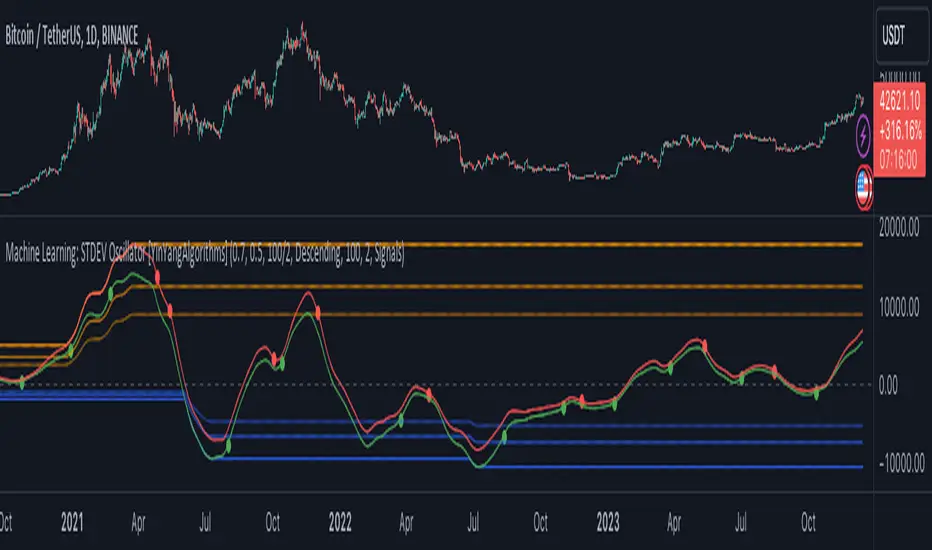
Machine Learning: STDEV Oscillator [YinYangAlgorithms]This Indicator aims to fill a gap within traditional Standard Deviation Analysis. Rather than its usual applications, this Indicator focuses on applying Standard Deviation within an Oscillator and likewise applying a Machine Learning approach to it. By doing so, we may hope to achieve an Adaptive Oscillator which can help display when the price is deviating from its standard movement. This Indicator may help display both when the price is Overbought or Underbought, and likewise, where the price may face Support and Resistance. The reason for this is that rather than simply plotting a Machine Learning Standard Deviation (STDEV), we instead create a High and a Low variant of STDEV, and then use its Highest and Lowest values calculated within another Deviation to create Deviation Zones. These zones may help to display these Support and Resistance locations; and likewise may help to show if the price is Overbought or Oversold based on its placement within these zones. This Oscillator may also help display Momentum when the High and/or Low STDEV crosses the midline (0). Lastly, this Oscillator may also be useful for seeing the spacing between the High and Low of the STDEV; large spacing may represent volatility within the STDEV which may be helpful for seeing when there is Momentum in the form of volatility.
Tutorial:
Above is an example of how this Indicator looks on BTC/USDT 1 Day. As you may see, when the price has parabolic movement, so does the STDEV. This is due to this price movement deviating from the mean of the data. Therefore when these parabolic movements occur, we create the Deviation Zones accordingly, in hopes that it may help to project future Support and Resistance locations as well as helping to display when the price is Overbought and Oversold.
If we zoom in a little bit, you may notice that the Support Zone (Blue) is smaller than the Resistance Zone (Orange). This is simply because during the last Bull Market there was more parabolic price deviation than there was during the Bear Market. You may see this if you refer to their values; the Resistance Zone goes to ~18k whereas the Support Zone is ~10.5k. This is completely normal and the way it is supposed to work. Due to the nature of how STDEV works, this Oscillator doesn’t use a 1:1 ratio and instead can develop and expand as exponential price action occurs.
The Neutral (0) line may also act as a Support and Resistance location. In the example above we can see how when the STDEV is below it, it acts as Resistance; and when it’s above it, it acts as Support.
This Neutral line may also provide us with insight as towards the momentum within the market and when it has shifted. When the STDEV is below the Neutral line, the market may be considered Bearish. When the STDEV is above the Neutral line, the market may be considered Bullish.
The Red Line represents the STDEV’s High and the Green Line represents the STDEV’s Low. When the STDEV’s High and Low get tight and close together, this may represent there is currently Low Volatility in the market. Low Volatility may cause consolidation to occur, however it also leaves room for expansion.
However, when the STDEV’s High and Low are quite spaced apart, this may represent High levels of Volatility in the market. This may mean the market is more prone to parabolic movements and expansion.
We will conclude our Tutorial here. Hopefully this has given you some insight into how applying Machine Learning to a High and Low STDEV then creating Deviation Zones based on it may help project when the Momentum of the Market is Bullish or Bearish; likewise when the price is Overbought or Oversold; and lastly where the price may face Support and Resistance in the form of STDEV.
If you have any questions, comments, ideas or concerns please don't hesitate to contact us.
HAPPY TRADING!
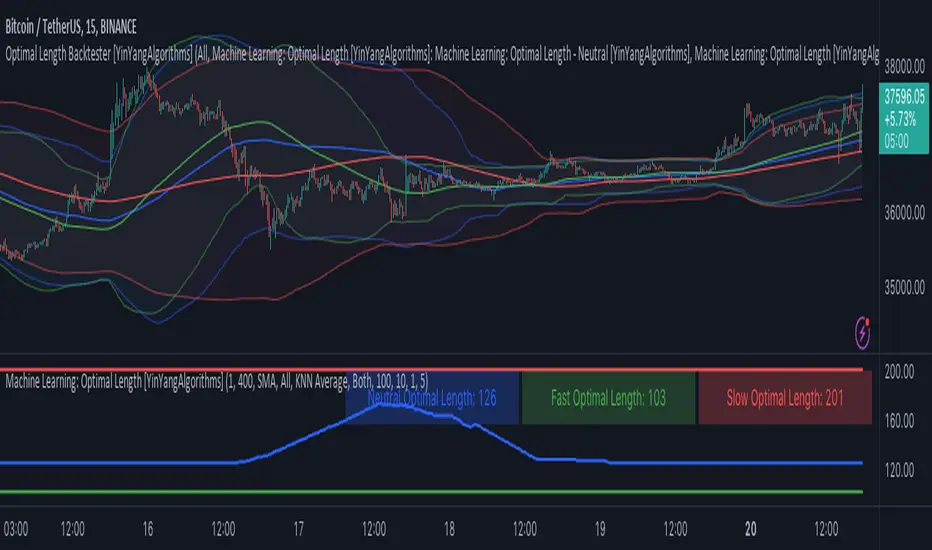
Machine Learning: Optimal Length [YinYangAlgorithms]This Indicator aims to solve an issue that most others face; static lengths. This Indicator will scan lengths from the Min to Max setting (1 - 400 by default) to calculate which is the most Optimal Length in the current market condition. Almost every Indicator uses a length in some part of their calculation, and this length is usually adjustable via the Settings; however it is generally a static fixed length. Static non changing lengths may not always produce optimal results. As market conditions change generally the optimal length will too. For this reason we have created this indicator.
This Indicator will create a Neutral (Min - Max Length), Fast (Min - Mid Length ((Max - Min) / 2)) and Slow (Mid Length ((Max - Min) / 2) - Max Length). This allows you to understand which the Optimal Fast, Slow and Neutral lengths are within the given Mix and Max length settings.
This Indicator then plots these Optimal Lengths as an Oscillator which can then be used within ANOTHER Indicator as a Source within its Settings. Stand alone this Indicator may not prove all that useful, however when its Lengths are inputted into another Indicator it may prove very useful. This allows other Indicators to use the Optimal Length within its calculations from the Settings rather than relying on simply a fixed length. Unfortunately this results in users needing to manually plug the Optimal Length plots into the second Indicator; but it also allows for endless possibilities with applying Machine Learning Optimal Lengths within both Traditional and Non-Traditional Indicators and may give other Pine Coders an easy and effective way to add Machine Learning auto adjustable lengths within their already created Indicators.
The beautiful part about this Indicator is that aside from inputting the Optimal Length Plot into another Indicator, there is no manual updating needed. When the Optimal Length changes, the change will automatically reflect in the other Indicator without the need for you to manually adjust its length. This may be very useful with both time preservation, as well as if there is an automated strategy based upon said Indicator that now won’t need manual intervention.
Tutorial:
By default this is what the Machine Learning: Optimal Length Indicator looks like. It is simply a way of both Displaying and Plotting our current Optimal Length so that we may then use it as a source within ANOTHER Indicator. This will allow the automation of an Optimal Length to be updated, rather than needing any manual input from yourself (aside from set up).
For instance if you set the start length to 1 and the end length to 400 (default settings), it will scan to find the optimal Length setting between 1 and 400. This features 3 types of lengths:
Fast (Green Line): 1-199 (from start length to half way of total)
Slow (Red Line): 200 - 400 (mid way to end length)
Neutral (Blue Line): 1 - 400 (start to end length)
By breaking down the Optimal Length detection into these 3 different types, we can see how the Optimal Length compares and changes based on the lengths allotted to them and how performance changes.
For instance, you may notice that both the Fast and Slow Optimal Length didn’t change much in the example above; however the Neutral Optimal Length changed quite a bit. This is due to the fact that the Neutral is inclusive of all lengths available and may be considered the more accurate due to that. However, this doesn’t mean the Fast and Slow lengths aren’t important and should be used. They may be useful for seeing how something fairs in a Fast and Slow standpoint.
If you change your TimeFrame from 15 minute to 1 Day, you’ll notice that the Optimal Lengths gravitate towards their upper bounds:
199 is max for Fast, it’s at 195
400 is max for Slow, its at 393
400 is max for Neutral, its at 399
The Optimal Length may move up to its upper bounds on Higher Time Frames because there is a lot of price action and long term data being displayed. This may lead to higher lengths performing better in a profitability standpoint since its data is based on so far back and such drastic price movements.
Below we’re going to go through a few examples, including the code so you may reproduce the example and have an understanding of how versatile Inputting an Optimal Length as a source may be within Traditional Indicators.
Adding the Machine Learning: Optimal Length to another Indicator:
You may add the Optimal Length to another Indicator as shown in the example above. In the example we are adding the ‘Machine Learning: Optimal Length - Neutral’ to our Neutral Length within the Settings. The external Indicator needs to have the ability to input the Optimal Length as a Source, this way it can automatically change within the external Indicator when the Optimal Length Indicator changes its Optimal Length.
Please note you may get an error within an external Indicator that accepts the Length as a Source if you don’t select the Machine Learning: Optimal Length. For instance, if you use ‘Close’ within BTC/USDT the length used would be ~36,000. This length is too long and will throw an error.
For this reason, we will ensure the Max Length that may be used is 1000.
Please note, on lower Time Frames you may need to adjust the Max Length. For instance if 20k bar data is used, the Max Length ‘may’ fail to load when going by default Min: 1 and Max: 400. Generally with most pairs it will load if your TradingView subscription is Premium or greater; however if it is less there is a chance it may fail. If it fails for you too often please lower the Max Length Amount; or send us a message we can look into a fix for this.
*** If it fails to load, please try removing the external Indicator and re-adding it and adding the Lengths back as a Source within the Settings. Sometimes it fails, but re-adding may fix it. If it keeps failing afterwards, reduce the Max Length Amount as mentioned above. ***
Simple Moving Average:
In this example above have the Fast, Slow and Neutral Optimal Length formatted as a Slow Moving Average. The first example is on the 15 minute Time Frame and the second is on the 1 Day Time Frame, demonstrating how the length changes based on the Time Frame and the effects it may have.
Here is the code for the example Indicator shown above. This example shows how you may use the Optimal Length as a Source and then use that Optimal Length and plot it as a Simple Moving Average:
//@version=5
indicator("Optimal Length - Backtesting - MA", overlay=true, max_bars_back=5000)
outputType = input.string("All", "Output Type", options= )
lengthSource = input.source(close, "Neutral Length")
lengthSource_fast = input.source(close, "Fast Length")
lengthSource_slow = input.source(close, "Slow Length")
showNeutral = outputType == "Neutral" or outputType == "Fast + Neutral" or outputType == "Slow + Neutral" or outputType == "All"
showFast = outputType == "Fast" or outputType == "Fast + Neutral" or outputType == "Fast + Slow" or outputType == "All"
showSlow = outputType == "Slow" or outputType == "Slow + Neutral" or outputType == "Fast + Slow" or outputType == "All"
//Neutral
optimalLength = math.min(math.max(math.round(lengthSource), 1), 1000)
optimalMA = ta.sma(close, optimalLength)
//Fast
optimalLength_fast = math.min(math.max(math.round(lengthSource_fast), 1), 1000)
optimalMA_fast = ta.sma(close, optimalLength_fast)
//Slow
optimalLength_slow = math.min(math.max(math.round(lengthSource_slow), 1), 1000)
optimalMA_slow = ta.sma(close, optimalLength_slow)
plot(showNeutral ? optimalMA : na, color=color.blue)
plot(showFast ? optimalMA_fast : na, color=color.green)
plot(showSlow ? optimalMA_slow : na, color=color.red)
Bollinger Bands:
In the two examples above for Bollinger Bands we have first the 15 Minute Time Frame and then the 1 Day Time Frame. As described above in ‘Adding the Machine Learning: Optimal Length to another Indicator’ sometimes it may fail to load, for this reason in the 15 Minute it was reduced to a max of 300 Length.
Bollinger Bands are a way to see a Simple Moving Average (SMA) that then uses Standard Deviation to identify how much deviation has occurred. This Deviation is than Added and Subtracted from the SMA to create the Bollinger Bands which help Identify possible movement zones that are ‘within range’. This may mean that the price may face Support / Resistance when it reaches the Outer / Inner bounds of the Bollinger Bands. Likewise, it may mean the Price is ‘Overbought’ when outside and above or ‘Underbought’ when outside and below the Bollinger Bands.
By applying All 3 different types of Optimal Lengths towards a Traditional Bollinger Band calculation we may hope to see different ranges of Bollinger Bands and how different lookback lengths may imply possible movement ranges on both a Short Term, Long Term and Neutral perspective. By seeing these possible ranges you may have the ability to identify more levels of Support and Resistance over different lengths and Trading Styles.
Below is the code for the Bollinger Bands example above:
//@version=5
indicator("Optimal Length - Backtesting - Bollinger Bands", overlay=true, max_bars_back=5000)
outputType = input.string("All", "Output Type", options= )
lengthSource = input.source(close, "Neutral Length")
lengthSource_fast = input.source(close, "Fast Length")
lengthSource_slow = input.source(close, "Slow Length")
showNeutral = outputType == "Neutral" or outputType == "Fast + Neutral" or outputType == "Slow + Neutral" or outputType == "All"
showFast = outputType == "Fast" or outputType == "Fast + Neutral" or outputType == "Fast + Slow" or outputType == "All"
showSlow = outputType == "Slow" or outputType == "Slow + Neutral" or outputType == "Fast + Slow" or outputType == "All"
mult = 2.0
src = close
neutralColor = color.blue
slowColor = color.red
fastColor = color.green
//Neutral
optimalLength = math.min(math.max(math.round(lengthSource), 1), 1000)
optimalMA = ta.sma(close, optimalLength)
//Fast
optimalLength_fast = math.min(math.max(math.round(lengthSource_fast), 1), 1000)
optimalMA_fast = ta.sma(close, optimalLength_fast)
//Slow
optimalLength_slow = math.min(math.max(math.round(lengthSource_slow), 1), 1000)
optimalMA_slow = ta.sma(close, optimalLength_slow)
//Neutral Bollinger Bands
dev = mult * ta.stdev(src, math.round(optimalLength))
upper = optimalMA + dev
lower = optimalMA - dev
plot(showNeutral ? optimalMA : na, "Neutral Basis", color=color.new(neutralColor, 0))
p1 = plot(showNeutral ? upper : na, "Neutral Upper", color=color.new(neutralColor, 50))
p2 = plot(showNeutral ? lower : na, "Neutral Lower", color=color.new(neutralColor, 50))
fill(p1, p2, title = "Neutral Background", color=color.new(neutralColor, 96))
//Slow Bollinger Bands
dev_slow = mult * ta.stdev(src, math.round(optimalLength_slow))
upper_slow = optimalMA_slow + dev_slow
lower_slow = optimalMA_slow - dev_slow
plot(showFast ? optimalMA_slow : na, "Slow Basis", color=color.new(slowColor, 0))
p1_slow = plot(showFast ? upper_slow : na, "Slow Upper", color=color.new(slowColor, 50))
p2_slow = plot(showFast ? lower_slow : na, "Slow Lower", color=color.new(slowColor, 50))
fill(p1_slow, p2_slow, title = "Slow Background", color=color.new(slowColor, 96))
//Fast Bollinger Bands
dev_fast = mult * ta.stdev(src, math.round(optimalLength_fast))
upper_fast = optimalMA_fast + dev_fast
lower_fast = optimalMA_fast - dev_fast
plot(showSlow ? optimalMA_fast : na, "Fast Basis", color=color.new(fastColor, 0))
p1_fast = plot(showSlow ? upper_fast : na, "Fast Upper", color=color.new(fastColor, 50))
p2_fast = plot(showSlow ? lower_fast : na, "Fast Lower", color=color.new(fastColor, 50))
fill(p1_fast, p2_fast, title = "Fast Background", color=color.new(fastColor, 96))
Donchian Channels:
Above you’ll see two examples of Machine Learning: Optimal Length applied to Donchian Channels. These are displayed with both the 15 Minute Time Frame and the 1 Day Time Frame.
Donchian Channels are a way of seeing potential Support and Resistance within a given lookback length. They are a way of withholding the High’s and Low’s of a specific lookback length and looking for deviation within this length. By applying our Fast, Slow and Neutral Machine Learning: Optimal Length to these Donchian Channels way may hope to achieve a viable range of High’s and Low’s that one may use to Identify Support and Resistance locations for different ranges of Optimal Lengths and likewise potentially different Trading Strategies.
The code to reproduce these Donchian Channels as displayed above is so:
//@version=5
indicator("Optimal Length - Backtesting - Donchian Channels", overlay=true, max_bars_back=5000)
outputType = input.string("All", "Output Type", options= )
lengthSource = input.source(close, "Neutral Length")
lengthSource_fast = input.source(close, "Fast Length")
lengthSource_slow = input.source(close, "Slow Length")
showNeutral = outputType == "Neutral" or outputType == "Fast + Neutral" or outputType == "Slow + Neutral" or outputType == "All"
showFast = outputType == "Fast" or outputType == "Fast + Neutral" or outputType == "Fast + Slow" or outputType == "All"
showSlow = outputType == "Slow" or outputType == "Slow + Neutral" or outputType == "Fast + Slow" or outputType == "All"
mult = 2.0
src = close
neutralColor = color.blue
slowColor = color.red
fastColor = color.green
//Neutral
optimalLength = math.min(math.max(math.round(lengthSource), 1), 1000)
optimalMA = ta.sma(close, optimalLength)
//Fast
optimalLength_fast = math.min(math.max(math.round(lengthSource_fast), 1), 1000)
optimalMA_fast = ta.sma(close, optimalLength_fast)
//Slow
optimalLength_slow = math.min(math.max(math.round(lengthSource_slow), 1), 1000)
optimalMA_slow = ta.sma(close, optimalLength_slow)
//Neutral Donchian Channels
lower_dc = ta.lowest(optimalLength)
upper_dc = ta.highest(optimalLength)
basis_dc = math.avg(upper_dc, lower_dc)
plot(showNeutral ? basis_dc : na, "Donchain Channel - Neutral Basis", color=color.new(neutralColor, 0))
u = plot(showNeutral ? upper_dc : na, "Donchain Channel - Neutral Upper", color=color.new(neutralColor, 50))
l = plot(showNeutral ? lower_dc : na, "Donchain Channel - Neutral Lower", color=color.new(neutralColor, 50))
fill(u, l, color=color.new(neutralColor, 96), title = "Donchain Channel - Neutral Background")
//Fast Donchian Channels
lower_dc_fast = ta.lowest(optimalLength_fast)
upper_dc_fast = ta.highest(optimalLength_fast)
basis_dc_fast = math.avg(upper_dc_fast, lower_dc_fast)
plot(showFast ? basis_dc_fast : na, "Donchain Channel - Fast Neutral Basis", color=color.new(fastColor, 0))
u_fast = plot(showFast ? upper_dc_fast : na, "Donchain Channel - Fast Upper", color=color.new(fastColor, 50))
l_fast = plot(showFast ? lower_dc_fast : na, "Donchain Channel - Fast Lower", color=color.new(fastColor, 50))
fill(u_fast, l_fast, color=color.new(fastColor, 96), title = "Donchain Channel - Fast Background")
//Slow Donchian Channels
lower_dc_slow = ta.lowest(optimalLength_slow)
upper_dc_slow = ta.highest(optimalLength_slow)
basis_dc_slow = math.avg(upper_dc_slow, lower_dc_slow)
plot(showSlow ? basis_dc_slow : na, "Donchain Channel - Slow Neutral Basis", color=color.new(slowColor, 0))
u_slow = plot(showSlow ? upper_dc_slow : na, "Donchain Channel - Slow Upper", color=color.new(slowColor, 50))
l_slow = plot(showSlow ? lower_dc_slow : na, "Donchain Channel - Slow Lower", color=color.new(slowColor, 50))
fill(u_slow, l_slow, color=color.new(slowColor, 96), title = "Donchain Channel - Slow Background")
Envelopes / Envelopes Adjusted:
Envelopes are an interesting one in the sense that they both may be perceived as useful; however we deem that with the use of an ‘Optimal Length’ that the ‘Envelopes Adjusted’ may work best. We will start with examples of the Traditional Envelope then showcase the Adjusted version.
Envelopes:
As you may see, a Traditional form of Envelopes even produced with our Machine Learning: Optimal Length may not produce optimal results. Unfortunately this may occur with some Traditional Indicators and they may need some adjustments as you’ll notice with the ‘Envelopes Adjusted’ version. However, even without the adjustments, these Envelopes may be useful for seeing ‘Overbought’ and ‘Oversold’ locations within a Machine Learning: Optimal Length standpoint.
Envelopes Adjusted:
By adding an adjustment to these Envelopes, we may hope to better reflect out Optimal Length within it. This is caused by adding a ratio reflection towards the current length of the Optimal Length and the max Length used. This allows for the Fast and Neutral (and potentially Slow if Neutral is greater) to achieve a potentially more accurate result.
Envelopes, much like Bollinger Bands are a way of seeing potential movement zones along with potential Support and Resistance. However, unlike Bollinger Bands which are based on Standard Deviation, Envelopes are based on percentages +/- from the Simple Moving Average.
The code used to reproduce the example above is as follows:
//@version=5
indicator("Optimal Length - Backtesting - Envelopes", overlay=true, max_bars_back=5000)
outputType = input.string("All", "Output Type", options= )
displayType = input.string("Envelope Adjusted", "Display Type", options= )
lengthSource = input.source(close, "Neutral Length")
lengthSource_fast = input.source(close, "Fast Length")
lengthSource_slow = input.source(close, "Slow Length")
showNeutral = outputType == "Neutral" or outputType == "Fast + Neutral" or outputType == "Slow + Neutral" or outputType == "All"
showFast = outputType == "Fast" or outputType == "Fast + Neutral" or outputType == "Fast + Slow" or outputType == "All"
showSlow = outputType == "Slow" or outputType == "Slow + Neutral" or outputType == "Fast + Slow" or outputType == "All"
mult = 2.0
src = close
neutralColor = color.blue
slowColor = color.red
fastColor = color.green
//Neutral
optimalLength = math.min(math.max(math.round(lengthSource), 1), 1000)
optimalMA = ta.sma(close, optimalLength)
//Fast
optimalLength_fast = math.min(math.max(math.round(lengthSource_fast), 1), 1000)
optimalMA_fast = ta.sma(close, optimalLength_fast)
//Slow
optimalLength_slow = math.min(math.max(math.round(lengthSource_slow), 1), 1000)
optimalMA_slow = ta.sma(close, optimalLength_slow)
percent = 10.0
maxAmount = math.max(optimalLength, optimalLength_fast, optimalLength_slow)
//Neutral
k = displayType == "Envelope" ? percent/100.0 : (percent/100.0) / (optimalLength / maxAmount)
upper_env = optimalMA * (1 + k)
lower_env = optimalMA * (1 - k)
plot(showNeutral ? optimalMA : na, "Envelope - Neutral Basis", color=color.new(neutralColor, 0))
u_env = plot(showNeutral ? upper_env : na, "Envelope - Neutral Upper", color=color.new(neutralColor, 50))
l_env = plot(showNeutral ? lower_env : na, "Envelope - Neutral Lower", color=color.new(neutralColor, 50))
fill(u_env, l_env, color=color.new(neutralColor, 96), title = "Envelope - Neutral Background")
//Fast
k_fast = displayType == "Envelope" ? percent/100.0 : (percent/100.0) / (optimalLength_fast / maxAmount)
upper_env_fast = optimalMA_fast * (1 + k_fast)
lower_env_fast = optimalMA_fast * (1 - k_fast)
plot(showFast ? optimalMA_fast : na, "Envelope - Fast Basis", color=color.new(fastColor, 0))
u_env_fast = plot(showFast ? upper_env_fast : na, "Envelope - Fast Upper", color=color.new(fastColor, 50))
l_env_fast = plot(showFast ? lower_env_fast : na, "Envelope - Fast Lower", color=color.new(fastColor, 50))
fill(u_env_fast, l_env_fast, color=color.new(fastColor, 96), title = "Envelope - Fast Background")
//Slow
k_slow = displayType == "Envelope" ? percent/100.0 : (percent/100.0) / (optimalLength_slow / maxAmount)
upper_env_slow = optimalMA_slow * (1 + k_slow)
lower_env_slow = optimalMA_slow * (1 - k_slow)
plot(showSlow ? optimalMA_slow : na, "Envelope - Slow Basis", color=color.new(slowColor, 0))
u_env_slow = plot(showSlow ? upper_env_slow : na, "Envelope - Slow Upper", color=color.new(slowColor, 50))
l_env_slow = plot(showSlow ? lower_env_slow : na, "Envelope - Slow Lower", color=color.new(slowColor, 50))
fill(u_env_slow, l_env_slow, color=color.new(slowColor, 96), title = "Envelope - Slow Background")
Hopefully these examples, including reproducing code, have given you some insight as to how useful this Machine Learning: Optimal Length may be and how another Indicator may easily modify their existing code to incorporate the usage of such Machine Learning: Optimal Length. We likewise will publish a Backtesting Indicator which incorporates all of the concepts we’ve gone over within here; in case you wish to take advantage of the Traditional Indicators mentioned above that allow the input of Machine Learning: Optimal Length and don’t wish to code them.
If you have any questions, comments, ideas or concerns please don't hesitate to contact us.
HAPPY TRADING!
Machine Learning: VWAP [YinYangAlgorithms]Machine Learning: VWAP aims to use Machine Learning to Identify the best location to Anchor the VWAP at. Rather than using a traditional fixed length or simply adjusting based on a Date / Time; by applying Machine Learning we may hope to identify crucial areas which make sense to reset the VWAP and start anew. VWAP’s may act similar to a Bollinger Band in the sense that they help to identify both Overbought and Oversold Price locations based on previous movements and help to identify how far the price may move within the current Trend. However, unlike Bollinger Bands, VWAPs have the ability to parabolically get quite spaced out and also reset. For this reason, the price may never actually go from the Lower to the Upper and vice versa (when very spaced out; when the Upper and Lower zones are narrow, it may bounce between the two). The reason for this is due to how the anchor location is calculated and in this specific Indicator, how it changes anchors based on price movement calculated within Machine Learning.
This Indicator changes the anchor if the Low < Lowest Low of a length of X and likewise if the High > Highest High of a length of X. This logic is applied within a Machine Learning standpoint that likewise amplifies this Lookback Length by adding a Machine Learning Length to it and increasing the lookback length even further.
Due to how the anchor for this VWAP changes, you may notice that the Basis Line (Orange) may act as a Trend Identifier. When the Price is above the basis line, it may represent a bullish trend; and likewise it may represent a bearish trend when below it. You may also notice what may happen is when the trend occurs, it may push all the way to the Upper or Lower levels of this VWAP. It may then proceed to move horizontally until the VWAP expands more and it may gain more movement; or it may correct back to the Basis Line. If it corrects back to the basis line, what may happen is it either uses the Basis Line as a Support and continues in its current direction, or it will change the VWAP anchor and start anew.
Tutorial:
If we zoom in on the most recent VWAP we can see how it expands. Expansion may be caused by time but generally it may be caused by price movement and volume. Exponential Price movement causes the VWAP to expand, even if there are corrections to it. However, please note Volume adds a large weighted factor to the calculation; hence Volume Weighted Average Price (VWAP).
If you refer to the white circle in the example above; you’ll be able to see that the VWAP expanded even while the price was correcting to the Basis line. This happens due to exponential movement which holds high volume. If you look at the volume below the white circle, you’ll notice it was very large; however even though there was exponential price movement after the white circle, since the volume was low, the VWAP didn’t expand much more than it already had.
There may be times where both Volume and Price movement isn’t significant enough to cause much of an expansion. During this time it may be considered to be in a state of consolidation. While looking at this example, you may also notice the color switch from red to green to red. The color of the VWAP is related to the movement of the Basis line (Orange middle line). When the current basis is > the basis of the previous bar the color of the VWAP is green, and when the current basis is < the basis of the previous bar, the color of the VWAP is red. The color may help you gauge the current directional movement the price is facing within the VWAP.
You may have noticed there are signals within this Indicator. These signals are composed of Green and Red Triangles which represent potential Bullish and Bearish momentum changes. The Momentum changes happen when the Signal Type:
The High/Low or Close (You pick in settings)
Crosses one of the locations within the VWAP.
Bullish Momentum change signals occur when :
Signal Type crosses OVER the Basis
Signal Type crosses OVER the lower level
Bearish Momentum change signals occur when:
Signal Type crosses UNDER the Basis
Signal Type Crosses UNDER the upper level
These signals may represent locations where momentum may occur in the direction of these signals. For these reasons there are also alerts available to be set up for them.
If you refer to the two circles within the example above, you may see that when the close goes above the basis line, how it mat represents bullish momentum. Likewise if it corrects back to the basis and the basis acts as a support, it may continue its bullish momentum back to the upper levels again. However, if you refer to the red circle, you’ll see if the basis fails to act as a support, it may then start to correct all the way to the lower levels, or depending on how expanded the VWAP is, it may just reset its anchor due to such drastic movement.
You also have the ability to disable Machine Learning by setting ‘Machine Learning Type’ to ‘None’. If this is done, it will go off whether you have it set to:
Bullish
Bearish
Neutral
For the type of VWAP you want to see. In this example above we have it set to ‘Bullish’. Non Machine Learning VWAP are still calculated using the same logic of if low < lowest low over length of X and if high > highest high over length of X.
Non Machine Learning VWAP’s change much quicker but may also allow the price to correct from one side to the other without changing VWAP Anchor. They may be useful for breaking up a trend into smaller pieces after momentum may have changed.
Above is an example of how the Non Machine Learning VWAP looks like when in Bearish. As you can see based on if it is Bullish or Bearish is how it favors the trend to be and may likewise dictate when it changes the Anchor.
When set to neutral however, the Anchor may change quite quickly. This results in a still useful VWAP to help dictate possible zones that the price may move within, but they’re also much tighter zones that may not expand the same way.
We will conclude this Tutorial here, hopefully this gives you some insight as to why and how Machine Learning VWAPs may be useful; as well as how to use them.
Settings:
VWAP:
VWAP Type: Type of VWAP. You can favor specific direction changes or let it be Neutral where there is even weight to both. Please note, these do not apply to the Machine Learning VWAP.
Source: VWAP Source. By default VWAP usually uses HLC3; however OHLC4 may help by providing more data.
Lookback Length: The Length of this VWAP when it comes to seeing if the current High > Highest of this length; or if the current Low is < Lowest of this length.
Standard VWAP Multiplier: This multiplier is applied only to the Standard VWMA. This is when 'Machine Learning Type' is set to 'None'.
Machine Learning:
Use Rational Quadratics: Rationalizing our source may be beneficial for usage within ML calculations.
Signal Type: Bullish and Bearish Signals are when the price crosses over/under the basis, as well as the Upper and Lower levels. These may act as indicators to where price movement may occur.
Machine Learning Type: Are we using a Simple ML Average, KNN Mean Average, KNN Exponential Average or None?
KNN Distance Type: We need to check if distance is within the KNN Min/Max distance, which distance checks are we using.
Machine Learning Length: How far back is our Machine Learning going to keep data for.
k-Nearest Neighbour (KNN) Length: How many k-Nearest Neighbours will we account for?
Fast ML Data Length: What is our Fast ML Length? This is used with our Slow Length to create our KNN Distance.
Slow ML Data Length: What is our Slow ML Length? This is used with our Fast Length to create our KNN Distance.
If you have any questions, comments, ideas or concerns please don't hesitate to contact us.
HAPPY TRADING!

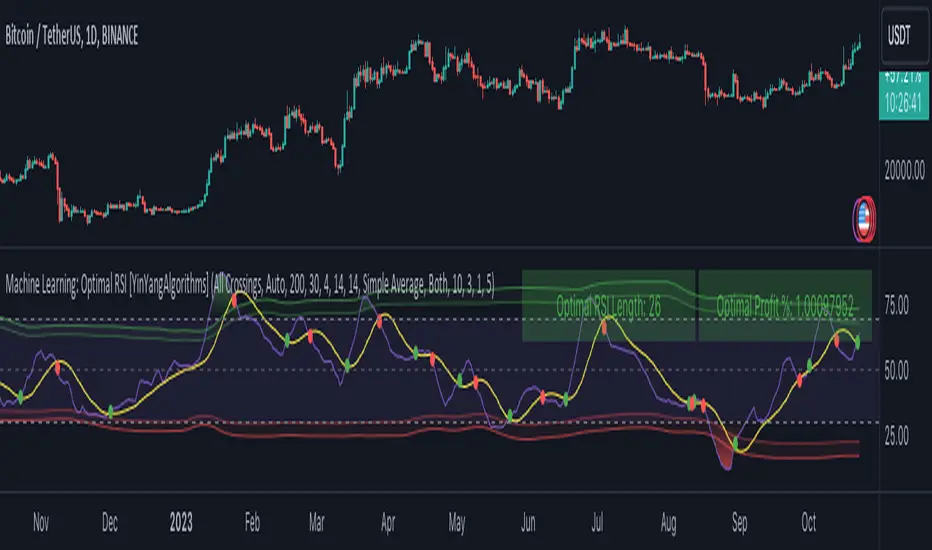
Machine Learning: Optimal RSI [YinYangAlgorithms]This Indicator, will rate multiple different lengths of RSIs to determine which RSI to RSI MA cross produced the highest profit within the lookback span. This ‘Optimal RSI’ is then passed back, and if toggled will then be thrown into a Machine Learning calculation. You have the option to Filter RSI and RSI MA’s within the Machine Learning calculation. What this does is, only other Optimal RSI’s which are in the same bullish or bearish direction (is the RSI above or below the RSI MA) will be added to the calculation.
You can either (by default) use a Simple Average; which is essentially just a Mean of all the Optimal RSI’s with a length of Machine Learning. Or, you can opt to use a k-Nearest Neighbour (KNN) calculation which takes a Fast and Slow Speed. We essentially turn the Optimal RSI into a MA with different lengths and then compare the distance between the two within our KNN Function.
RSI may very well be one of the most used Indicators for identifying crucial Overbought and Oversold locations. Not only that but when it crosses its Moving Average (MA) line it may also indicate good locations to Buy and Sell. Many traders simply use the RSI with the standard length (14), however, does that mean this is the best length?
By using the length of the top performing RSI and then applying some Machine Learning logic to it, we hope to create what may be a more accurate, smooth, optimal, RSI.
Tutorial:
This is a pretty zoomed out Perspective of what the Indicator looks like with its default settings (except with Bollinger Bands and Signals disabled). If you look at the Tables above, you’ll notice, currently the Top Performing RSI Length is 13 with an Optimal Profit % of: 1.00054973. On its default settings, what it does is Scan X amount of RSI Lengths and checks for when the RSI and RSI MA cross each other. It then records the profitability of each cross to identify which length produced the overall highest crossing profitability. Whichever length produces the highest profit is then the RSI length that is used in the plots, until another length takes its place. This may result in what we deem to be the ‘Optimal RSI’ as it is an adaptive RSI which changes based on performance.
In our next example, we changed the ‘Optimal RSI Type’ from ‘All Crossings’ to ‘Extremity Crossings’. If you compare the last two examples to each other, you’ll notice some similarities, but overall they’re quite different. The reason why is, the Optimal RSI is calculated differently. When using ‘All Crossings’ everytime the RSI and RSI MA cross, we evaluate it for profit (short and long). However, with ‘Extremity Crossings’, we only evaluate it when the RSI crosses over the RSI MA and RSI <= 40 or RSI crosses under the RSI MA and RSI >= 60. We conclude the crossing when it crosses back on its opposite of the extremity, and that is how it finds its Optimal RSI.
The way we determine the Optimal RSI is crucial to calculating which length is currently optimal.
In this next example we have zoomed in a bit, and have the full default settings on. Now we have signals (which you can set alerts for), for when the RSI and RSI MA cross (green is bullish and red is bearish). We also have our Optimal RSI Bollinger Bands enabled here too. These bands allow you to see where there may be Support and Resistance within the RSI at levels that aren’t static; such as 30 and 70. The length the RSI Bollinger Bands use is the Optimal RSI Length, allowing it to likewise change in correlation to the Optimal RSI.
In the example above, we’ve zoomed out as far as the Optimal RSI Bollinger Bands go. You’ll notice, the Bollinger Bands may act as Support and Resistance locations within and outside of the RSI Mid zone (30-70). In the next example we will highlight these areas so they may be easier to see.
Circled above, you may see how many times the Optimal RSI faced Support and Resistance locations on the Bollinger Bands. These Bollinger Bands may give a second location for Support and Resistance. The key Support and Resistance may still be the 30/50/70, however the Bollinger Bands allows us to have a more adaptive, moving form of Support and Resistance. This helps to show where it may ‘bounce’ if it surpasses any of the static levels (30/50/70).
Due to the fact that this Indicator may take a long time to execute and it can throw errors for such, we have added a Setting called: Adjust Optimal RSI Lookback and RSI Count. This settings will automatically modify the Optimal RSI Lookback Length and the RSI Count based on the Time Frame you are on and the Bar Indexes that are within. For instance, if we switch to the 1 Hour Time Frame, it will adjust the length from 200->90 and RSI Count from 30->20. If this wasn’t adjusted, the Indicator would Timeout.
You may however, change the Setting ‘Adjust Optimal RSI Lookback and RSI Count’ to ‘Manual’ from ‘Auto’. This will give you control over the ‘Optimal RSI Lookback Length’ and ‘RSI Count’ within the Settings. Please note, it will likely take some “fine tuning” to find working settings without the Indicator timing out, but there are definitely times you can find better settings than our ‘Auto’ will create; especially on higher Time Frames. The Minimum our ‘Auto’ will create is:
Optimal RSI Lookback Length: 90
RSI Count: 20
The Maximum it will create is:
Optimal RSI Lookback Length: 200
RSI Count: 30
If there isn’t much bar index history, for instance, if you’re on the 1 Day and the pair is BTC/USDT you’ll get < 4000 Bar Indexes worth of data. For this reason it is possible to manually increase the settings to say:
Optimal RSI Lookback Length: 500
RSI Count: 50
But, please note, if you make it too high, it may also lead to inaccuracies.
We will conclude our Tutorial here, hopefully this has given you some insight as to how calculating our Optimal RSI and then using it within Machine Learning may create a more adaptive RSI.
Settings:
Optimal RSI:
Show Crossing Signals: Display signals where the RSI and RSI Cross.
Show Tables: Display Information Tables to show information like, Optimal RSI Length, Best Profit, New Optimal RSI Lookback Length and New RSI Count.
Show Bollinger Bands: Show RSI Bollinger Bands. These bands work like the TDI Indicator, except its length changes as it uses the current RSI Optimal Length.
Optimal RSI Type: This is how we calculate our Optimal RSI. Do we use all RSI and RSI MA Crossings or just when it crosses within the Extremities.
Adjust Optimal RSI Lookback and RSI Count: Auto means the script will automatically adjust the Optimal RSI Lookback Length and RSI Count based on the current Time Frame and Bar Index's on chart. This will attempt to stop the script from 'Taking too long to Execute'. Manual means you have full control of the Optimal RSI Lookback Length and RSI Count.
Optimal RSI Lookback Length: How far back are we looking to see which RSI length is optimal? Please note the more bars the lower this needs to be. For instance with BTC/USDT you can use 500 here on 1D but only 200 for 15 Minutes; otherwise it will timeout.
RSI Count: How many lengths are we checking? For instance, if our 'RSI Minimum Length' is 4 and this is 30, the valid RSI lengths we check is 4-34.
RSI Minimum Length: What is the RSI length we start our scans at? We are capped with RSI Count otherwise it will cause the Indicator to timeout, so we don't want to waste any processing power on irrelevant lengths.
RSI MA Length: What length are we using to calculate the optimal RSI cross' and likewise plot our RSI MA with?
Extremity Crossings RSI Backup Length: When there is no Optimal RSI (if using Extremity Crossings), which RSI should we use instead?
Machine Learning:
Use Rational Quadratics: Rationalizing our Close may be beneficial for usage within ML calculations.
Filter RSI and RSI MA: Should we filter the RSI's before usage in ML calculations? Essentially should we only use RSI data that are of the same type as our Optimal RSI? For instance if our Optimal RSI is Bullish (RSI > RSI MA), should we only use ML RSI's that are likewise bullish?
Machine Learning Type: Are we using a Simple ML Average, KNN Mean Average, KNN Exponential Average or None?
KNN Distance Type: We need to check if distance is within the KNN Min/Max distance, which distance checks are we using.
Machine Learning Length: How far back is our Machine Learning going to keep data for.
k-Nearest Neighbour (KNN) Length: How many k-Nearest Neighbours will we account for?
Fast ML Data Length: What is our Fast ML Length? This is used with our Slow Length to create our KNN Distance.
Slow ML Data Length: What is our Slow ML Length? This is used with our Fast Length to create our KNN Distance.
If you have any questions, comments, ideas or concerns please don't hesitate to contact us.
HAPPY TRADING!
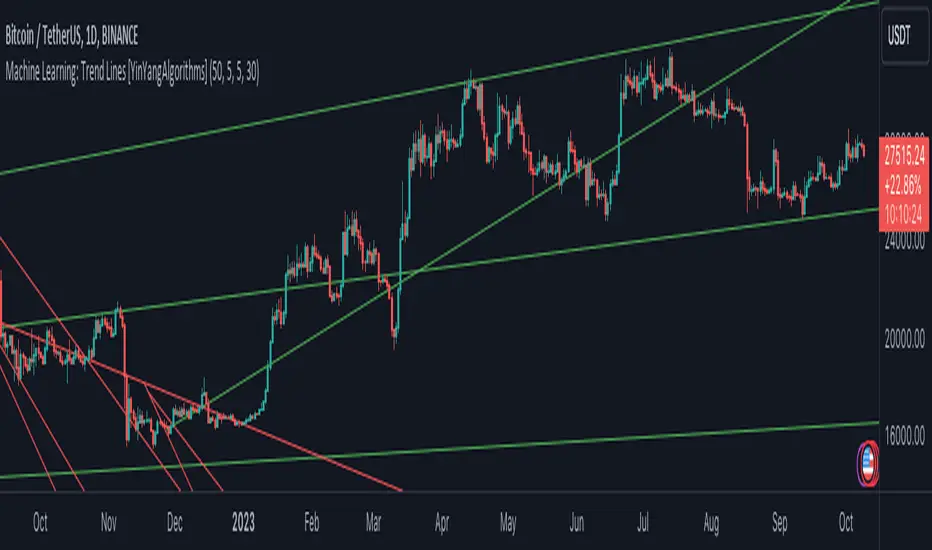
Machine Learning: Trend Lines [YinYangAlgorithms]Trend lines have always been a key indicator that may help predict many different types of price movements. They have been well known to create different types of formations such as: Pennants, Channels, Flags and Wedges. The type of formation they create is based on how the formation was created and the angle it was created. For instance, if there was a strong price increase and then there is a Wedge where both end points meet, this is considered a Bull Pennant. The formations Trend Lines create may be powerful tools that can help predict current Support and Resistance and also Future Momentum changes. However, not all Trend Lines will create formations, and alone they may stand as strong Support and Resistance locations on the Vertical.
The purpose of this Indicator is to apply Machine Learning logic to a Traditional Trend Line Calculation, and therefore allowing a new approach to a modern indicator of high usage. The results of such are quite interesting and goes to show the impacts a simple KNN Machine Learning model can have on Traditional Indicators.
Tutorial:
There are a few different settings within this Indicator. Many will greatly impact the results and if any are changed, lots will need ‘Fine Tuning’. So let's discuss the main toggles that have great effects and what they do before discussing the lengths. Currently in this example above we have the Indicator at its Default Settings. In this example, you can see how the Trend Lines act as key Support and Resistance locations. Due note, Support and Resistance are a relative term, as is their color. What starts off as Support or Resistance may change when the price crosses over / under them.
In the example above we have zoomed in and circled locations that exhibited markers of Support and Resistance along the Trend Lines. These Trend Lines are all created using the Default Settings. As you can see from the example above; just because it is a Green Upwards Trend Line, doesn’t mean it’s a Support Line. Support and Resistance is always shifting on Trend Lines based on the prices location relative to them.
We won’t go through all the Formations Trend Lines make, but the example above, we can see the Trend Lines formed a Downward Channel. Channels are when there are two parallel downwards Trend Lines that are at a relatively similar angle. This means that they won’t ever meet. What may happen when the price is within these channels, is it may bounce between the upper and lower bounds. These Channels may drive the price upwards or downwards, depending on if it is in an Upwards or Downwards Channel.
If you refer to the example above, you’ll notice that the Trend Lines are formed like traditional Trend Lines. They don’t stem from current Highs and Lows but rather Machine Learning Highs and Lows. More often than not, the Machine Learning approach to Trend Lines cause their start point and angle to be quite different than a Traditional Trend Line. Due to this, it may help predict Support and Resistance locations at are more uncommon and therefore can be quite useful.
In the example above we have turned off the toggle in Settings ‘Use Exponential Data Average’. This Settings uses a custom Exponential Data Average of the KNN rather than simply averaging the KNN. By Default it is enabled, but as you can see when it is disabled it may create some pretty strong lasting Trend Lines. This is why we advise you ZOOM OUT AS FAR AS YOU CAN. Trend Lines are only displayed when you’ve zoomed out far enough that their Start Point is visible.
As you can see in this example above, there were 3 major Upward Trend Lines created in 2020 that have had a major impact on Support and Resistance Locations within the last year. Lets zoom in and get a closer look.
We have zoomed in for this example above, and circled some of the major Support and Resistance locations that these Upward Trend Lines may have had a major impact on.
Please note, these Machine Learning Trend Lines aren’t a ‘One Size Fits All’ kind of thing. They are completely customizable within the Settings, so that you can get a tailored experience based on what Pair and Time Frame you are trading on.
When any values are changed within the Settings, you’ll likely need to ‘Fine Tune’ the rest of the settings until your desired result is met. By default the modifiable lengths within the Settings are:
Machine Learning Length: 50
KNN Length:5
Fast ML Data Length: 5
Slow ML Data Length: 30
For example, let's toggle ‘Use Exponential Data Averages’ back on and change ‘Fast ML Data Length’ from 5 to 20 and ‘Slow ML Data Length’ from 30 to 50.
As you can in the example above, all of the lines have changed. Although there are still some strong Support Locations created by the Upwards Trend Lines.
We will conclude our Tutorial here. Hopefully you’ve learned how to use Machine Learning Trend Lines and will be able to now see some more unorthodox Support and Resistance locations on the Vertical.
Settings:
Use Machine Learning Sources: If disabled Traditional Trend line sources (High and Low) will be used rather than Rational Quadratics.
Use KNN Distance Sorting: You can disable this if you wish to not have the Machine Learning Data sorted using KNN. If disabled trend line logic will be Traditional.
Use Exponential Data Average: This Settings uses a custom Exponential Data Average of the KNN rather than simply averaging the KNN.
Machine Learning Length: How strong is our Machine Learning Memory? Please note, when this value is too high the data is almost 'too' much and can lead to poor results.
K-Nearest Neighbour (KNN) Length: How many K-Nearest Neighbours are allowed with our Distance Clustering? Please note, too high or too low may lead to poor results.
Fast ML Data Length: Fast and Slow speed needs to be adjusted properly to see results. 3/5/7 all seem to work well for Fast.
Slow ML Data Length: Fast and Slow speed needs to be adjusted properly to see results. 20 - 50 all seem to work well for Slow.
If you have any questions, comments, ideas or concerns please don't hesitate to contact us.
HAPPY TRADING!
Machine Learning: MFI Heat Map [YinYangAlgorithms]Overview:
MFI Heat Maps are a visually appealing way to display the values of 29 different MFIs at the same time while being able to make sense of it. Each plot within the Indicator represents a different MFI value. The higher you get up, the longer the length that was used for this MFI. This Indicator also features the use of Machine Learning to help balance the MFI levels. It doesn’t solely rely upon Machine Learning but instead incorporates a growing length MFI averaged with the Machine Learning MFI at any given index.
For instance, say we are calculating the 10th plot from the bottom, the MFI would be an average of:
MFI(source, 11)
Machine Learning MFI at Index of 10
We do it this way as they both help smooth each other out without relying solely on just one calculation method.
Due to plot limitations, you are capped at 28 Plot Amounts within this indicator, but that is still quite a bit of information you can glean from a Heat Map.
The Machine Learning used in this indicator is of the K-Nearest Neighbor (KNN). It uses a Fast and Slow MFI calculation then sorts through them over Machine Learning Length and calculates the differences between them. It then slices off KNN length to create our Max/Min Distances allotted. It adds the average between Fast and Slow MFIs to a Viable Distances array if their distances are within the KNN Min/Max distance. It then averages all distances in the Viable Distances array and returns the result.
The result of the KNN Function is saved to another ML Data array whose length is that of Plot Amount (Heat Map Size). This way each Index of the ML Data array can be indexed according to the Heat Map Size.
The Average of the ML Data array is the MFI line (white) that you’ll see plotted on the Indicator. There is also the SMA of the MFI Average (orange) which is likewise plotted. These plots allow you to visualize where the ML MFI is sitting and can potentially be useful for seeing when the MFI Average and SMA cross over and under each other.
We’ve heard many people talk highly of RSI, but sadly not too many even refer to MFI. MFI oftentimes may be overlooked, especially with new traders who may not even know what it is. Essentially MFI is an RSI but it also incorporates Volume into its calculations, which in our opinion leads to a more accurate reading; afterall, what is price movement without Volume.
Tutorial:
You may be thinking, this Indicator looks appealing to the eye, but how do I benefit from it trading wise?
Before we get into our visual examples, let's talk briefly about what makes Heat Maps in general a useful tool for trading. Heat Maps give us the ability to visualize and understand lots of data while removing the clutter. We can understand the data of 29 different MFIs without having to look at and decipher 29 different MFI plots. When you overlay too many MFI lines on top of each other, they can be very difficult to read and oftentimes end up actually hindering your Technical Analysis. For this reason, we have a simple solution to this problem; Heat Maps. This MFI Heat Map allows you to easily know (in a relative %) what the MFI level is for varying lengths. For Instance, the First (bottom) plot indexes an MFI of (K(0) (loop of Plot Amount) + Smoothing Length (default 1)) = 1. Since this is indexing (usually) a very low length, it will change much quicker. Whereas the Last (top) plot indexes an MFI of (K(27) (loop of Plot Amount) + Smoothing Length (default 1)) = 28. This is indexing a much higher length of MFI which results in the MFI the higher you go up in the Heat Map to move much slower.
Heat Maps give us the ability to see changes happening over multiple MFIs at the same time, which can be very useful for seeing shifts in MFI / Momentum. Remember, MFI incorporates Volume, so even if the price goes up a lot, if there was low volume, the MFI won’t move as much as an RSI would. However, likewise, if there is high volume but low price movement, the MFI will move slightly more than the RSI.
Heat Maps change color based on their MFI level. If the MFI is >= 90 it is HOT (red), if the MFI <= 9 it is COLD (teal, think of ICE). Green represents an MFI of 50-59 and Dark Blue represents an MFI of 40-49. Green and Dark blue are the most common colors as all the others are more ‘Extreme’ MFI levels.
Okay, time to get to the Examples :
Since there is so much going on in Heat Maps, we’ve decided to focus this tutorial to this specific area and talk about individual locations before talking about it as a whole.
If you refer to the example above where there are 2 white circles; these white circles are highlighting a key location you’ll be wanting to identify within your Heat Maps, many things are happening here:
The MFI crossed over the SMA (bullish).
The Heat Map started changing from mid/dark Blue (30-50 MFI) to Green (50-59 MFI) around the midline (the 50% dashed like).
The Lower levels of the Heat Map are turning Yellow/Orange/Red (60-100 MFI).
The Upper Levels of the Heat Map are still Light Blue - Green (10-50 MFI).
The 4 Key points above, all point towards potential Bullish Momentum changes. You’re likely wondering, but why? Let's discuss about each one in more specific detail:
1. The MFI crossed over the SMA (bullish): What this tells us is that the current MFI Average is now greater than its average over the last (default) 16 bars. This means there's been a large amount of Money Flow (Price and Volume) recently (subjectively based on the last (default) 16 average). This is one of the leading Bullish / Bearish signals you will see within this Indicator. You can enable Signals within the Settings and/or even add Alerts for when these crossings occur.
2. The Heat Map started changing from mid/dark Blue (30-50 MFI) to Green (50-59 MFI) around the midline (the 50% dashed like): This shows us that the index’s in the mid (if using all 28 heat map plots it would be at 14) has already received some of this momentum change. If you look at the second white circle (right), you’ll also notice the higher MFI plot indexes are also green. This is because since their length is long they still have some momentum and strength from the first white circle (left). Just because the first white circle failed in its bullish push, doesn’t mean it didn’t achieve momentum that would later on help to push the price up.
3. The Lower levels of the Heat Map are turning Yellow/Orange/Red (60-100 MFI): It occurred somewhat in the left white circle, but mainly in the right white circle. This shows us the MFI is very high on the lower lengths, this may lead to the current, middle and higher length MFIs following suit soon. Remember it has to work its way up, the higher levels can’t go red unless the lower levels go red first and the higher levels can also lag quite a bit behind and take awhile to catch up, this is normal, expected and meant to happen. Vice versa is also true with getting higher levels to go cold (light teal (think of ICE)).
4. The Upper Levels of the Heat Map are still Light Blue - Green (10-50 MFI): You might think at first that this is a bad thing, but it's not! Remember you want to be Fearful when others are Greedy and Greedy when others are Fearful! You don’t want to buy when the higher levels have a high MFI, you want to buy when you see the momentum pushing up in the lower MFI levels (getting yellow/orange/red in the low levels) while it is still Cold in the higher levels (BLUE OR GREEN, nothing higher than green as it is already slightly too high). There will be many times that it is Yellow or possibly Orange in the high levels and the bullish push still happens, but this is much more risky! The key to trading is to minimize risks while maximizing potential.
Hopefully now you’re getting an idea of how to spot potential bullish momentum changes, but what about bearish momentum changes? Technically they are the exact opposite, so we don’t need to go into as much detail, but lets still take a look at a few examples:
In the example above we marked the 3 times where it was displaying overly bullish characteristics. We marked the bullish momentum occurring with arrows. If you look closely at the start of the arrow to where it finishes, you’ll notice how the heat (HOT)(RED) works its way up from the lower levels to the higher levels. We then see the MFI to SMA cross under. In all 3 of these examples the heat made it all the way to the top of the chart. These are all very bearish signals that represent a bearish momentum movement that may occur soon.
Also, please note, the level the MFI is at DOES matter! That line isn’t there simply for you to see when there are crosses over and under. The MFI is considered to be Overbought when it is greater than 70 (the upper white dashed line, it is just formatted to be on a different scale cause there are 28 plots, but it represents 70). The MFI is considered to be Oversold when it is less than 30 (the lower white dashed line).
If we look to the left a little here where a big drop in price occurred shortly after our MFI and SMA crossed, would we have been able to identify it using the Heat Maps? Likely, No. There was some color change in the lower levels a few bars prior that went yellow/orange/red but before this cross happened they all went back to Dark Blue. In the middle section when the cross happened it was only Green and Yellow and in the upper section we are Blue. This would be a very risky trade to go on as the only real Bearish Indication was the MFI to SMA cross under. Remember, you want to reduce risk, you don’t want to simply trade on everytime the MFI and SMA cross each other or you’ll be getting yourself into many risky trades based on false signals.
Based on what you’ve learned above, can you see the signs that are indicating where this white circle may have potential for a bullish momentum change?
Now that we are more zoomed in, you may also be noticing there are colors to the price bars. This can be disabled in the settings, but just so you know what they mean, let’s zoom in a little more and talk about it.
We’ve condensed the Indicator a bit so you can see the bars better here. The colors that are displayed on these bars are the Heat Map value for your MFI (the white line in the Indicator). This way you can better see when the Price is Hot and Cold. As you may see while looking, the colors generally go from cold to hot when bullish momentum is happening and hot to cold when bearish momentum is happening. We don’t recommend solely looking at the bars as indicators to MFI momentum change, as seeing the Heat Map will give you much more data; however it can be nice to see the Heat Map projected on the bars rather than trying to eyeball it yourself or hover over each bar specifically to see their levels.
We will conclude our Tutorial here. Hopefully this has given you some insight to how useful Heat Maps can be and why it works well with a Machine Learning (KNN) Model applied to the MFI.
PLEASE NOTE: You can adjust the line width for the Heat Map within the settings. If you condense the Indicator a lot or have a small screen, likely use a length of 1-2. If you have it stretched out or a large screen, a length of 2-3 will work nice. You just don’t want to have the lines overlapping or it defeats the purpose of a Heat Map. Also, the bigger the linewidth, generally you’ll want to increase the Transparency within the Settings also as it can get quite bright and hurt your eyes over time.
Settings:
MFI:
Show MFI and SMA Crossing Signals: MFI and SMA Crossing is one of the leading Bullish and Bearish Signals in this Indicator. You can also add alerts for these signals.
Plot Amount: How many plots are used in this Heat Map. (2 - 28).
Source: The Source to use in all MFI calculations.
Smooth Initial MFI Length: How much to smooth the Fast and Slow MFI calculation by. 1 = No smoothing.
MFI SMA Length: What length we smooth the MFI Average over to get our MFI SMA.
Machine Learning:
Average MFI data by adding a lookback to the Source: While populating our Heat Map with the MFI's, should use use the Source each MFI Length increase or should we also lookback a Source each MFI Length Increase.
KNN Distance Requirement: To be a valid KNN, it needs to abide by a Distance calculation. Generally only Max is used, but you can change it if it suits your trading style better.
Machine Learning Length: How much ML data should we store? The longer the length generally the smoother the result; which may not be as accurate for something like a Heat Map, so keeping this relatively low may lead to more accurate results.
KNN Length: How many KNN are used in the slice to calculate max/min distance allowed.
Fast Length: Fast MFI length used in KNN to calculate distances by comparing its distance with the Slow MFI Length.
Slow Length: Slow MFI length used in KNN to calculate distances by comparing its distance with the Fast MFI Length.
Smoothing Length: When populating our Heat Map, at what length do we start our MFI calculations with (A Higher value with result in a slower and more smoothed MFI / Heat Map).
Colors:
Change Bar Color: Change bar colors to MFI Avg Color.
Heat Map Transparency: If there isn't any transparency it can be a little hard on the eyes. The Greater the Line Width, generally the more transparency you'll want for your eyes.
Line Width: Set how wide the Heat Map lines are
MFI 90-100 Color: Color when the MFI is between these levels.
MFI 80-89 Color: Color when the MFI is between these levels.
MFI 70-79 Color: Color when the MFI is between these levels.
MFI 60-69 Color: Color when the MFI is between these levels.
MFI 50-59 Color: Color when the MFI is between these levels.
MFI 40-49 Color: Color when the MFI is between these levels.
MFI 30-39 Color: Color when the MFI is between these levels.
MFI 20-29 Color: Color when the MFI is between these levels.
MFI 10-19 Color: Color when the MFI is between these levels.
MFI 0-100 Color: Color when the MFI is between these levels.
If you have any questions, comments, ideas or concerns please don't hesitate to contact us.
HAPPY TRADING!

Machine Learning: Support and Resistance [YinYangAlgorithms]Overview:
Support and Resistance is normally based upon Pivot Points and Highest Highs and Lowest Lows. Many times coders even incorporate Volume, RSI and other factors into the equation. However there may be a downside to doing a pure technical approach based on historical levels. We live in a time where Machine Learning is becoming more and more used; thus we have decided to create a Machine Learning Support and Resistance Projection based Indicator. Rather than using traditional Support and Resistance calculations using historical data, we have taken a rather different approach. This Indicator instead attempts to Predict and Project where Support and Resistance locations will be based on a Machine Learning Model using a form of KNN (k-Nearest Neighbors).
Since this indicator creates a Projection of where it deems Support and Resistance will be, it has the ability to move its Support and Resistance before the price even gets to it if it believes it will surpass its projections. This may create a more accurate placement of Support and Resistance as they’re not based on historical levels.
This Indicator does not Repaint.
How it works:
This Indicator makes its projections based on the source you provide (by default close) of the previous bar and submits the source, RSI and EMA to our Projection Function to get its projection of the current bar.
The Projection function essentially calculates potential movement after finding the differences between the source the MA from the current bar, previous bar and average over the span of Machine Learning Length.
Potential movement is defined as:
Average Difference + Average(Machine Learning Average, Average Last Distance)
Average Difference: (Absolute value of Current Source - Current MA) - (Absolute value of Machine Learning Average - Machine Learning MA)
Average Last Distance: Average(Current Source - Current MA, Previous Source - Previous MA)
It then predicts the next bars directional movement (bullish or bearish bar) using several factors:
Previous Source > Previous MA
Current Source - Current MA > Average Source - Average MA
Current RSI > Previous RSI
Current RSI > 30 and Previous RSI <= 30
Current RSI < 70 and Previous RSI >= 70
This helps us to predict the direction the next bar may move.
We then calculate a multiplier that we apply to our Potential Movement value to get our final result which is our Current Bars Close Projection.
Our multiplier is calculated using:
(Current RSI > 30 and Previous RSI <= 30) OR (Current RSI < 70 and Previous RSI >= 70)
Current Source - Current MA > Previous Source - Previous MA
We then create an array and fill it with the previous X projections (Machine Learning Length) and send it to another function. This function, if told to, will sort the data accordingly and then output the KNN average of the length given.
We calculate and plot various KNN lengths to create different Zones:
Strong Support: Length of 2 but sort the data Ascending (low to high)
Strong Resistance: Length of 2 but sort the data Descending (high to low)
Support: Length of Machine Length Length / 10 or Min of 2 sorted by Ascending
Resistance: Length of Machine Length Length / 10 or Min of 2 sorted by Descending
There are also 4 other plots you may be wondering what they are, there is your AVG, VWMA, Long Term Memory and Current Projection.
By default your Current Projection is disabled in settings but you can enable it if you are curious to see how the projections for each close are calculated. It is, however, not a crucial point of interest (white line).
The average is simply the average value of the Machine Learning Data (purple line).
The VWMA is a VWMA calculation applied to our Data over a length specified in settings (by default 1)(blue line). The VWMA is crucial when combined with the Avg as they can cross over and under each other. These crosses represent potential Bullish and Bearish zones.
Lastly, but certainly not least, we have the Long Term Memory (maroon line). The Long Term Memory can be displayed either as an ‘Average’, ‘Hard Line’ or ‘None’. The Long Term Average is only updated every Machine Learning Length Bar Index’s and is populated with the average of the Machine Learning Data. For Instance, if Machine Learning Length is set to 100, the Long Term Memory is only updated every 100 bars, and since its length is the same as the Machine Learning Length, that means its data is composed of 10,000 bars worth of data. The Long Term Memory may be very beneficial for determining where Support and Resistance lie over the Long Term within a Machine Learning Algorithm. When set to ‘Average’ it plots the connection lines diagonally, and although they may be more visually appealing, they’re less useful when it comes to actually seeing support and resistance as generally speaking, support and resistance lie on the horizontal. When set to ‘Hard Line’ the Long Term Memory is connected with hard lines and holds the price value until the next time it is updated. This makes it much more useful for potentially identifying Support and Resistance.
Tutorial:
Here is an overview of what the Indicator looks like, now let's start to dissect it.
In the example above we can see how all of the lines between the Major Support and Resistance zones may act as BOTH Support and Resistance depending on which side the price is currently on. In the circle on the left, we can see how it can fluctuate between the two. If you look at the circle on the right, we can see how the Average line acts as a strong support before it fails to maintain it. Generally speaking, most Support and Resistance locations may potentially fail to hold after 3 tests, as the Average did in this example.
As you can see, the Support and Resistance doesn’t wait to be tested before adjusting, which is why there are 2 lines which create their zones. The inner line is the Support/Resistance and the outer line is the Strong Support/Resistance. The Yellow Circle shows the inner line was able to calculate the moving resistance correctly and then adjusted accordingly as it was projecting the price to keep increasing. However, if you look at the White Circle, you can see that since there was first a crash, and then parabolic movement, that the inner zone could not move and predict the resistance as well as the outer zone could.
We consider the price to be ‘Overvalued’ when it is above the VWMA (blue line) and ‘Undervalued’ when it is below the VWMA. It is considered ‘fair’ price when it is within the VWMA to Average zone (between the blue and purple lines). If you look at the example above, you’ll notice where the two yellow circles are, it is not only considered ‘Overvalued’, but it then proceeds to ride the inner resistance line upwards. This is common when the market is overly bullish and vice versa when it is bearish. Please keep in mind, although it is common, it doesn’t mean a correction can’t happen.
In this example above we look at the last bull run that may have started due to the halving. This bull run was very bullish as you can see in the example above. The price was constantly sitting within the Resistance Zone and the VWMA that was very close to it was constantly acting as a Support. Naturally, due to the Algorithm used in this Indicator, as the momentum starts to slow down, the VWMA (blue line) will start to space out more and more from the Resistance Zone. This doesn’t mean the momentum is gone, it just means it may be slowing down.
Unfortunately we have to study the Bear Market with a different perspective than the Bull Market. However, there are still some similarities within the two. If you refer to the example above and the previous example, you can clearly see that the Bull Market loves to stay with the Resistance Zone and use the VWMA as a Support. However, the Bear Market does not. This is a normal occurrence, however we can see from the example above you may see a correction / horizontal movement when the Outer Support Line is touched. If you look at all 3 yellow circles, the Outer Support Line was touched, then either a small correction or horizontal consolidation occurred.
We will conclude our Tutorial here, hopefully you’ll be able to benefit from a moving Support and Resistance calculated with Machine Learning that projects its locations, rather than using traditional calculations.
Settings:
Source: This source is the base for all our calculations
Machine Learning Length: How much projection data are we storing and using to make calculations.
Smoothing Length: We need to smooth calculations such as RSI, EMA and VWMA. What length are we smoothing it with?
VWMA ML Projection Length: How far into our Machine Learning data should we average for our VWMA. Please note the 'Smoothing Length' is still applied here after getting the Projection Average.
Long Term Memory: Long term memory has the same storage length but is only updated once per Machine Learning Length. For instance, if Machine Learning Length is 100, it will save the Average of our data once every 100 bars. This means its memory is an average of 10,000 bars of Machine Learning. 'Average' connects its values diagonally whereas 'Hard Line' holds its value until it changes.
Use Average Last Distance In Potential Movement: This can help accuracy but generally also displaces the Support and Resistance by projecting it further.
Show Current Projection: Projections occur for each bar, and our Machine Learning utilizes these projections by storing and evaluating them. This toggle will display the Current Projection Line which is used to create all our Projections.
If you have any questions, comments, ideas or concerns please don't hesitate to contact us.
HAPPY TRADING!
AI Momentum [YinYang]Overview:
AI Momentum is a kernel function based momentum Indicator. It uses Rational Quadratics to help smooth out the Moving Averages, this may give them a more accurate result. This Indicator has 2 main uses, first it displays ‘Zones’ that help you visualize the potential movement areas and when the price is out of bounds (Overvalued or Undervalued). Secondly it creates signals that display the momentum of the current trend.
The Zones are composed of the Highest Highs and Lowest lows turned into a Rational Quadratic over varying lengths. These create our Rational High and Low zones. There is however a second zone. The second zone is composed of the avg of the Inner High and Inner Low zones (yellow line) and the Rational Quadratic of the current Close. This helps to create a second zone that is within the High and Low bounds that may represent momentum changes within these zones. When the Rationalized Close crosses above the High and Low Zone Average it may signify a bullish momentum change and vice versa when it crosses below.
There are 3 different signals created to display momentum:
Bullish and Bearish Momentum. These signals display when there is current bullish or bearish momentum happening within the trend. When the momentum changes there will likely be a lull where there are neither Bullish or Bearish momentum signals. These signals may be useful to help visualize when the momentum has started and stopped for both the bulls and the bears. Bullish Momentum is calculated by checking if the Rational Quadratic Close > Rational Quadratic of the Highest OHLC4 smoothed over a VWMA. The Bearish Momentum is calculated by checking the opposite.
Overly Bullish and Bearish Momentum. These signals occur when the bar has Bullish or Bearish Momentum and also has an Rationalized RSI greater or less than a certain level. Bullish is >= 57 and Bearish is <= 43. There is also the option to ‘Factor Volume’ into these signals. This means, the Overly Bullish and Bearish Signals will only occur when the Rationalized Volume > VWMA Rationalized Volume as well as the previously mentioned factors above. This can be useful for removing ‘clutter’ as volume may dictate when these momentum changes will occur, but it can also remove some of the useful signals and you may miss the swing too if the volume just was low. Overly Bullish and Bearish Momentum may dictate when a momentum change will occur. Remember, they are OVERLY Bullish and Bearish, meaning there is a chance a correction may occur around these signals.
Bull and Bear Crosses. These signals occur when the Rationalized Close crosses the Gaussian Close that is 2 bars back. These signals may show when there is a strong change in momentum, but be careful as more often than not they’re predicting that the momentum may change in the opposite direction.
Tutorial:
As we can see in the example above, generally what happens is we get the regular Bullish or Bearish momentum, followed by the Rationalized Close crossing the Zone average and finally the Overly Bullish or Bearish signals. This is normally the order of operations but isn’t always how it happens as sometimes momentum changes don’t make it that far; also the Rationalized Close and Zone Average don’t follow any of the same math as the Signals which can result in differing appearances. The Bull and Bear Crosses are also quite sporadic in appearance and don’t generally follow any sort of order of operations. However, they may occur as a Predictor between Bullish and Bearish momentum, signifying the beginning of the momentum change.
The Bull and Bear crosses may be a Predictor of momentum change. They generally happen when there is no Bullish or Bearish momentum happening; and this helps to add strength to their prediction. When they occur during momentum (orange circle) there is a less likely chance that it will happen, and may instead signify the exact opposite; it may help predict a large spike in momentum in the direction of the Bullish or Bearish momentum. In the case of the orange circle, there is currently Bearish Momentum and therefore the Bull Cross may help predict a large momentum movement is about to occur in favor of the Bears.
We have disabled signals here to properly display and talk about the zones. As you can see, Rationalizing the Highest Highs and Lowest Lows over 2 different lengths creates inner and outer bounds that help to predict where parabolic movement and momentum may move to. Our Inner and Outer zones are great for seeing potential Support and Resistance locations.
The secondary zone, which can cross over and change from Green to Red is also a very important zone. Let's zoom in and talk about it specifically.
The Middle Zone Crosses may help deduce where parabolic movement and strong momentum changes may occur. Generally what may happen is when the cross occurs, you will see parabolic movement to the High / Low zones. This may be the Inner zone but can sometimes be the outer zone too. The hard part is sometimes it can be a Fakeout, like displayed with the Blue Circle. The Cross doesn’t mean it may move to the opposing side, sometimes it may just be predicting Parabolic movement in a general sense.
When we turn the Momentum Signals back on, we can see where the Fakeout occurred that it not only almost hit the Inner Low Zone but it also exhibited 2 Overly Bearish Signals. Remember, Overly bearish signals mean a momentum change in favor of the Bulls may occur soon and overly Bullish signals mean a momentum change in favor of the Bears may occur soon.
You may be wondering, well what does “may occur soon” mean and how do we tell?
The purpose of the momentum signals is not only to let you know when Momentum has occurred and when it is still prevalent. It also matters A LOT when it has STOPPED!
In this example above, we look at when the Overly Bullish and Bearish Momentum has STOPPED. As you can see, when the Overly Bullish or Bearish Momentum stopped may be a strong predictor of potential momentum change in the opposing direction.
We will conclude our Tutorial here, hopefully this Indicator has been helpful for showing you where momentum is occurring and help predict how far it may move. We have been dabbling with and are planning on releasing a Strategy based on this Indicator shortly.
Settings:
1. Momentum:
Show Signals: Sometimes it can be difficult to visualize the zones with signals enabled.
Factor Volume: Factor Volume only applies to Overly Bullish and Bearish Signals. It's when the Volume is > VWMA Volume over the Smoothing Length.
Zone Inside Length: The Zone Inside is the Inner zone of the High and Low. This is the length used to create it.
Zone Outside Length: The Zone Outside is the Outer zone of the High and Low. This is the length used to create it.
Smoothing length: Smoothing length is the length used to smooth out our Bullish and Bearish signals, along with our Overly Bullish and Overly Bearish Signals.
2. Kernel Settings:
Lookback Window: The number of bars used for the estimation. This is a sliding value that represents the most recent historical bars. Recommended range: 3-50.
Relative Weighting: Relative weighting of time frames. As this value approaches zero, the longer time frames will exert more influence on the estimation. As this value approaches infinity, the behavior of the Rational Quadratic Kernel will become identical to the Gaussian kernel. Recommended range: 0.25-25.
Start Regression at Bar: Bar index on which to start regression. The first bars of a chart are often highly volatile, and omission of these initial bars often leads to a better overall fit. Recommended range: 5-25.
If you have any questions, comments, ideas or concerns please don't hesitate to contact us.
HAPPY TRADING!
Machine Learning: Trend Pulse⚠️❗ Important Limitations: Due to the way this script is designed, it operates specifically under certain conditions:
Stocks & Forex : Only compatible with timeframes of 8 hours and above ⏰
Crypto : Only works with timeframes starting from 4 hours and higher ⏰
❗Please note that the script will not work on lower timeframes.❗
Feature Extraction : It begins by identifying a window of past price changes. Think of this as capturing the "mood" of the market over a certain period.
Distance Calculation : For each historical data point, it computes a distance to the current window. This distance measures how similar past and present market conditions are. The smaller the distance, the more similar they are.
Neighbor Selection : From these, it selects 'k' closest neighbors. The variable 'k' is a user-defined parameter indicating how many of the closest historical points to consider.
Price Estimation : It then takes the average price of these 'k' neighbors to generate a forecast for the next stock price.
Z-Score Scaling: Lastly, this forecast is normalized using the Z-score to make it more robust and comparable over time.
Inputs:
histCap (Historical Cap) : histCap limits the number of past bars the script will consider. Think of it as setting the "memory" of model—how far back in time it should look.
sampleSpeed (Sampling Rate) : sampleSpeed is like a time-saving shortcut, allowing the script to skip bars and only sample data points at certain intervals. This makes the process faster but could potentially miss some nuances in the data.
winSpan (Window Size) : This is the size of the "snapshot" of market data the script will look at each time. The window size sets how many bars the algorithm will include when it's measuring how "similar" the current market conditions are to past conditions.
All these variables help to simplify and streamline the k-NN model, making it workable within limitations. You could see them as tuning knobs, letting you balance between computational efficiency and predictive accuracy.
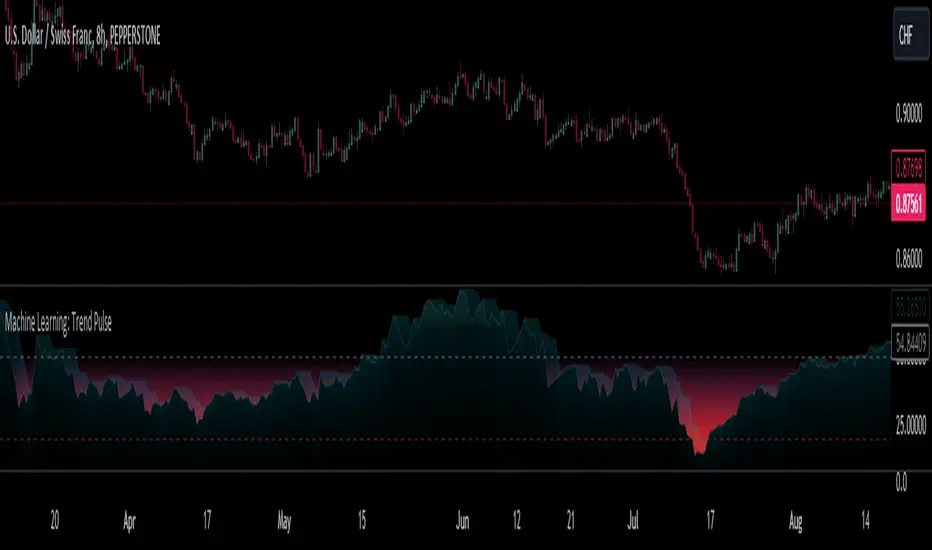
Fusion: Machine Learning SuiteThe Fusion: Machine Learning Suite combines multiple technical analysis dimensions and harnesses the predictive power of machine learning, seamlessly integrating a diverse array of classic and novel indicators to deliver precision, adaptability, and innovation.
Features and Capabilities
Multidimensional Analysis: Fusion: MLS integrates various technical analysis dimensions to offer a more comprehensive perspective.
Machine Learning Integration: Utilizing ML algorithms, Fusion: MLS offers adaptability to market changes.
Custom Indicators: Including dimensions like "Moon Lander", "Cap Line" and "Z-Pack" the indicator expands the scope of traditional technical analysis methods.
Tailored Customization: With customization options, Fusion: MLS allows traders to configure the tool to suit their specific strategies and market focus.
In the following sections, we'll explore the features and settings of Fusion: MLS in detail, providing insights into how it can be utilized.
Major Features and Settings
The indicator consists of several core components and settings, each designed to provide specific functionalities and insights. Here's an in-depth look:
Machine Learning Component
Distance Classifier: A Strategic Approach to Market Analysis
In the world of trading and investment, the ability to classify and predict price movements is paramount. Machine learning offers powerful tools for this purpose.
The Fusion: MLS indicator among others incorporates an Approximate Nearest Neighbors (ANN)* algorithm, a machine learning classification technique, and allows the selection of various distance functions .
This flexibility sets Fusion: MLS apart from existing solutions. The available distance functions include:
Euclidean: Standard distance metric, commonly used as a default.
Chebyshev: Also known as maximum value distance.
Manhattan: Sum of absolute differences.
Minkowski: Generalized metric that includes Euclidean and Manhattan as special cases.
Mahalanobis: Measures distance between points in a correlated space.
Lorentzian: Known for its robustness to outliers and noise.
*For a deeper understanding of the Approximate Nearest Neighbors (ANN) algorithm, traders are encouraged to refer to the relevant articles that can be found in the public domain.
Alternative scoring system
Fusion: MLS also includes a custom scoring alternative based on directional price action.
"Combined: Directional" and "Alpha: Directional" scoring types represent our own directional change algorithm, simple yet effective in displaying trend direction changes early on. They are visualized by color changes when scoring becomes below or above zero.
Changes in scoring quickly reflect shifts in buyer and seller sentiment.
Traders may choose signals by Color Change in the indicator settings to get alerts when scoring color shifts, not waiting until the histogram crosses the zero level.
Application in Trading
Machine learning classification has become an integral part of modern trading, offering innovative ways to analyze and interpret financial data.
Many algorithmic trading systems leverage ML classification to automate trading decisions. By continuously learning from real-time data, these systems can adapt to changing market conditions and execute trades with increased efficiency and accuracy.
ML classification allows for the development of tailored trading strategies as traders can select specific algorithms, dimensions, and filters that align with their trading style, goals, and the particular market they are operating.
We have integrated ML classification with traditional trading tools, such as moving averages and technical indicators. This fusion creates a more robust analysis framework, combining the strengths of classical techniques with the adaptability of machine learning.
Whether used independently or in conjunction with other tools, ML classification represents a significant advancement in trading technology, opening new avenues for exploration, innovation, and success in the financial world.
ML: Weighting System
The Fusion: MLS indicator introduces a unique weighting system that allows traders to customize the influence of various technical indicators in the machine learning process. This feature is not only innovative but also provides a level of control and adaptability that sets it apart from other indicators.
Customizable Weights
The weighting system allows users to assign specific weights to different indicators such as Moon Lander, RSI, MACD, Money Flow, Bollinger Bands, Cap Line, Z-Pack, Squeeze Momentum*, and MA Crossover. These weights can be adjusted manually, providing the ability to emphasize or de-emphasize specific indicators based on the trader's strategy or market conditions.
*Note, we determined via testing that the popular "Squeeze" indicator can actually be well replicated by simply using inputs of 15 & 199 in the bedrock indicator - MACD ; while we employed the standard "Squeeze" formula (developed by J. Carter ) in Fusion: MLS, traders are hereby made aware of our research findings regarding such.
The weighting system's importance lies in its ability to provide a more nuanced and personalized analysis. By adjusting the weights of different indicators a trader focusing on momentum strategies might assign higher weights to the Squeeze Momentum and MA Crossover indicators, while a trader looking for volatility might emphasize RSI and Bollinger Bands.
The ability to customize weights adds a layer of complexity and adaptability that is rare in standard machine-learning indicators.
Custom Indicators: Moon Lander
The "Moon Lander" is not just a catchy name; it's a robust feature inspired by principles from aerospace engineering and offers a unique perspective on trading analysis. Here's a conceptual overview:
Fast EMA and Kalman Matrix
"Moon Lander" incorporates both a Fast Exponential Moving Average (EMA) and a Kalman Matrix in its design. These two elements are combined to create a histogram, providing a specific approach to data analysis.
The Kalman Matrix, or Kalman Filter, is a mathematical concept used for estimating variables that can be measured indirectly and contain noise or uncertainty. It's a standard tool in machine learning and control systems, known for its ability to provide optimal estimates based on observed data.
Kalman Filter: A Navigational Tool
The Kalman filter, an essential part of "Moon Lander," is a mathematical concept known for its applications in navigation and control systems used by NASA in the apollo program :
Guidance in Uncertainty: Just as the Kalman filter helped guide complex aerospace missions through uncertain paths, it assists traders in navigating the often unpredictable financial markets.
Filtering Noise: In trading, the Kalman filter serves to filter out market noise, allowing traders to focus on the underlying trends.
Predictive Capabilities: Its ability to predict future states makes it a valuable tool for forecasting market movements and trend directions.
Custom Indicators: Cap Line and Z-Pack
Fusion: MLS integrates our additional proprietary custom indicators that have been published on TradingView earlier:
Cap Line: Delve into the specific functionalities and applications of our proprietary "Cap Line" indicator in the published description on TradingView.
Z-Pack: Explore the analytical perspectives, focused on the z-score methodology, and custom "Z-Pack" indicator by reviewing the published description on TradingView.
Buy/Sell Signal Generation Algorithms
Fusion: MLS offers various options for generating buy/sell signals, tailored to different trading strategies and perspectives:
Fusion: Allows traders to select any number of dimensions to receive buy/sell signals from, offering customized signal generation.
ML: Utilizes the machine learning ANN distance for signal generation.
Color Change: Generates signals by selected scoring type color change.
Displayed Dimension, Alpha Dimension: Generate signals based on specific selected dimensions.
These algorithms provide flexibility in determining buy/sell signals, catering to different trading styles and market conditions.
Filters
Filters are used to refine and selectively include or exclude signals based on specific criteria. Rather than generating signals, these filters act as gatekeepers, ensuring that only the signals meeting certain conditions are considered. Here's an overview of the filters used:
Dynamic State Predictor (DSP)
The DSP employs the Kalman Matrix to evaluate existing signals by comparing the fast and slow-moving averages, both processed through the Kalman Matrix. Based on the relationship between these averages, the DSP may exclude specific signals, depending on whether they align with upward or downward trends.
Average Directional Index (ADX)
The ADX filter evaluates the strength of existing trends and filters out signals that do not meet the specified ADX threshold and length, focusing on significant market movements.
Feature Engineering: RSI
Applies a filter to the existing signals, clearing out those that do not meet the criteria for RSI overbought or oversold threshold condition.
Feature Engineering: MACD
Assesses existing signals to identify changes in the strength, direction, momentum, and duration of a trend, filtering out those that do not align with MACD trend direction.
The Visual Component
The machine learning component is an internal component. However, the indicator also offers an equally important and useful visual component. It is a graphical representation of the multiple technical analysis dimensions, that can be combined in various ways (where the name "Fusion" comes from), allowing traders to visualize the underlying data and its analysis.
Displayed Dimension: Visualization and Normalization
The Fusion: MLS indicator offers a "Displayed Dimension" feature that visualizes various dimensions as a histogram. These dimensions may include RSI, MAs, BBs, MACD, etc.
RSI Dimension on the image + ML signals
Normalization: Each dimension is normalized. If any dimension has extreme values, a Fisher transformation is applied to bring them within a reasonable range.
Combined Dimension: When selecting the "Combined" option , the normalized values of the selected dimensions are combined using techniques such as standardization, normalization, or winsorization. This flexibility enables tailored visualization and analysis.
Alpha Dimension: Enhancing Analysis
The "Alpha Dimension" feature allows traders to select an additional dimension alongside the Displayed Dimension. This facilitates a combined analysis, enhancing the depth of insights.
Theme Selection
Fusion: MLS offers various themes such as "Sailfish", "Iceberg", "Moon", "Perl", "Candy" and "Monochrome" Traders can select a theme that resonates with their preference, enhancing visual appeal. There is also a "Custom" theme available that allows the user to choose the colors of the theme.
Customizing Fusion: MLS for Various Markets and Strategies
Fusion: MLS is designed with customization in mind. Traders can tailor the indicator to suit various markets and trading strategies. Selecting specific dimensions allows it to align with individual trading goals.
Selecting Dimensions: Choose the dimensions that resonate with your trading approach, whether focusing on trend-following, momentum, or other strategies.
Adjusting Parameters: Fine-tune the parameters of each dimension, including custom ones like "Moon Lander," to suit specific market conditions.
Theme Customization: Select a theme that aligns with your visual preferences, enhancing your chart's readability and appeal.
Utilizing Research: Leverage the underlying algorithms and research, such as machine learning classification by ANN and the Kalman filter, to deepen your understanding and application of Fusion: MLS.
Alerts
The indicator includes an alerting system that notifies traders when new buy or sell signals are detected.
Disclaimer
The information provided herein is intended for informational purposes only and should not be construed as investment advice, endorsement, nor a recommendation to buy or sell any financial instruments. Fusion: MLS is a technical analysis tool, and like all tools, it should be used with caution and in conjunction with other forms of analysis.
Traders and investors are encouraged to consult with a licensed financial professional and conduct their own research before making any trading or investment decisions. Past performance of the Fusion: MLS indicator or any trading strategy does not guarantee future results, and all trading involves risk. Users of Fusion: MLS should understand the underlying algorithms and assumptions and consider their individual risk tolerance and investment goals when using this tool.
SuperTrend AI (Clustering) [LuxAlgo]The SuperTrend AI indicator is a novel take on bridging the gap between the K-means clustering machine learning method & technical indicators. In this case, we apply K-Means clustering to the famous SuperTrend indicator.
🔶 USAGE
Users can interpret the SuperTrend AI trailing stop similarly to the regular SuperTrend indicator. Using higher minimum/maximum factors will return longer-term signals.
The displayed performance metrics displayed on each signal allow for a deeper interpretation of the indicator. Whereas higher values could indicate a higher potential for the market to be heading in the direction of the trend when compared to signals with lower values such as 1 or 0 potentially indicating retracements.
In the image above, we can notice more clear examples of the performance metrics on signals indicating trends, however, these performance metrics cannot perform or predict every signal reliably.
We can see in the image above that the trailing stop and its adaptive moving average can also act as support & resistance. Using higher values of the performance memory setting allows users to obtain a longer-term adaptive moving average of the returned trailing stop.
🔶 DETAILS
🔹 K-Means Clustering
When observing data points within a specific space, we can sometimes observe that some are closer to each other, forming groups, or "Clusters". At first sight, identifying those clusters and finding their associated data points can seem easy but doing so mathematically can be more challenging. This is where cluster analysis comes into play, where we seek to group data points into various clusters such that data points within one cluster are closer to each other. This is a common branch of AI/machine learning.
Various methods exist to find clusters within data, with the one used in this script being K-Means Clustering , a simple iterative unsupervised clustering method that finds a user-set amount of clusters.
A naive form of the K-Means algorithm would perform the following steps in order to find K clusters:
(1) Determine the amount (K) of clusters to detect.
(2) Initiate our K centroids (cluster centers) with random values.
(3) Loop over the data points, and determine which is the closest centroid from each data point, then associate that data point with the centroid.
(4) Update centroids by taking the average of the data points associated with a specific centroid.
Repeat steps 3 to 4 until convergence, that is until the centroids no longer change.
To explain how K-Means works graphically let's take the example of a one-dimensional dataset (which is the dimension used in our script) with two apparent clusters:
This is of course a simple scenario, as K will generally be higher, as well the amount of data points. Do note that this method can be very sensitive to the initialization of the centroids, this is why it is generally run multiple times, keeping the run returning the best centroids.
🔹 Adaptive SuperTrend Factor Using K-Means
The proposed indicator rationale is based on the following hypothesis:
Given multiple instances of an indicator using different settings, the optimal setting choice at time t is given by the best-performing instance with setting s(t) .
Performing the calculation of the indicator using the best setting at time t would return an indicator whose characteristics adapt based on its performance. However, what if the setting of the best-performing instance and second best-performing instance of the indicator have a high degree of disparity without a high difference in performance?
Even though this specific case is rare its however not uncommon to see that performance can be similar for a group of specific settings (this could be observed in a parameter optimization heatmap), then filtering out desirable settings to only use the best-performing one can seem too strict. We can as such reformulate our first hypothesis:
Given multiple instances of an indicator using different settings, an optimal setting choice at time t is given by the average of the best-performing instances with settings s(t) .
Finding this group of best-performing instances could be done using the previously described K-Means clustering method, assuming three groups of interest (K = 3) defined as worst performing, average performing, and best performing.
We first obtain an analog of performance P(t, factor) described as:
P(t, factor) = P(t-1, factor) + α * (∆C(t) × S(t-1, factor) - P(t-1, factor))
where 1 > α > 0, which is the performance memory determining the degree to which older inputs affect the current output. C(t) is the closing price, and S(t, factor) is the SuperTrend signal generating function with multiplicative factor factor .
We run this performance function for multiple factor settings and perform K-Means clustering on the multiple obtained performances to obtain the best-performing cluster. We initiate our centroids using quartiles of the obtained performances for faster centroids convergence.
The average of the factors associated with the best-performing cluster is then used to obtain the final factor setting, which is used to compute the final SuperTrend output.
Do note that we give the liberty for the user to get the final factor from the best, average, or worst cluster for experimental purposes.
🔶 SETTINGS
ATR Length: ATR period used for the calculation of the SuperTrends.
Factor Range: Determine the minimum and maximum factor values for the calculation of the SuperTrends.
Step: Increments of the factor range.
Performance Memory: Determine the degree to which older inputs affect the current output, with higher values returning longer-term performance measurements.
From Cluster: Determine which cluster is used to obtain the final factor.
🔹 Optimization
This group of settings affects the runtime performances of the script.
Maximum Iteration Steps: Maximum number of iterations allowed for finding centroids. Excessively low values can return a better script load time but poor clustering.
Historical Bars Calculation: Calculation window of the script (in bars).

RSI-MFI Machine Learning [ Manhattan distance ]The RSI-MFI Machine Learning Indicator is a technical analysis tool that combines the Relative Strength Index (RSI) and Money Flow Index (MFI) indicators with the Manhattan distance metric.
It aims to provide insights into potential trade setups by leveraging machine learning principles and calculating distances between current and historical data points.
The indicator starts by calculating the RSI and MFI values based on the specified periods for each indicator.
The RSI measures the strength and speed of price movements, while the MFI evaluates the inflow and outflow of money in the market.
By combining these two indicators, the indicator captures both price momentum and money flow dynamics.
To apply machine learning principles , the indicator utilizes the Manhattan distance metric to quantify the similarity or dissimilarity between different data points.
The Manhattan distance is calculated by taking the absolute differences between corresponding RSI and MFI values of the current point and historical points.
Next, the indicator determines the nearest neighbors based on the calculated Manhattan distances.
The number of nearest neighbors is determined by the square root of the specified count of neighbors.
By identifying similar patterns and behaviors in the historical data, the indicator aims to uncover potential trade opportunities.
Trade signals are generated based on the calculated distances. The indicator compares each distance with the maximum distance encountered so far.
If a new maximum distance is found, it updates the value and considers the corresponding direction as a potential trade signal. The trade signals are stored in an array for further analysis.
Furthermore, the indicator considers the price action and a calculated regression line to differentiate between long and short trade signals.
Long trade signals are identified when the closing price is above the regression line, indicating a potentially bullish setup.
Short trade signals are identified when the closing price is below the regression line, indicating a potentially bearish setup.
The RSI-MFI Machine Learning Indicator visualizes the regression line on the price chart and labels the bars accordingly. It highlights the regression line with different colors based on the trade signals, making it easier for traders to identify potential entry or exit points.
Traders can use the RSI-MFI Machine Learning Indicator as a tool to analyze price movements, evaluate market conditions based on RSI and MFI, leverage machine learning concepts to find similar patterns, and make informed trading decisions.
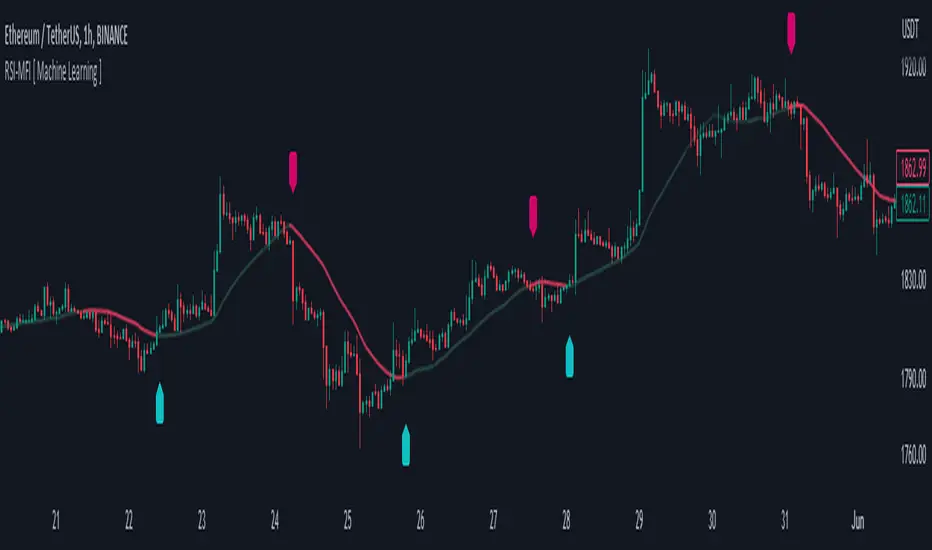
Machine Learning: Lorentzian Classification█ OVERVIEW
A Lorentzian Distance Classifier (LDC) is a Machine Learning classification algorithm capable of categorizing historical data from a multi-dimensional feature space. This indicator demonstrates how Lorentzian Classification can also be used to predict the direction of future price movements when used as the distance metric for a novel implementation of an Approximate Nearest Neighbors (ANN) algorithm.
█ BACKGROUND
In physics, Lorentzian space is perhaps best known for its role in describing the curvature of space-time in Einstein's theory of General Relativity (2). Interestingly, however, this abstract concept from theoretical physics also has tangible real-world applications in trading.
Recently, it was hypothesized that Lorentzian space was also well-suited for analyzing time-series data (4), (5). This hypothesis has been supported by several empirical studies that demonstrate that Lorentzian distance is more robust to outliers and noise than the more commonly used Euclidean distance (1), (3), (6). Furthermore, Lorentzian distance was also shown to outperform dozens of other highly regarded distance metrics, including Manhattan distance, Bhattacharyya similarity, and Cosine similarity (1), (3). Outside of Dynamic Time Warping based approaches, which are unfortunately too computationally intensive for PineScript at this time, the Lorentzian Distance metric consistently scores the highest mean accuracy over a wide variety of time series data sets (1).
Euclidean distance is commonly used as the default distance metric for NN-based search algorithms, but it may not always be the best choice when dealing with financial market data. This is because financial market data can be significantly impacted by proximity to major world events such as FOMC Meetings and Black Swan events. This event-based distortion of market data can be framed as similar to the gravitational warping caused by a massive object on the space-time continuum. For financial markets, the analogous continuum that experiences warping can be referred to as "price-time".
Below is a side-by-side comparison of how neighborhoods of similar historical points appear in three-dimensional Euclidean Space and Lorentzian Space:
This figure demonstrates how Lorentzian space can better accommodate the warping of price-time since the Lorentzian distance function compresses the Euclidean neighborhood in such a way that the new neighborhood distribution in Lorentzian space tends to cluster around each of the major feature axes in addition to the origin itself. This means that, even though some nearest neighbors will be the same regardless of the distance metric used, Lorentzian space will also allow for the consideration of historical points that would otherwise never be considered with a Euclidean distance metric.
Intuitively, the advantage inherent in the Lorentzian distance metric makes sense. For example, it is logical that the price action that occurs in the hours after Chairman Powell finishes delivering a speech would resemble at least some of the previous times when he finished delivering a speech. This may be true regardless of other factors, such as whether or not the market was overbought or oversold at the time or if the macro conditions were more bullish or bearish overall. These historical reference points are extremely valuable for predictive models, yet the Euclidean distance metric would miss these neighbors entirely, often in favor of irrelevant data points from the day before the event. By using Lorentzian distance as a metric, the ML model is instead able to consider the warping of price-time caused by the event and, ultimately, transcend the temporal bias imposed on it by the time series.
For more information on the implementation details of the Approximate Nearest Neighbors (ANN) algorithm used in this indicator, please refer to the detailed comments in the source code.
█ HOW TO USE
Below is an explanatory breakdown of the different parts of this indicator as it appears in the interface:
Below is an explanation of the different settings for this indicator:
General Settings:
Source - This has a default value of "hlc3" and is used to control the input data source.
Neighbors Count - This has a default value of 8, a minimum value of 1, a maximum value of 100, and a step of 1. It is used to control the number of neighbors to consider.
Max Bars Back - This has a default value of 2000.
Feature Count - This has a default value of 5, a minimum value of 2, and a maximum value of 5. It controls the number of features to use for ML predictions.
Color Compression - This has a default value of 1, a minimum value of 1, and a maximum value of 10. It is used to control the compression factor for adjusting the intensity of the color scale.
Show Exits - This has a default value of false. It controls whether to show the exit threshold on the chart.
Use Dynamic Exits - This has a default value of false. It is used to control whether to attempt to let profits ride by dynamically adjusting the exit threshold based on kernel regression.
Feature Engineering Settings:
Note: The Feature Engineering section is for fine-tuning the features used for ML predictions. The default values are optimized for the 4H to 12H timeframes for most charts, but they should also work reasonably well for other timeframes. By default, the model can support features that accept two parameters (Parameter A and Parameter B, respectively). Even though there are only 4 features provided by default, the same feature with different settings counts as two separate features. If the feature only accepts one parameter, then the second parameter will default to EMA-based smoothing with a default value of 1. These features represent the most effective combination I have encountered in my testing, but additional features may be added as additional options in the future.
Feature 1 - This has a default value of "RSI" and options are: "RSI", "WT", "CCI", "ADX".
Feature 2 - This has a default value of "WT" and options are: "RSI", "WT", "CCI", "ADX".
Feature 3 - This has a default value of "CCI" and options are: "RSI", "WT", "CCI", "ADX".
Feature 4 - This has a default value of "ADX" and options are: "RSI", "WT", "CCI", "ADX".
Feature 5 - This has a default value of "RSI" and options are: "RSI", "WT", "CCI", "ADX".
Filters Settings:
Use Volatility Filter - This has a default value of true. It is used to control whether to use the volatility filter.
Use Regime Filter - This has a default value of true. It is used to control whether to use the trend detection filter.
Use ADX Filter - This has a default value of false. It is used to control whether to use the ADX filter.
Regime Threshold - This has a default value of -0.1, a minimum value of -10, a maximum value of 10, and a step of 0.1. It is used to control the Regime Detection filter for detecting Trending/Ranging markets.
ADX Threshold - This has a default value of 20, a minimum value of 0, a maximum value of 100, and a step of 1. It is used to control the threshold for detecting Trending/Ranging markets.
Kernel Regression Settings:
Trade with Kernel - This has a default value of true. It is used to control whether to trade with the kernel.
Show Kernel Estimate - This has a default value of true. It is used to control whether to show the kernel estimate.
Lookback Window - This has a default value of 8 and a minimum value of 3. It is used to control the number of bars used for the estimation. Recommended range: 3-50
Relative Weighting - This has a default value of 8 and a step size of 0.25. It is used to control the relative weighting of time frames. Recommended range: 0.25-25
Start Regression at Bar - This has a default value of 25. It is used to control the bar index on which to start regression. Recommended range: 0-25
Display Settings:
Show Bar Colors - This has a default value of true. It is used to control whether to show the bar colors.
Show Bar Prediction Values - This has a default value of true. It controls whether to show the ML model's evaluation of each bar as an integer.
Use ATR Offset - This has a default value of false. It controls whether to use the ATR offset instead of the bar prediction offset.
Bar Prediction Offset - This has a default value of 0 and a minimum value of 0. It is used to control the offset of the bar predictions as a percentage from the bar high or close.
Backtesting Settings:
Show Backtest Results - This has a default value of true. It is used to control whether to display the win rate of the given configuration.
█ WORKS CITED
(1) R. Giusti and G. E. A. P. A. Batista, "An Empirical Comparison of Dissimilarity Measures for Time Series Classification," 2013 Brazilian Conference on Intelligent Systems, Oct. 2013, DOI: 10.1109/bracis.2013.22.
(2) Y. Kerimbekov, H. Ş. Bilge, and H. H. Uğurlu, "The use of Lorentzian distance metric in classification problems," Pattern Recognition Letters, vol. 84, 170–176, Dec. 2016, DOI: 10.1016/j.patrec.2016.09.006.
(3) A. Bagnall, A. Bostrom, J. Large, and J. Lines, "The Great Time Series Classification Bake Off: An Experimental Evaluation of Recently Proposed Algorithms." ResearchGate, Feb. 04, 2016.
(4) H. Ş. Bilge, Yerzhan Kerimbekov, and Hasan Hüseyin Uğurlu, "A new classification method by using Lorentzian distance metric," ResearchGate, Sep. 02, 2015.
(5) Y. Kerimbekov and H. Şakir Bilge, "Lorentzian Distance Classifier for Multiple Features," Proceedings of the 6th International Conference on Pattern Recognition Applications and Methods, 2017, DOI: 10.5220/0006197004930501.
(6) V. Surya Prasath et al., "Effects of Distance Measure Choice on KNN Classifier Performance - A Review." .
█ ACKNOWLEDGEMENTS
@veryfid - For many invaluable insights, discussions, and advice that helped to shape this project.
@capissimo - For open sourcing his interesting ideas regarding various KNN implementations in PineScript, several of which helped inspire my original undertaking of this project.
@RikkiTavi - For many invaluable physics-related conversations and for his helping me develop a mechanism for visualizing various distance algorithms in 3D using JavaScript
@jlaurel - For invaluable literature recommendations that helped me to understand the underlying subject matter of this project.
@annutara - For help in beta-testing this indicator and for sharing many helpful ideas and insights early on in its development.
@jasontaylor7 - For helping to beta-test this indicator and for many helpful conversations that helped to shape my backtesting workflow
@meddymarkusvanhala - For helping to beta-test this indicator
@dlbnext - For incredibly detailed backtesting testing of this indicator and for sharing numerous ideas on how the user experience could be improved.
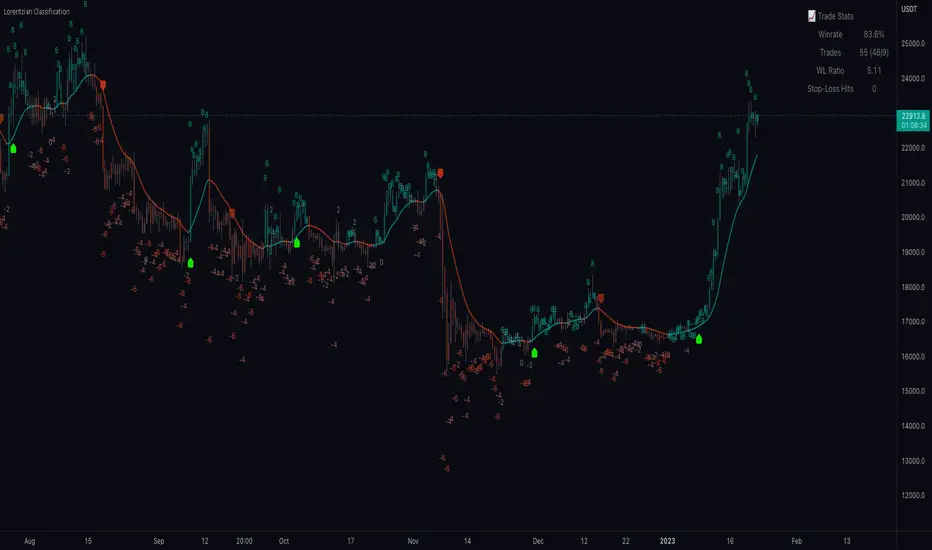
CBOE PCR Factor Dependent Variable Odd Generator This script is the my Dependent Variable Odd Generator script :
with the Put / Call Ratio ( PCR ) appended, only for CBOE and the instruments connected to it.
For CBOE this script is more accurate and faster than Dependent Variable Odd Generator. And the stagnant market odds are better and more realistic.
Do not use for timeframe periods less than 1 day.
Because PCR data may give repaint error.
My advice is to use the 1-week bars to gain insight into your analysis.
This code is open source under the MIT license. If you have any improvements or corrections to suggest, please send me a pull request via the github repository github.com
I hope it will help your work.Best regards!

ANN MACD (BTC)
Logic is correct.
But I prefer to say experimental because the sample set is narrow. (300 columns)
Let's start:
6 inputs : Volume Change , Bollinger Low Band chg. , Bollinger Mid Band chg., Bollinger Up Band chg. , RSI change , MACD histogram change.
1 output : Future bar change (Historical)
Training timeframe : 15 mins (Analysis TF > 4 hours (My opinion))
Learning cycles : 337
Training error: 0.009999
Input columns: 6
Output columns: 1
Excluded columns: 0
Grid
Training example rows: 301
Validating example rows: 0
Querying example rows: 0
Excluded example rows: 0
Duplicated example rows: 0
Network
Input nodes connected: 6
Hidden layer 1 nodes: 8
Hidden layer 2 nodes: 0
Hidden layer 3 nodes: 0
Output nodes: 1
Learning rate : 0.6 Momentum : 0.8
More info :
EDIT : This code is open source under the MIT License. If you have any improvements or corrections to suggest, please send me a pull request via the github repository github.com
ANN MACD Future Forecast (SPY 1D) NOTE : Deep learning was conducted in a narrow sample set for testing purposes. So this script is Experimental .
This system is based on the following article and is inspired by an external program:
hackernoon.com
None of the artificial neural networks in Tradingview work and are not based on completely correct logic. Unlike others in this system:
IMPORTANT NOTE: If the tangent activation function is used, the input data must also have tangent values (compared to the previous values of 1 bar).
Inputs were prepared according to this judgment.
1. The tangent function which is the activation function is written correctly. (The tangent function in the article: ActivationFunctionTanh (v) => (1 - exp (-2 * v)) / (1 + exp (-2 * v)))
2. Missing bias parts in the formulas were added.
3. The output function is taken from the next day (historical), so that the next bar can be predicted, which is the truth.
4.The forecast value of the next bar is subtracted from the current bar change and the market direction is determined.
5.When the future forecast and the current close are added together, the resulting data is called seed.
The seed carries data both from the present and from yesterday and from the future.
6.And this seed was subjected to the MACD method.
Thus, due to exponential averages, more importance will be given to recent developments and
The acceleration situations will show us the direction.
However, a short position should be taken for crossover and a long position for crossunder .
Because the predicted values work in reverse.Even though we use the same period (9,12,26) it is much faster!
7. There is no future code that can cause Repaint.
However, the color after closing should be checked.
The system is completely correct.
However, a very narrow sample was selected.
100 data: Tangent diffs ; volume change, bollinger bands values changes (Upband , Midband , Lowband) and LazyBear's Squeeze Momentum Indicator (SQZMOM_LB) change and the next bar data (historical) price change were put into the deep learning test.
IMPORTANT NOTE : The larger the sample set and the more effective dependent variables, the higher the hit rate of the deep learning test!
EDIT : This code is open source under the MIT License. If you have any improvements or corrections to suggest, please send me a pull request via the github repository github.com
Stay tuned. Best regards!